spark操作hive(可解决绝大部分的问题)、sparksql操作hive
目标:
想要完成使用spark在windows的idea下操作hive(对hive中的表查询等)
最终代码(java):
import org.apache.spark.sql.SparkSession;
import java.io.Serializable;
/**
* Created by Administrator on 2017/4/3.
*/
public class SQLHiveJava {
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("Java Spark Hive Example")
.master("local[*]")
.config("spark.sql.warehouse.dir","hdfs://mycluster/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate();
spark.sql("show databases").show();
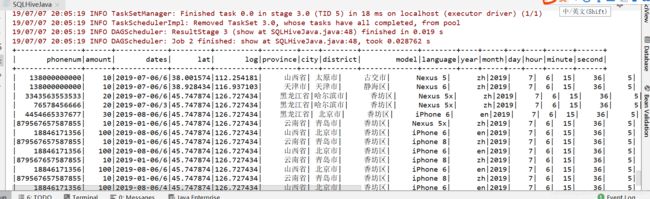
spark.sql("select count(*) from mobike.logs").show();
spark.sql("select * from mobike.logs").show();
}
}
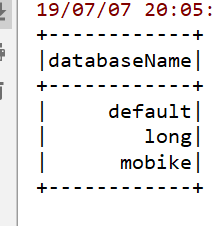
结果展示:
整个过程用了我1天多时间独立研究,出现各种各样的问题,而且网上的贴子找了很多,改了又改,最终在自己的坚持下达到结果。


官方文档:
刚开始我是照着视频做,但是视频并没有做出来,目前大部分视频都没有这部分。
于是最终选择了官方文档。
先来看下官方文档的内容:

