论文阅读之《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (arxiv, 21 Nov, 2016)这篇文章将对抗学习用于基于单幅图像的高分辨重建。基于深度学习的高分辨率图像重建已经取得了很好的效果,其方法是通过一系列低分辨率图像和与之对应的高分辨率图像作为训练数据,学习一个从低分辨率图像到高分辨率图像的映射函数,这个函数通过卷积神经网络来表示。
本文提出了一种利用生成对抗网络(GAN)对低分辨率单一图像进行超分辨率(super-resolution)的网络结构,作为GAN的一种重要应用,很值得去学习研究。阅读原文点这里。
传统的方法一般处理的是较小的放大倍数,当图像的放大倍数在4以上时,很容易使得到的结果显得过于平滑,而缺少一些细节上的真实感。这是因为传统的方法使用的代价函数一般是最小均方差(MSE),即

该代价函数使重建结果有较高的信噪比,但是缺少了高频信息,出现过度平滑的纹理。该文章中的方法提出的方法称为SRGAN, 它认为,应当使重建的高分辨率图像与真实的高分辨率图像无论是低层次的像素值上,还是高层次的抽象特征上,和整体概念和风格上,都应当接近。整体概念和风格如何来评估呢?可以使用一个判别器,判断一副高分辨率图像是由算法生成的还是真实的。如果一个判别器无法区分出来,那么由算法生成的图像就达到了以假乱真的效果。
因此,该文章将代价函数改进为

第一部分是基于内容的代价函数,第二部分是基于对抗学习的代价函数。基于内容的代价函数除了上述像素空间的最小均方差以外,又包含了一个基于特征空间的最小均方差,该特征是利用VGG网络提取的图像高层次特征:

对抗学习的代价函数是基于判别器输出的概率:

其中是一个图像属于真实的高分辨率图像的概率。是重建的高分辨率图像。
这篇文章用了深度残差网络同时用到GANs的概念构建的超分辨神经网络模型。主要贡献点:
1.构建由MSE优化的16blocks残差网络(SRResNet)。
2.SRGAN网络由GAN构建的网络。
3.MOS测试在3个数据库上SRGAN都不错的效果。
GAN的感知损失函数,除了GAN损失函数外还有基于内容的损失函数。内容的损失函数有两种,一种是MSE,还有一种是对VGG19的层卷积的结果求方差的损失函数。
Abstract
尽管我们已经利用更快更深的卷积神经网络(CNN)突破了单一图像超分辨率的速度和精度,但有一个中心问题仍没有完美解决:当对放大很多倍的图像进行超分辨率时,我们该如何更好的恢复图像的纹理细节?
以最优化思想为基础的超分辨率方法主要受到目标函数的驱使,最近的一些相关项目均以最小化平均方差重建误差为目标,这样得到的结果有很大的信噪比,但是往往图像会缺失高频细节并且视觉效果很差。
因此,作者提出了SRGAN,这是第一个对放大四倍自然图像做超分辨率的框架。为了实现这个框架,作者提出了由adversarial loss和content loss组成的perceputal loss function。adversarial loss由判别器生成,使我们生成的图像更加接近自然图像。content loss由图像的视觉相似性生成,而不是像素空间的相似性。并且本文的深度残差网络可以从深度降采样的图像恢复逼真的纹理。作者采用mean-opinion-score(MOS)测试作为图像效果的评判,最后的测试结果表明采用SRGAN获得的图像的MOS值比采用其他顶级的方法获得的图像的MOS值更加接近原始的高分辨图像。
Introduction
由低分辨率(LR)图像预测它的高分辨率(HR)图像这一高难度任务被称为超分辨率super-resolution(SR).SR获得了来自计算机视觉研究界的大量关注并有广泛的应用.

