机器学习:线性判别分析(LDA)代码实现
机器学习:线性判别分析(LDA)代码实现
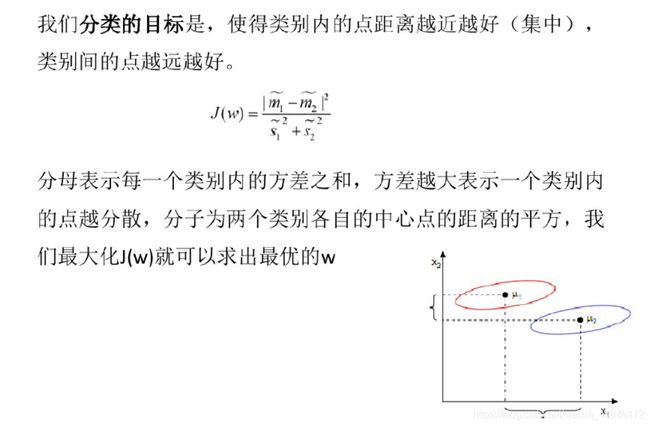
相关知识






代码实现
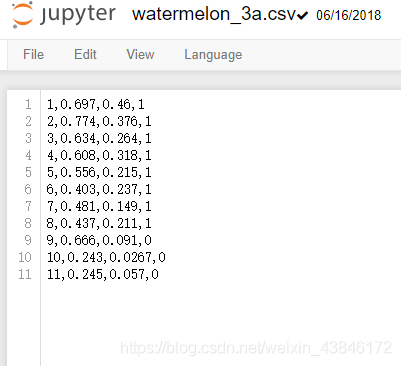
使用的数据集 周志华老师<机器学习>书上数据集3a(第一列序号,第二列密度,第三列含糖量,第四列是否为好瓜)
通过三种方法:第一种方法调库,二三种手写
#!/usr/bin/env python
# coding: utf-8
# In[8]:
import numpy as np
'''
get the projective point(2D) of a point to a line
@param point: the coordinate of the point form as [a,b]
@param line: the line parameters form as [k, t] which means y = k*x + t
@return: the coordinate of the projective point
'''
def GetProjectivePoint_2D(point, line):#点x,y坐标。线斜率,截距。返回点投影到线上的点的坐标
a = point[0]
b = point[1]
k = line[0]
t = line[1]
if k == 0:
return [a, t]
elif k == np.inf:
return [0, b]
x = (a+k*b-k*t) / (k*k+1)
y = k*x + t
return [x, y]
from _operator import inv
#求逆矩阵
import numpy as np
import matplotlib.pyplot as plt
data_file = open('watermelon_3a.csv')
dataset = np.loadtxt(data_file, delimiter=",")
X = dataset[:,1:3]
y = dataset[:,3]
# draw scatter diagram to show the raw data
f1 = plt.figure(1)
plt.title('watermelon_3a')
plt.xlabel('density')
plt.ylabel('ratio_sugar')
plt.scatter(X[y == 0,0], X[y == 0,1], marker = 'o', color = 'k', s=100, label = 'bad')
plt.scatter(X[y == 1,0], X[y == 1,1], marker = 'o', color = 'g', s=100, label = 'good')
plt.legend(loc = 'upper right')
plt.show()
from sklearn import model_selection
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import metrics
import matplotlib.pyplot as plt
# generalization of train and test set
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.5, random_state=0)
# model fitting
lda_model = LinearDiscriminantAnalysis(solver='lsqr', shrinkage=None).fit(X_train, y_train)
# model validation
y_pred = lda_model.predict(X_test)
# summarize the fit of the model
print(metrics.confusion_matrix(y_test, y_pred))
print(metrics.classification_report(y_test, y_pred))
# draw the classfier decision boundary
f2 = plt.figure(2)
h = 0.001
# x0_min, x0_max = X[:, 0].min()-0.1, X[:, 0].max()+0.1
# x1_min, x1_max = X[:, 1].min()-0.1, X[:, 1].max()+0.1
x0, x1 = np.meshgrid(np.arange(-1, 1, h),
