Sqlite3知识总结一(基础知识及相关要点)
数据库的知识点有不少:基本语法、数据类型,数据库的创建、附加、分离等,核心操作还是表的增、删、改、查四个部分。表的创建和删除分别使用create和drop命令,比较简单,不做讨论,下面只探讨数据记录的增删改查这四个部分。
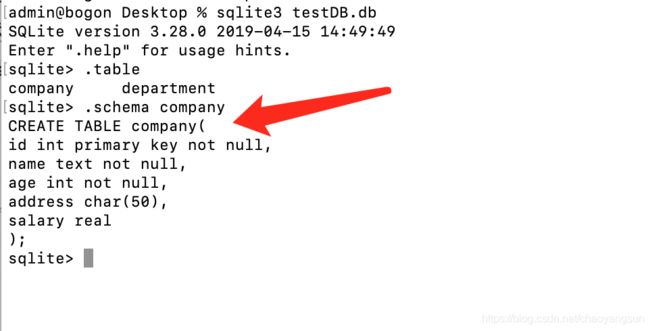
假定已经创建了数据库testDB.db和表格company,命令行中可以通过.schema查看表的基本信息:
增
SQLite 的 INSERT INTO 语句用于向数据库的某个表中添加新的数据行。
INSERT INTO 语句有两种基本语法,如下所示:
INSERT INTO TABLE_NAME [(column1, column2, column3,...columnN)]
VALUES (value1, value2, value3,...valueN);
如果要为表中所有列添加数据,可以前面的column名称。
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);
例:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (5, 'David', 27, 'Texas', 85000.00 );
INSERT INTO COMPANY VALUES (7, 'James', 24, 'Houston', 10000.00 );
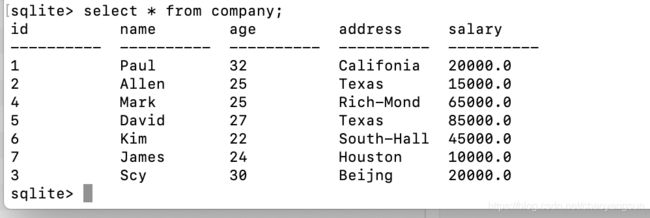
通过select * from company命令来查看表数据,查询命令后面会详细讨论。
删
SQLite 的 DELETE 查询用于删除表中已有的记录。可以使用带有 WHERE 子句的 DELETE 查询来删除选定行,否则所有的记录都会被删除
基本用法:
DELETE FROM table_name WHERE [condition];
如删除id为3的客户:
delete from company where id = 3;

如果不指定条件直接delete from company;会删除整个表的记录。where的用法后面会详细讨论。
改
SQLite 的 UPDATE 查询用于修改表中已有的记录。可以使用带有 WHERE 子句的 UPDATE 查询来更新选定行,否则所有的行都会被更新。
基本用法:
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
如更新表中id为6的记录的年龄为100:
update company set age = 100 where id = 6;

查
SQLite 的 SELECT 语句用于从 SQLite 数据库表中获取数据,以结果表的形式返回数据
基本用法:
SELECT column1, column2, columnN FROM table_name;
如查询表company的所有记录,前面已有所应用select * from company;,如果只需要查询id和name:
select id,name from company;

上面的知识点只是最基本的一些操作,实际上工作真实的查询,都是需要带有各种条件来过滤匹配相关操作的,这时候就需要使用相关的条件语句。
条件语句
一般条件查询都是使用where + 相关运算符完成。
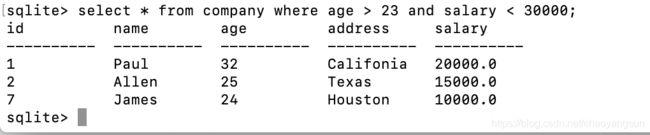
查询年龄大于23且收入小于30000的记录:
select * from company where age > 23 and salary < 30000;
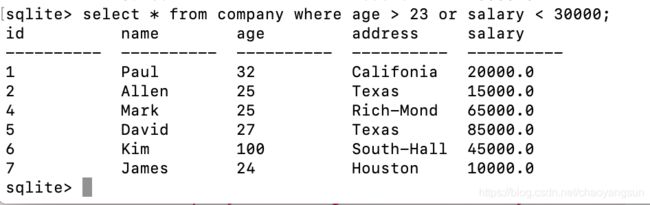
如果要查询年龄大于23或收入小于30000的记录,则需要使用where子句配合or运算符select * from company where age > 23 or salary < 30000:
如要查询薪资以2开头的,可以使用like或者glob子句:
select * from company where salary like '2%';
select * from company where salary glob '2*';