超分辨率问题的病态性质尤其表现在较高的放大因子上,以至重构的超分辨率图像的纹理细节通常缺失。目前被大多人采用的以最优化目标函数为基础的监督SR算法存在缺失图像高频纹理细节的问题,使生成的图像很模糊。这种算法大多以均方误差(MSE)为目标函数进行优化,在减小均方误差的同时又可以增大峰值信噪比(PSNR)。但是MSE和PSNR值的高低并不能很好的表示视觉效果的好坏。正如在下面图片表现出的,PSNR最高并不能反映SR效果最好。
从左到右:(双三次)立方体插值,优化MSE的深度残差网络,深度残差生成对抗网络优化人类感知更为敏感的损失,原始高分辨率图像.对应的PSNR和SSIM(结构相似性)值在括号中显示.
因此,作者提出以深度残差网络(ResNet)作为生成器的生成对抗网络,与以往不同的是,ResNet的优化目标不止MSE,还有VGG网络与判别器构成的perceptual loss.
Contribution
GANs为生成看起来合理的高感知质量的自然图像提供了一个强大的框架.GAN过程促使重建接近有极大可能包含实感图像的搜索空间并由此接近自然图像如图3所示.本文中,我们将介绍第一个用GANs概念的very deep ResNet结构为实感SISR构成一个感知损失函数.主要贡献如下:
- 建立了以PSNR和结构相似性(structural similarty,SSIM)为评判标准的SRResNet来对放大4倍的图像做超分辨率。(衡量标准为:PSNR 和 structure similarity (SSIM)。用16块深度ResNet来优化MSE.)
- 提出的SRGAN以perceptual loss为优化目标,我们用VGG网络特征图谱的损失函数取代了以MSE为基础的content loss
- 我们对生成的图片进行MOS测试。
Method
在训练SRGAN网络的过程中需要提供HR图片,作者首先对HR图片进行降采样得到LR图片,然后将LR图片输入,训练生成器,使之生成对应的HR图片。训练生成器的过程与训练前馈CNN一样,都是对网络参数θGθG进行优化,如下所示:

需要注意的是在这里用的是perceptual loss—lSRlSR
进一步,作者定义了判别器DθGDθG,如同跟Following Goodfellow提出的GAN网络一样,生成器和判别器交替优化下面这个式子:

网络结构如图所示

感知损失函数(perceptual loss function)
我们 的感知损失函数 L_sr 的定义对我们的生成网络的性能至关重要.因为通常 L_sr 是基于MSE建模的.通过对content loss和adversarial loss分别赋予权重,得到下式:

下面将介绍content loss和 adversarial loss:
Content loss
大部分用来做图像超分辨率的算法都用MSE作为损失函数来进行优化,可以得到很高的信噪比,但是这样的方式产生的图像存在高频细节缺失的问题。

因此,作者定义了以预训练19层VGG网络的ReLU激活层为基础的VGG loss:

ϕi,jϕi,j表示VGG19网络当中第i层maxpooling层后的第j个卷积层得到的特征图谱。
Wi,jWi,j和Hi,j
分别表示VGG网络中特征图谱的维度。
对抗损失 adversarial loss
作者将GAN中生成器对perpetual loss的影响通过adversarial loss体现出来。这一部分损失函数使我们的网络通过“欺骗”判别器从而偏向生成输出更接近自然图像的输出。

