使用CNN对cifar-10数据集进行读取和分类
WEEK2报告
数据来源
cifar-10数据集说明和下载地址
数据集展示
整体结构:5000万张训练集,1000张测试集

单个图片size:32323

CNN网络结构
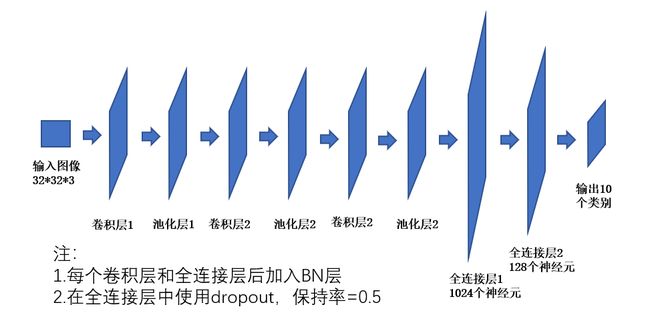
分类结果
测试集精度:0.78
read data_batch_1
has trained 1000 datas, accuracy = 0.21
has trained 2000 datas, accuracy = 0.27
has trained 3000 datas, accuracy = 0.27
has trained 4000 datas, accuracy = 0.37
has trained 5000 datas, accuracy = 0.34
has trained 6000 datas, accuracy = 0.4
has trained 7000 datas, accuracy = 0.38
has trained 8000 datas, accuracy = 0.37
has trained 9000 datas, accuracy = 0.46
has trained 10000 datas, accuracy = 0.47
read data_batch_2
has trained 11000 datas, accuracy = 0.46
has trained 12000 datas, accuracy = 0.44
has trained 13000 datas, accuracy = 0.44
has trained 14000 datas, accuracy = 0.5
has trained 15000 datas, accuracy = 0.49
has trained 16000 datas, accuracy = 0.45
has trained 17000 datas, accuracy = 0.41
has trained 18000 datas, accuracy = 0.47
has trained 19000 datas, accuracy = 0.64
has trained 20000 datas, accuracy = 0.46
read data_batch_3
has trained 21000 datas, accuracy = 0.53
has trained 22000 datas, accuracy = 0.63
has trained 23000 datas, accuracy = 0.54
has trained 24000 datas, accuracy = 0.54
has trained 25000 datas, accuracy = 0.51
has trained 26000 datas, accuracy = 0.6
has trained 27000 datas, accuracy = 0.54
has trained 28000 datas, accuracy = 0.57
has trained 29000 datas, accuracy = 0.52
has trained 30000 datas, accuracy = 0.57
read data_batch_4
has trained 31000 datas, accuracy = 0.5
has trained 32000 datas, accuracy = 0.56
has trained 33000 datas, accuracy = 0.59
has trained 34000 datas, accuracy = 0.54
has trained 35000 datas, accuracy = 0.57
has trained 36000 datas, accuracy = 0.59
has trained 37000 datas, accuracy = 0.59
has trained 38000 datas, accuracy = 0.59
has trained 39000 datas, accuracy = 0.54
has trained 40000 datas, accuracy = 0.69
read data_batch_5
has trained 41000 datas, accuracy = 0.62
has trained 42000 datas, accuracy = 0.57
has trained 43000 datas, accuracy = 0.58
has trained 44000 datas, accuracy = 0.53
has trained 45000 datas, accuracy = 0.62
has trained 46000 datas, accuracy = 0.58
has trained 47000 datas, accuracy = 0.53
has trained 48000 datas, accuracy = 0.66
has trained 49000 datas, accuracy = 0.54
has trained 50000 datas, accuracy = 0.67
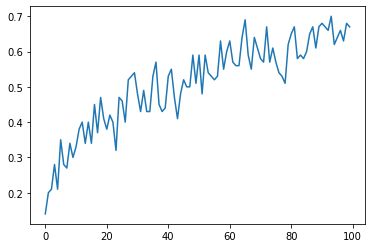
training complicated!
test data accuracy = 0.78
runing time: 387.4479079246521
文件结构
代码
功能:
读取,格式化数据集
# -*- coding: utf-8 -*-
"""
Created on Sat Jul 27 16:29:48 2019
function:
读取数据集数据
@author: lhy
"""
import numpy as np
import pickle
import os
class cifar_reader():
#初始化
def __init__(self,data_folder,onehot = True):
self.data_folder = data_folder
self.onehot = onehot
self.batch_index = 1
self.read_next_batch= True
self.data_label_train = None
self.data_label_test = None
self.mini_batch_index = 0
#输入文件目录
#输出unpickle的文件
def unpickle(self,file):
with open(file, 'rb') as fo:
dict = pickle.load(fo,encoding='bytes')
return dict
#输入data和labels合在一起的list,labels range(0-9)
#输出onhot编码后的labels和reshape以后的data
def _encode(self,minibatch,onehot):
rdata = []
rlabels = []
if onehot:
for d,l in minibatch:
#rdata.append(np.reshape(d,[32,32,3]))
####????????????????????????????????????????????????????????????