如果要查询地址以S开头,且内部含有连接符-:

排序与分组
SQLite 的 ORDER BY 子句是用来基于一个或多个列按升序或降序顺序排列数据。
基本用法:
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
如将查询结果按照薪资的升序排列:
select * from company order by salary asc;
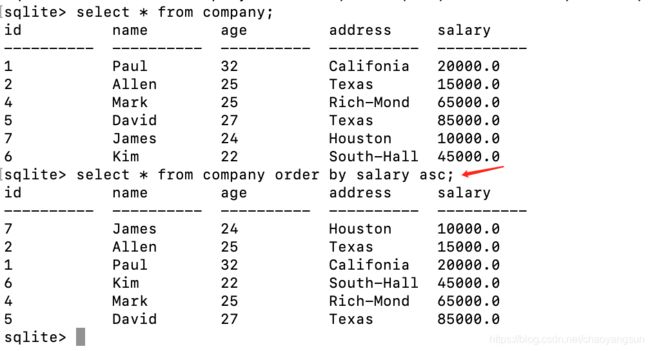
如果order by后面有多个column,将优先按照前面的column进行排列,如果结果有相同的记录,再将这些相同的记录按照后面的列进行排序.
如将表格按照年龄和薪资倒序排列:
select * from company order by age,salary desc;

搜先按照年龄排序,出现两条年龄都是25的记录,然后这两条再按照salary排列。
SQLite 的 GROUP BY 子句用于与 SELECT 语句一起使用,来对相同的数据进行分组。 在 SELECT 语句中,GROUP BY 子句放在 WHERE 子句之后,放在 ORDER BY 子句之前。
基本用法:
SELECT column-list
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
如计算不同年龄的平均工资:
select *,avg(salary) from company group by age;
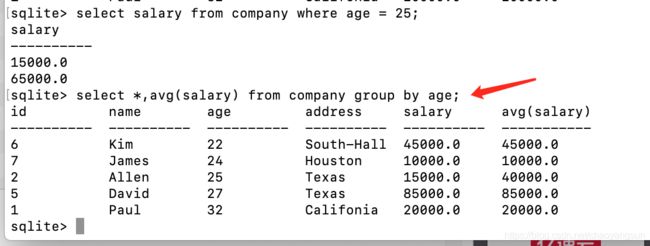
原来年龄等于25的有两人,薪资不等,现在查询出来平均工资为40000.
过滤
HAVING 子句允许指定条件来过滤将出现在最终结果中的分组结果。
WHERE 子句在所选列上设置条件,而 HAVING 子句则在由 GROUP BY 子句创建的分组上设置条件。在一个查询中,HAVING 子句必须放在 GROUP BY 子句之后,必须放在 ORDER BY 子句之前。
基本用法:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
如将年龄不重复的人按照年龄排序:
select * from company group by age having count(age) < 2;

SQLite 的 DISTINCT 关键字与 SELECT 语句一起使用,来消除所有重复的记录,并只获取唯一一次记录。
基本用法:
SELECT DISTINCT column1, column2,.....columnN
FROM table_name
WHERE [condition]
如查询表格中所有人都处于什么年龄:
select distinct age from company;

like和glob的区别
- like不区分大小写, glob区分大小写。
- like: 百分号(%)代表零个、一个或多个数字或字符。下划线(_)代表一个单一的数字或字符。
- glob: 星号(*)代表零个、一个或多个数字或字符。问号(?)代表一个单一的数字或字符。