import java.io.File ;
import java.io.Serializable ;
import java.util.ArrayList ;
import java.util.List ;
import org.apache.spark.api.java.function.MapFunction ;
import org.apache.spark.sql.Dataset ;
import org.apache.spark.sql.Encoders ;
import org.apache.spark.sql.Row ;
import org.apache.spark.sql.SparkSession ;
public static class Record 实现 Serializable {
private int key ;
私有 字符串 值;
public int getKey () {
return key ;
}
public void setKey (int key ) {
this 。key = key ;
}
public String getValue () {
return value ;
}
public void setValue (String value ) {
this 。value = value ;
}
}
// warehouseLocation指向托管数据库和表的默认位置
String warehouseLocation = new File (“spark-warehouse” )。getAbsolutePath ();
SparkSession spark = SparkSession
。builder ()
。appName (“Java Spark Hive示例” )
。config (“spark.sql.warehouse.dir” , warehouseLocation )
。enableHiveSupport ()
。getOrCreate ();
火花。sql (“CREATE TABLE IF NOT EXISTS src(key INT,value STRING)USING hive” );
火花。sql (“LOAD DATA LOCAL INPATH”examples / src / main / resources / kv1.txt'INTO TABLE src“ );
//查询以HiveQL
spark 表示。sql (“SELECT * FROM src” )。show ();
// + --- + ------- +
// | key | 值|
// + --- + ------- +
// | 238 | val_238 |
// | 86 | val_86 |
// | 311 | val_311 |
// ...
//也支持聚合查询。
火花。sql (“SELECT COUNT(*)FROM src” )。show ();
// + -------- +
// | count(1)|
// + -------- +
// | 500 |
// + -------- +
// SQL查询的结果本身就是DataFrames并支持所有正常的功能。
数据集< Row > sqlDF = spark 。sql (“SELECT键,值FROM src WHERE键<10 ORDER BY键” );
// DataFrames中的项目为Row类型,允许您按顺序访问每列。
数据集< String > stringsDS = sqlDF 。地图(
(MapFunction < 行, 字符串>) 行 - > “键:” + 行。得到(0 ) + “值:” + 行。得到(1 ),
编码器。STRING ());
stringsDS 。show ();
// + -------------------- +
// | 值|
// + -------------------- +
// |键:0,值:val_0 |
// |键:0,值:val_0 |
// |键:0,值:val_0 |
// ...
//您还可以使用DataFrames在SparkSession中创建临时视图。
List < Record > records = new ArrayList <>();
for (int key = 1 ; key < 100 ; key ++) {
Record record = new Record ();
记录。setKey (key );
记录。setValue (“val_” + key );
记录。添加(记录);
}
数据集< 行> recordsDF = 火花。createDataFrame (记录, 记录。类);
recordsDF 。createOrReplaceTempView (“records” );
//然后,查询可以将DataFrames数据与存储在Hive中的数据连接起来。
火花。sql (“SELECT * FROM records r JOIN src s on r.key = s.key” )。show ();
// + --- + ------ + --- + ------ +
// | key | 值|关键| 值|
// + --- + ------ + --- + ------ +
// | 2 | val_2 | 2 | val_2 |
// | 2 | val_2 | 2 | val_2 |
// | 4 | val_4 | 4 | val_4 |
// ...
其实官方文档已经写的很清楚的,如果经验足够,完全不用像我这样搞了一整天。
但是我当时只看了代码,文字根本没看,就算是我当时看了,估计也未必看得懂。
分析官方文档:
参照官方文档后开始写代码。
第一步要做的是导入依赖。
这个如果实在不清楚,可以根据网上的帖子来粘。
但是也正是如此,一代依赖出现问题,就会产生第一个头疼的问题。
先来看下我的pom.xml
4.0.0
groupId
lazy-spark
1.0-SNAPSHOT
2.2.1
2.11
org.apache.spark
spark-sql_${scala.version}
${spark.version}
org.apache.spark
spark-hive_${scala.version}
${spark.version}
org.apache.spark
spark-hive-thriftserver_2.11
2.2.1
provided
org.apache.hive
hive-jdbc
2.1.1
mysql
mysql-connector-java
5.1.17
先来看一下第一个绊倒大部分人的错误,也是让我很难受的错误:
Exception in thread “main” java.lang.NoSuchMethodError: scala.Predef . . .conforms()Lscala/Predef$ l e s s less lesscolon$less;
Exception in thread "main" java.lang.NoSuchMethodError: scala.Predef$.$conforms()Lscala/Predef$$less$colon$less;
at org.apache.spark.util.Utils$.getSystemProperties(Utils.scala:1722)
at org.apache.spark.SparkConf.loadFromSystemProperties(SparkConf.scala:73)
at org.apache.spark.SparkConf.(SparkConf.scala:68)
at org.apache.spark.SparkConf.(SparkConf.scala:55)
at mysql$.main(mysql.scala:9)
at mysql.main(mysql.scala)
......
Unable to instantiate SparkSession with Hive support because Hive classes are not found.
Exception in thread "main" java.lang.IllegalArgumentException: Unable to instantiate SparkSession with Hive support because Hive classes are not found.
at org.apache.spark.sql.SparkSession$Builder.enableHiveSupport(SparkSession.scala:845)
at com.lcc.spark.structed.streaming.KafkaDemo1.main(KafkaDemo1.java:33)
这个问题的主要原因就是一个:
那就是spark和scala的版本不统一。
举个例子:
org.apache.spark
spark-hive-thriftserver_2.11
2.2.1
provided
注意:2.11是scala版本。2.2.1就是spark版本
不是说这两个版本必须和我一致。但是你要做的是,其他的依赖都要使用这个版本。否则就会报错。如果不放心,可以直接粘贴我上面的。
参考链接:
https://blog.csdn.net/huoliangwu/article/details/86316054
- 还有一种说法,就是另一个错误导致的这个错误,那就是,如果你的代码平时运行的时候会出现hadoop的错误,类似这样等
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:356)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:371)
at org.apache.hadoop.util.Shell.(Shell.java:364)
at org.apache.hadoop.util.StringUtils.(StringUtils.java:80)
at org.apache.hadoop.security.SecurityUtil.getAuthenticationMethod(SecurityUtil.java:611)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:272)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260)
at
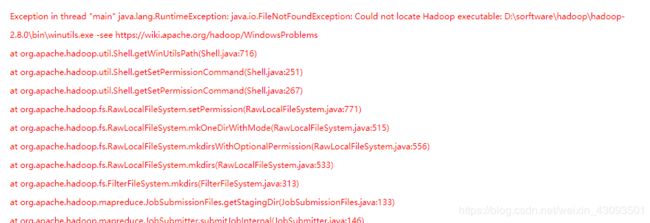
这个问题,在我找帖子的时候有人提到过,原文是一定要把这个解决,否则也会报错,解决方法是配置windows的hadoop环境变量。
解决的帖子贴在下面:
https://blog.csdn.net/csdn_fzs/article/details/7898558
https://www.e-learn.cn/content/qita/707774
拷贝集群上的配置文件:
第二个问题就很容易解决,你要把hadoop集群上的以下配置文件拷贝到idea中