np.arange(-1, 1, h))
# x0, x1 = np.meshgrid(np.arange(x0_min, x0_max, h),
# np.arange(x1_min, x1_max, h))
z = lda_model.predict(np.c_[x0.ravel(), x1.ravel()])
# Put the result into a color plot
z = z.reshape(x0.shape)
plt.contourf(x0, x1, z)
# Plot also the training pointsplt.title('watermelon_3a')
plt.title('watermelon_3a')
plt.xlabel('density')
plt.ylabel('ratio_sugar')
plt.scatter(X[y == 0,0], X[y == 0,1], marker = 'o', color = 'k', s=100, label = 'bad')
plt.scatter(X[y == 1,0], X[y == 1,1], marker = 'o', color = 'g', s=100, label = 'good')
plt.show()
u = []
for i in range(2): # two class
u.append(np.mean(X[y==i], axis=0)) # column mean
# 2-nd. computing the within-class scatter matrix, refer on book (3.33)
m,n = np.shape(X)
Sw = np.zeros((n,n))
for i in range(m):
x_tmp = X[i].reshape(n,1) # row -> cloumn vector
if y[i] == 0: u_tmp = u[0].reshape(n,1)
if y[i] == 1: u_tmp = u[1].reshape(n,1)
Sw += np.dot( x_tmp - u_tmp, (x_tmp - u_tmp).T )
Sw = np.mat(Sw)
U, sigma, V= np.linalg.svd(Sw)
Sw_inv = V.T * np.linalg.inv(np.diag(sigma)) * U.T
# 3-th. computing the parameter w, refer on book (3.39)
w = np.dot( Sw_inv, (u[0] - u[1]).reshape(n,1) ) # here we use a**-1 to get the inverse of a ndarray
print(w)
f3 = plt.figure(3)
plt.xlim( -0.2, 1 )
plt.ylim( -0.5, 0.7 )
p0_x0 = -X[:, 0].max()
p0_x1 = ( w[1,0] / w[0,0] ) * p0_x0
p1_x0 = X[:, 0].max()
p1_x1 = ( w[1,0] / w[0,0] ) * p1_x0
plt.title('watermelon_3a - LDA')
plt.xlabel('density')
plt.ylabel('ratio_sugar')
plt.scatter(X[y == 0,0], X[y == 0,1], marker = 'o', color = 'k', s=10, label = 'bad')
plt.scatter(X[y == 1,0], X[y == 1,1], marker = 'o', color = 'g', s=10, label = 'good')
plt.legend(loc = 'upper right')
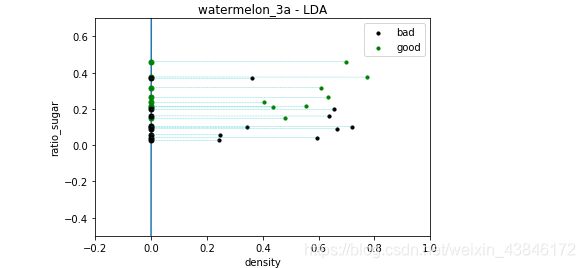
plt.plot([p0_x0, p1_x0], [p0_x1, p1_x1])
# draw projective point on the line
m,n = np.shape(X)
for i in range(m):
x_p = GetProjectivePoint_2D( [X[i,0], X[i,1]], [w[1,0] / w[0,0] , 0] )
if y[i] == 0:
