Ubuntu开发环境配置(九) 搭建Hadoop开发运行环境
前言
尽管Hadoop本身可以运行在Linux、Windows、以及一些类Unix系统,但是Hadoop官方支持的作业平台是Linux,在Windows中运行Hadoop时,需要安装Cywin等软件。ubantu是不错的运行版本,当然centerOS也是不错的选择。
安装配置步骤
1、安装java
2、安装配置SSH登录权限
3、单机安装配置
4、伪分布式安装
1、安装java
Hadoop本身是使用java编写的,Hadoop的运行和开发都需要java环境的支持。
安装配置java:https://blog.csdn.net/idomyway/article/details/81986471
2、安装配置SSH登录权限
对于Hadoop的伪分布和全分布而言,Hadoop节点名称(nodename)需要启动集群中所有机器的Hadoop守护进程,这个过程可以通过SSH登录来实现。Hadoop并没有提供SSH密码登录的形式,因此,为了能够顺利的登录每一台机器,需要将所有的机器配置为名称节点可以无密码的形式登录。
2.1 安装SSH服务
因为Ubantu中是默认没有SSH服务的,所以我们需要安装配置SSH:
https://blog.csdn.net/idomyway/article/details/82314098
2.2 设置SSH为无密码登录
为了实现SSH无密码登录,首先需要让节点名称生成自己的SSH密钥,命令如下:
ssh-keygen -t rsa -P ''
//在下一句命令填写默认位置
2.3 发送公共密钥
名称节点在生成自己的密钥之后,需要将他的公共密钥发送给集群中的其他机器,即将id_dsa.pub中的密钥内容添加到需要匿名登录的其他机器中的“~./ssh/authorized_keys”,我们就可以登录这台无密码的机器上去了。
对于无登录密码的本机而言,可以通过以下命令来添加:
cat ~./ssh/id_dsa.pub >> ~/.ssh/authorized_keys 2.4 验证
通过ssh localhost来检测是否需要登录密码.

这时SSH的登录配置就完成了
3、安装单机Hadoop
3.1 下载解压Hadoop
Hadoop下载地址:http://hadoop.apache.org/releases.html#Download,选择binary

创建Hadoop存放目录,将解压完的hadoop放在其中
/usr/local/hadoop 3.2 配置运行环境变量
在文件夹下(/usr/local/hadoop/hadoop-2.7.7)
对于单机安装,需要更改/etc/hadoop/hadoop-env.sh文件的JAVA_HOME,以配置Hadoop的与运行环境变量
JAVA_HOM=/usr/local/java/jdk1.8.0_181//等号两侧不能有空格 3.3 查看版本
保存,在文件夹下(/usr/local/hadoop/hadoop-2.7.7),运行一下命令查看版本
./bin/hadoop vision
3.4 运行实例验证
通过运行wordCount实例来检测Hadoop是否安装成功
进入到文件夹下(/usr/local/hadoop/hadoop-2.7.7)
首先,在hadoop文件目录下新建input文件夹,用来存放数据,
mkdir input 然后将etc/hadoop文件夹险的配置文件拷贝到input文件夹
cp ./etc/hadoop/*.xml ./input接下来,在执行命令过程中新建output文件夹下用来存放输出数据。
./bin/hadoop jar /usr/local/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'执行之后通过以下命令查看输出结果
cat ./output/* 可以看到结果 dfsadmin表示运行成功。
4、Hadoop的分布式安装
伪分布式安装是指在一台机器上模拟一个小的集群,但是在集群中只有一个节点。要实现完全分布式安装,只需要在一台机器上安装多个Linux,是每一个Linux虚拟机成为一个节点。
当Hadoop应用于节点的时候,无论是伪分布式安装还是真正的分布式运行。都需要通过配置文件对各组件的协同工作惊醒设置,注重要几个文件如下:
hadoop-env.sh:bash脚本 配置hadoop的运行环境,以运行Hadoop
core-site: xml文件 Hadoop core的配置项,如MapReduce和HDFS
hdfs-site: xml文件 Hadoop守护进程的配置项,包括Namenode、Datanode、Secondary
Mapred-site: xml文件 MapReduce守护进程的配置项,包括了JobTracker、TaskTracker
master: 纯文本 运行SecondaryNameNode的机器列表
skaves: 纯文本 运行DataNode和TaskTracker的机器列表 4.1 更改配置文件
对于伪分布式配置,需要修改core-site.xml和hdfs-site.xml文件。
/hadoop-2.7.7/etc/hadoop/文件下:
core-site.xml修改如下:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://127.0.0.1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/hadoop/hadoop-2.7.7/tmpvalue>
property>
configuration> hdfs-site.xml文件修改如下
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/hadoop-2.7.7/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/hadoop-2.7.7/tmp/dfs/datavalue>
property>
configuration>配置完成
4.2 初始化文件系统
由于Hadoop中很多工作是在自带的HDFS文件系统上完成的,所有首先需要初始化文件系统,执行命令:
./bin/hadoop namenode -format 当出现 EXiting with status 0,就说明初始化成功了

在这个过程中,可能会遇到Cannot create directory: 错误,原因是权限不够,需要修改权限
我们需要执行一下命令
sudo chmod -R a+w /*不能创建的文件夹名称*/ 4.3 启动HDFS
执行start-all.sh
/usr/local/hadoop/hadoop-2.7.7/sbin/start-all.sh 运行完之后执行jps命令查看所有进程

此时,我们可以访问http://localhost:50070来查看Hadoop的信息
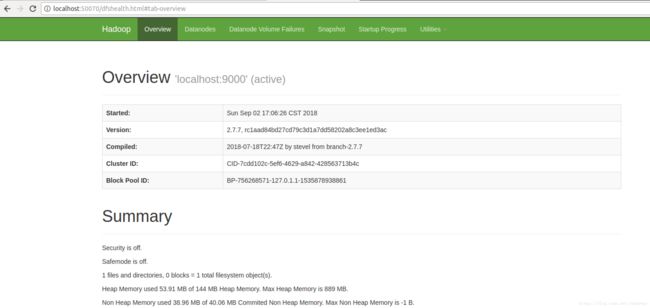
4.4执行测试用例进行测试
在HDFS中创建用户目录:
./bin/hadoop dfs -mkdir -p /user/hadoop 我们在执行单机Hadoop测试用例中产生了output和input文件夹,我们现在需要将output文件删除,同时将/etc/hadoop中的运行配置文件上传到HDFS的input文件下,执行以下命令:
./bin/hadoop dfs -put /usr/local/hadoop/hadoop-2.7.7/etc/hadoop /input 上传可能遇到WARN hdfs.DFSClient: Caught exception java.lang.InterruptedException问题,

上网经过查询,这只是一个警告,不影响数据上传
4.5 运行测试用例
./bin/hadoop jar /usr/local/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /input output 'dfs[a-z.]+'运行以下命令查看结果
./bin/hadoop fs -cat output/*结果如下:
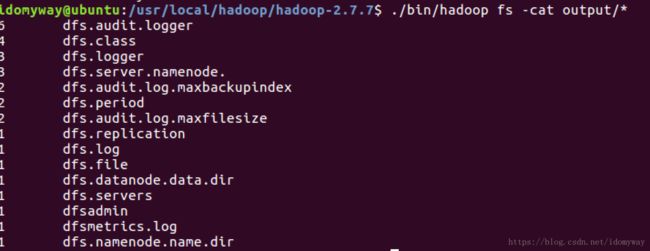
到此hadoop基础环境搭建完成