warehouseLocation是什么、spark-warehouse是什么、spark-warehouse应该些什么
这个问题其实也困扰了我特别就,直到结果出来以后才确认。
先来看我写的
hdfs://mycluster/user/hive/warehouse
其中mycluster是我高可用集群的名字,这个要写对,要和core-site.xml里写的一致,不在多说了。
那么后面的部分其实也很好理解。如果你的hive是默认配置的话,和我写的一样就好。我们都是到存在hive中的数据,最终在hdfs目录上,那么后面的其实就是hive数据在你hdfs的目录
查不到hive的元数据。
如果以上错误都解决了
我建议你在代码中使用如下代码进行测试。
spark.sql("show databases").show();
为什么呢,因为这个一定会有个结果,而不会产生我们接下来的问题
Table or view not found: mobike.logs; line 1 pos 21;
'Aggregate [unresolvedalias(count(1), None)]
± 'UnresolvedRelation mobike.logs
Exception in thread "main" org.apache.spark.sql.AnalysisException: Table or view not found: `mob`.`lo`; line 1 pos 21;
'Aggregate [unresolvedalias(count(1), None)]
+- 'UnresolvedRelation `mob`.`lo`
org.apache.spark.sql.AnalysisException: Table or view not found: traintext.train; line 1 pos 14;
org.apache.spark.sql.AnalysisException: Table or view not found: traintext.train; line 1 pos 14;
'Project [*]
± 'UnresolvedRelation traintext.train
 这个错误就有意思了,这是我入坑的问题,也是结果出来后才明白的。
这个错误就有意思了,这是我入坑的问题,也是结果出来后才明白的。
我看的视频到这里就不讲了,他选择另一种方式来处理hive,但不符合我的要求。
网上很多贴子对这个问题都没有讲清楚,当然还是有很多负责人的帖子最终让我找到了答案。
首先要声明的是,如果你按照我的依赖来写是不会有这个问题的,但是会报其他错。
回到刚才,我建议大家用这行代码调试
spark.sql("show databases").show();
因为这行代码一定会给你个结果,可惜结果并不是我们想的样子。
我们看错误结果:
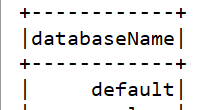
大概就这样子。
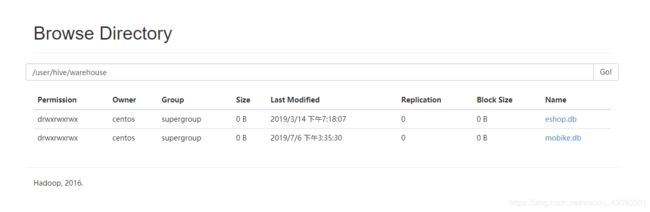
也就是说,我们只能查到一个默认库,查不到hive中其他自己建的库。
spark只能查到hive的default库、spark查询不到hive中建的表和库
知识点来了,看清楚!!!
这些官方文档都写过了,我们再来分析一下:
!!!
如果没有部署好的hive,spark确实是会使用内置的hive,但是spark会将所有的元信息都放到spark_home/bin 目录下,也就是为什么配置了spark.sql.warehouse.dir 却不起作用的原因。而且,就算部署了hive,也需要让spark识别hive,否则spark,还是会使用spark默认的hive
!!!
惊不惊喜。spark还有自己的内置hive,如果没有正确的连接到自己的hive,那么使用的是spark自己的内置库。所以官方文档的代码才会那样写。
那么怎么让spark连接到自己hive呢。
spark连接自己的hive
首先,要连接hive一定要有这=些依赖,缺一不可
org.apache.spark
spark-hive_${scala.version}
${spark.version}
org.apache.spark
spark-hive-thriftserver_2.11
2.2.1
provided
org.apache.hive
hive-jdbc
2.1.1
mysql
mysql-connector-java
5.1.17
thriftserver:就是用来连接连接hive元数据的服务
mysql con……:因为我的hive元数据存在mysql所以要有这个驱动。
如果这些都做好了,那么会有接下来的问题。
用hive --service metastore来启动hive
简单一个hive然后进入shell是不行的。要通过元数据方式启动。

最后一个问题来了
Exception in thread “main” java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient

所有都做好以后恭喜你最后一个问题,还是元数据的问题,这里就将一个,也是最容易被忽略的。
那就是,在我们的hive-site.xml中其实少了些东西。

hive.metastore.uris
thrift://hive服务端ip:9083
hive服务端指的是你hive的所在节点的ip地址或主机名。
到此为止所有的都解决完了,再来看下结果:
格式不怎么好看,希望能帮助大家,如果你还有问题可以联系我
邮箱:[email protected]