VGGNet理解及TensorFlow实现
- 本文原理内容大部分为 https://www.jianshu.com/p/5412d1dec69d 介绍
- TensorFlow实现参考《TensorFlow实战》
1. 介绍
VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发的深度卷积神经网络。VGGNet探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠 3 × 3 3\times3 3×3的小型卷积核和 2 × 2 2\times2 2×2的最大池化层,VGGNet成功地构筑了16~19层深的卷积神经网络。
VGGNet相比之前最好的网络结构,错误率大幅下降,并取得了ILSVRC 2014比赛分类项目的第2名和定位项目的第1名。同时VGGNet的扩展性很强,迁移到其他图片数据上的泛化性非常好。VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积尺寸( 3 × 3 3\times3 3×3)和最大池化尺寸( 2 × 2 2\times2 2×2)。VGGNet训练的模型参数在其官方网站上开源,可以在domain specific的图像分类任务上进行再训练(提供了非常好的初始化权重),因此被用在了很多地方。
2. 网络结构
VGGNet论文中全部使用了 3 × 3 3\times3 3×3的卷积核和 2 × 2 2\times2 2×2的池化核,通过不断加深网络结构来提升性能。
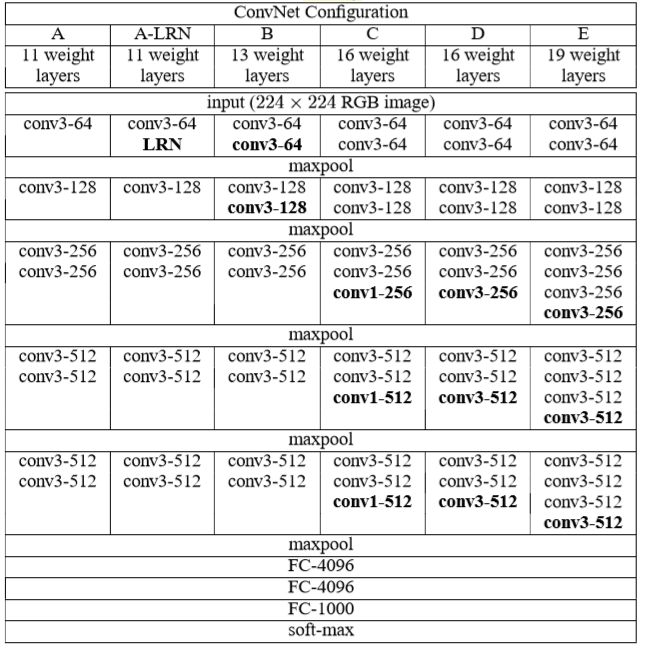

注意:
- 如图1所示。为了评估深度对于网络性能的影响,文中设计了好几种不同深度的网络结构。最浅的网络有11层,最深的有19层,其中,所有的网络模型结构最后三层都是全连接层,其余都是卷积层。
- 如图2 所示,虽然从A到E每一级网络逐渐变深,但是网络参数量并没有增长很多(参数量主要都消耗在最后的3个全连接层)。卷积参数的消耗量不大,但训练比较耗时,计算量较大。
- D、E是我们常说的VGGNet-16以及VGGNet-19。
- C比B多了 1 × 1 1\times1 1×1的卷积,主要用于线性变换,而输入通道数和输出通道数一样,没有发生降维。
为什么使用 3 × 3 3\times3 3×3的卷积核?