rdata.append(np.reshape(np.reshape(d, [3, 1024]).T, [32, 32, 3]))
rlabels.append(np.eye(10)[l])
else:
pass
return rdata,rlabels
#输入batch_size
#输出data_batch
def next_trian_batch(self,batch_size=100):
#如果需要读取下一个batch
if self.read_next_batch:
f_path = os.path.join(self.data_folder,"data_batch_%s" %(self.batch_index))
print("read data_batch_%s"%(self.batch_index))
dict_train_data = self.unpickle(f_path)
self.data_label_train = list(zip(dict_train_data[b'data'],dict_train_data[b'labels']))
np.random.shuffle(self.data_label_train)
self.read_next_batch = False
self.batch_index += 1
#划分mini——batch
if self.mini_batch_index < len(self.data_label_train)//batch_size:
mini_batch = self.data_label_train[self.mini_batch_index*batch_size:(self.mini_batch_index+1)*batch_size]
self.mini_batch_index +=1
rdata,rlabel = self._encode(mini_batch,self.onehot)
else:
self.read_next_batch = True
self.mini_batch_index = 0
return self.next_trian_batch(batch_size)
return rdata,rlabel
##输入test_size
##输出test_data & labels
def next_test_batch(self,batch_size = 100):
if self.data_label_test is None:
f_path = os.path.join(self.data_folder,"test_batch")
dict_test = self.unpickle(f_path)
self.data_label_test = list(zip(dict_test[b'data'],dict_test[b'labels']))
##!!!手法巧妙
np.random.shuffle(self.data_label_test)
return self._encode(self.data_label_test[0:batch_size],self.onehot)
功能:
使用CNN进行训练
# -*- coding: utf-8 -*-
"""
Created on Sat Jul 27 20:57:47 2019
@author: lhy
"""
import tensorflow as tf
import time
import reader_lhy
import matplotlib.pyplot as plt
time_start = time.time()
batch_size = 100
test_size = 5000
capacity = 50000
show_interval = 5
##定义placeholder
xs = tf.placeholder(dtype=tf.float32,shape=[None,32,32,3]) #shape?
ys = tf.placeholder(dtype=tf.float32,shape=[None,10])
keep_prob = tf.placeholder(tf.float32)
##构建网络
#layer1----out 15*15*64
w1 = tf.Variable(tf.truncated_normal([3,3,3,64],dtype=tf.float32,stddev=1e-1))
conv1 = tf.nn.conv2d(xs,w1,strides = [1,1,1,1], padding = 'VALID')
bn1 = tf.layers.batch_normalization(conv1,training=True)
relu1 = tf.nn.relu(bn1)
pool1 = tf.nn.max_pool(relu1,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID')
#layer2-----out 6*6*128
w2 = tf.Variable(tf.truncated_normal([3,3,64,128],dtype=tf.float32,stddev=1e-1))
conv2 = tf.nn.conv2d(pool1,w2,strides = [1,1,1,1], padding = 'SAME')
bn2 = tf.layers.batch_normalization(conv2,training=True)
relu2 = tf.nn.relu(bn2)
pool2 = tf.nn.max_pool(relu2,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID')
#layer3-----out 2*2*256
w3 = tf.Variable(tf.truncated_normal([3,3,128,256],dtype=tf.float32,stddev=1e-1))
conv3 = tf.nn.conv2d(pool2,w3,strides = [1,1,1,1], padding = 'SAME')
bn3 = tf.layers.batch_normalization(conv3,training=True)
relu3 = tf.nn.relu(bn3)
pool3 = tf.nn.max_pool(relu3,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID')
#fc1
flatten_vec = tf.reshape(pool3,[-1,2*2*256])
w_fc1 = tf.Variable(tf.truncated_normal([1024,1024],dtype=tf.float32,stddev=1e-1))
b_fc1 = tf.Variable(tf.truncated_normal([1024],dtype=tf.float32,stddev=1e-1))
bn_fc1 = tf.layers.batch_normalization(tf.matmul(flatten_vec,w_fc1),training=True)
fc1_out = tf.nn.dropout(tf.nn.relu(bn_fc1),keep_prob)
#fc2
w_fc2 = tf.Variable(tf.truncated_normal([1024,128],dtype=tf.float32,stddev=1e-1))
b_fc2 = tf.Variable(tf.truncated_normal([128],dtype=tf.float32,stddev=1e-1))
bn_fc2 = tf.layers.batch_normalization(tf.matmul(fc1_out,w_fc2),training=True)
fc2_out = tf.nn.dropout(tf.nn.relu(bn_fc2),keep_prob)
#fc2
w_fc3 = tf.Variable(tf.truncated_normal([128,10],dtype=tf.float32,stddev=1e-1))
b_fc3 = tf.Variable(tf.truncated_normal([10],dtype=tf.float32,stddev=1e-1))
prediction = tf.matmul(fc2_out,w_fc3)+b_fc3
##定义loss和train
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction,labels=ys))
train = tf.train.AdamOptimizer(0.01).minimize(loss)
##定义精确度
correct = tf.equal(tf.arg_max(prediction,1),tf.arg_max(ys,1))
accuracy = tf.reduce_mean(tf.cast(correct,tf.float32))
##初始化
init = tf.initialize_all_variables()
reader = reader_lhy.cifar_reader(data_folder='cifar-10-batches-py')
##训练
acc_list = []
with tf.Session() as sess:
sess.run(init)
step = 1
while step*batch_size<capacity:
step += 1
train_data,train_labels = reader.next_trian_batch(batch_size=batch_size)
tra,acc=sess.run([train,accuracy],feed_dict={xs:train_data,ys:train_labels,keep_prob:0.5})
if step % show_interval == 0:
#acc = sess.run(accuracy,feed_dict={xs:train_data,ys:train_labels,keep_prob:0.5})
print("has trained "+str(step*batch_size) + " datas, accuracy = " + str(acc))
acc_list.append(acc)
test_data,test_labels = reader.next_test_batch(batch_size=test_size)
print("training complicated!")
test_acc = sess.run(accuracy,feed_dict={xs:train_data,ys:train_labels,keep_prob:1})
print("test data accuracy = " + str(test_acc))
#精准度图像
plt.plot(acc_list)
time_end = time.time()
print('runing time: ',time_end-time_start)
疑问:
BN层的影响为什么会这么大
数据集的shape有点迷
conv层same padding为什么这么重要