plt.plot(x_p[0], x_p[1], 'ko', markersize = 5)
if y[i] == 1:
plt.plot(x_p[0], x_p[1], 'go', markersize = 5)
plt.plot([ x_p[0], X[i,0]], [x_p[1], X[i,1] ], 'c--', linewidth = 0.3)
plt.show()
X = np.delete(X, 14, 0)
y = np.delete(y, 14, 0)
u = []
for i in range(2): # two class
u.append(np.mean(X[y==i], axis=0)) # column mean
# 2-nd. computing the within-class scatter matrix, refer on book (3.33)
m,n = np.shape(X)
Sw = np.zeros((n,n))
for i in range(m):
x_tmp = X[i].reshape(n,1) # row -> cloumn vector
if y[i] == 0: u_tmp = u[0].reshape(n,1)
if y[i] == 1: u_tmp = u[1].reshape(n,1)
Sw += np.dot( x_tmp - u_tmp, (x_tmp - u_tmp).T )
Sw = np.mat(Sw)
U, sigma, V= np.linalg.svd(Sw)
Sw_inv = V.T * np.linalg.inv(np.diag(sigma)) * U.T
# 3-th. computing the parameter w, refer on book (3.39)
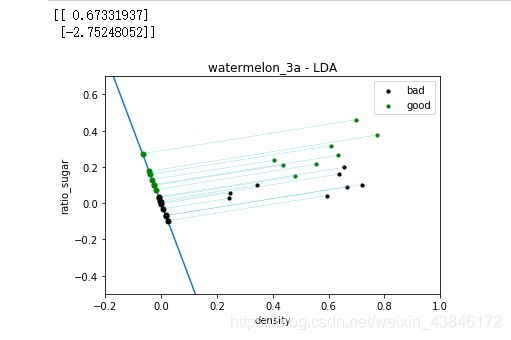
w = np.dot( Sw_inv, (u[0] - u[1]).reshape(n,1) ) # here we use a**-1 to get the inverse of a ndarray
print(w)
# 4-th draw the LDA line in scatter figure
# f2 = plt.figure(2)
f4 = plt.figure(4)
plt.xlim( -0.2, 1 )
plt.ylim( -0.5, 0.7 )
p0_x0 = -X[:, 0].max()
p0_x1 = ( w[1,0] / w[0,0] ) * p0_x0
p1_x0 = X[:, 0].max()
p1_x1 = ( w[1,0] / w[0,0] ) * p1_x0
plt.title('watermelon_3a - LDA')
plt.xlabel('density')
plt.ylabel('ratio_sugar')
plt.scatter(X[y == 0,0], X[y == 0,1], marker = 'o', color = 'k', s=10, label = 'bad')
plt.scatter(X[y == 1,0], X[y == 1,1], marker = 'o', color = 'g', s=10, label = 'good')
plt.legend(loc = 'upper right')
plt.plot([p0_x0, p1_x0], [p0_x1, p1_x1])
# draw projective point on the line
m,n = np.shape(X)
for i in range(m):
x_p = GetProjectivePoint_2D( [X[i,0], X[i,1]], [w[1,0] / w[0,0] , 0] )
if y[i] == 0:
plt.plot(x_p[0], x_p[1], 'ko', markersize = 5)
if y[i] == 1:
plt.plot(x_p[0], x_p[1], 'go', markersize = 5)
plt.plot([ x_p[0], X[i,0]], [x_p[1], X[i,1] ], 'c--', linewidth = 0.3)
plt.show()
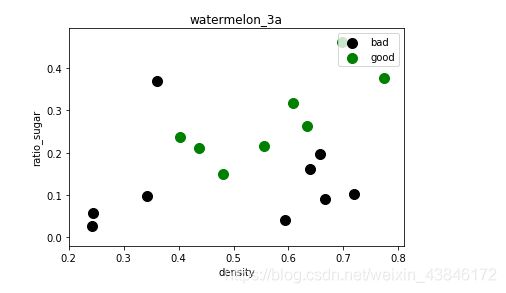
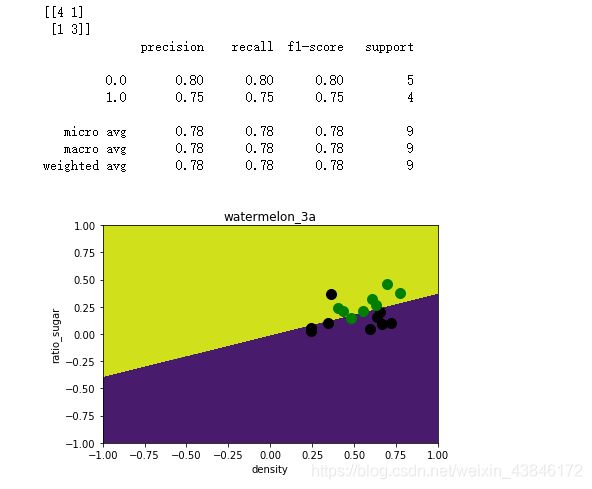
运行结果
数据集散点图
三种方法的训练结果
如有侵权,联系删除: [email protected]