这里,DθG(GθG(ILR))DθG(GθG(ILR))表示的是判别器将生成器生成的图像GθG(ILR)GθG(ILR)判定为自然图像的概率。
Experiment 实验
数据及相似性测量
我们在3个被广泛试用的基准数据集 Set5,Set14,BSD100,上进行实验.所有实验在低分辨率和高分辨率图像间的4倍系数上进行.这相当于在图像像素上降低16倍.为了对比公正性,所有的PSNR[dB]和SSIM测量在enter-cropped (中心剪裁)的y 通道上计算,在每条边界上移除4像素宽的条带,图像用 daala package.https://github.com/xiph/daala(commit: 8d03668)
超分辨率图像相关算法包括最近邻,双三次插值,SRCNN和SelfExSR.
Huang等人的在线材料 https://github.com/jbhuang0604/SelfExSR
Kim等人的 DRCN http://cv.snu.ac.kr/research/DRCN/
结果由SRResNet得到,SRGAN变量可以在线获得
:https://twitter.box.com/s/lcue6vlrd01ljkdtdkhmfvk7vtjhetog
Statistical tests were performed as paired two-sided Wilcoxon signed-rank tests and significance determined at p < 0.05.
读者可能会对Git Hub上独立研发的基于GAn的解决方案感兴趣 https://github.com/david-gpu/srez但是.只提供了一组有限的脸部实验结果.
训练细节和参数
所有网络都是在NVIDIA Tesla M40 GPU上训练的,用一组350000张图像的随机样本,图像来自ImageNet 数据集.这些图像与测试图像不同.我们通过下采样HR图像来获得LR图像,用下采样系数r=4的bicubic kernel.对每个mini-batch,剪裁16个不同训练图像的96*96的子图(随机).注意,我们可以把生成器模型应用到任意大小的图像上,因为它是全卷积的.我们用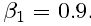 的Adam来最优化,用学习率=0.0001和用10^6次更新迭代来训练SRResNet networks .当训练真实的GAN时,用训练好的基于MSE的SRResNET network 作为生成的的初始化,从而避免出现局部最优.所有的SRGAN变量经过10^5次更新迭代训练(学习率=0.0001),另外进行了学习率=0.00001,迭代次数为10^5的训练.我们交替更新生成器和判别器网络,相当于Goodfellow等人用到的k=1.我们的生成器网络有16个相同的残差块(B=16).在测试时,我们我们turn batch-normalization off 来获得一个确定只依赖于输入的输出. 实现基于 Theano and Lasagne.
的Adam来最优化,用学习率=0.0001和用10^6次更新迭代来训练SRResNet networks .当训练真实的GAN时,用训练好的基于MSE的SRResNET network 作为生成的的初始化,从而避免出现局部最优.所有的SRGAN变量经过10^5次更新迭代训练(学习率=0.0001),另外进行了学习率=0.00001,迭代次数为10^5的训练.我们交替更新生成器和判别器网络,相当于Goodfellow等人用到的k=1.我们的生成器网络有16个相同的残差块(B=16).在测试时,我们我们turn batch-normalization off 来获得一个确定只依赖于输入的输出. 实现基于 Theano and Lasagne.
平均意见得分(MOS)测试
我们进行了MOS测试来量化不同方法重构感知上令人信服的图像的能力.具体来说,我们要求26个评分者对超分辨率图像打分,分数为从1(bad quality)到5(excellent quality)的整数.评分者对Set5 ,Set14 ,BSD100数据集上的每张图像打12个版本的分数(以下12个算法产生的图像):
nearest neighbor (NN),bicubic, SRCNN , SelfExSR , DRCN, ESPCN, SRResNet-MSE, SRRes Net-VGG22(not rated on BSD100), SRGAN-MSE, SRGAN-VGG22, SRGAN-VGG54 and the original HR image.
因此每个评分者评价了1128个例子(19张图片的12个版本+100张图片的9个版本),这些例子以随机的方式呈现.
评分者在来自BSD300训练集的20个图像的NN(评分1)和HR(5)版本上校准。在初步研究中,我们通过将一个方法的图像放入两次以到一个更大的测试集,来评估来自BSD100的10张图像的子集上的26个评分者的校准过程和重测可靠性.我们发现可靠性良好,并且相同图像的评分之间没有显著的偏差.如图5所示:

这里表现的人眼对于图像效果的评价
MOS测试的实验结果总结在表1,表2和图5中。


final networks
.结论
我们描绘了一个深度残差网络SRResNet,用PSNR测量时在公共基准数据集上取得了顶尖的效果.我们强调了这种专注于PSNR值的 图像超分辨率的一些局限性并介绍了SRGAN.SRGAN通过训练一个GAN给content loss funtion 增加了一个adversarial loss.用扩展的MOS测试,我们证实对于大的放大因子(4*)SRGAN重构比目前顶尖的参考方法获得的重构更逼真.