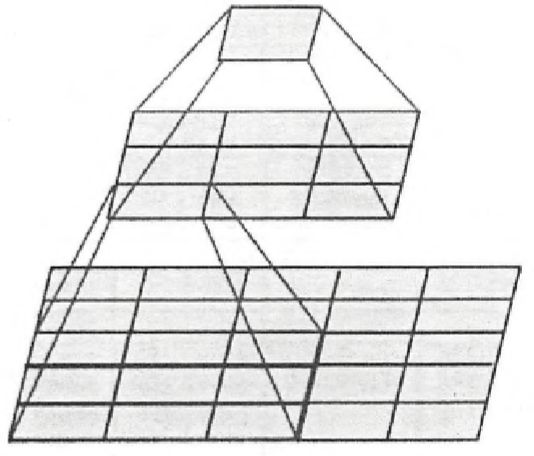
如图3所示,两个 3 × 3 3\times3 3×3的卷积层串联相当于1个 5 × 5 5\times5 5×5的卷积层,即一个像素会跟周围 5 × 5 5\times5 5×5的像素产生关联,感受野的大小为 5 × 5 5\times5 5×5。而3个 3 × 3 3\times3 3×3的卷积层串联的效果则相当于1个 7 × 7 7\times7 7×7的卷积层。除此之外,3个串联的 3 × 3 3\times3 3×3的卷积层,拥有比1个 7 × 7 7\times7 7×7的卷积层更少的参数量,只有后者的 3 × 3 × 3 7 × 7 = 55 % \frac{3\times3\times3}{7\times7}=55\% 7×73×3×3=55%。
重要的是,3个 3 × 3 3\times3 3×3的卷积层拥有1个比 7 × 7 7\times7 7×7的卷积层更多的非线性变化(前者可以使用三次ReLU激活函数,而后者只有一次),使得CNN对特征的学习能力更强。
1 × 1 1\times1 1×1的卷积核有什么作用?
在不影响卷积层的感受野的情况下,为模型引入更多的非线性(非线性激活函数的使用)。
3. 训练和测试细节
训练
- batch size为256,momentum设置为0.9,权重衰减系数为0.0005。
- 前两层全连接层使用Dropout,Dropout比例为0.5。
- 学习率初始时为0.01,当验证集的准确率停止提高时,学习率除以10。最终学习率降低了三次以后,网络就收敛了。
- 虽然和AlexNet相比,VGGNet的参数更多、深度更深,但是却收敛的更快。原因有两点,一是前面提到的更深的层和更小的卷积核相当于隐式的进行了正则化;二是在训练期间对某些层进行了预初始化。
- 对于深度网络来说,网络权值的初始化十分重要。为此,论文中首先训练一个浅层的网络结构A,训练这个浅层的网络时,随机初始化它的权重就足够得到比较好的结果。然后,当训练深层的网络时,前四层卷积层和最后的三个全连接层使用的是学习好的A网络的权重来进行初始化,而其余层则随机初始化。这也就是上一点提到的某些层的预初始化。(随机初始化权重时,使用的是0均值,方差0.01的正态分布;偏置则都初始化为0)。
- 首先将图像各向同性的缩放,使得最短边缩放至S( S ≥ 224 S≥224 S≥224),由于要求输入是 224 × 224 224\times224 224×224大小的,所以再对缩放后的图像进行crop。至于S的取值,论文提出了两种不同的方法:
- 固定的尺度,对所有的图片,S都是固定的同样的值。论文考察了S=256和S=384两种情况下分别训练得到的网络的性能。为了加速,训练S=384的网络时,使用训练好的S=256的网络来初始化权重,并且学习率更小,为0.001。
- 可变的尺度,设置一个范围[ S m i n S_{min} Smin, S m a x S_{max} Smax],每一张图片都从这个范围内随机选取一个数作为它的S。论文中使用的范围是[256,512]。这使得训练在一个很大范围的图像尺度之上进行。为了加速,通过微调S=384的固定尺度的网络来训练得到可变尺度的网络。
测试
在测试阶段,首先将图像各向同性的缩放,使得最短边缩放至Q。注意,Q没必要一定要和S相等。然后,使用两种不同的方式进行分类:dense evaluation和multi-crop evaluation,这两种方式分别借鉴于Overfeat和GoogLeNet。下面详细介绍一下这两种方式:
(1)dense evaluation
它的设计非常巧妙,并不需要我们显式的在缩放后的图像上crop出 224 × 224 224\times224 224×224的图像。而是直接将缩放后的图像输入,再通过将最后的三层全连接层表达为卷积层的形式,来实现在缩放后的图像上密集crop的效果。最后将结果平均得到最终的分类结果。
- 首先来看为什么全连接层可以转变为卷积层的形式。假设一个神经网络前面都是卷积层,后面跟着三层全连接层f1、f2和f3,每个全连接层神经元的个数分别为 n 1 n_1 n1、 n 2 n_2 n2和 n 3 n_3 n3,且经过前面所有的卷积层之后,得到的是 m × m m\times m m×m的C个通道的feature map。一般来说,进入全连接层之前,我们应该首先将这个feature map展成一维向量,再于f1全连接层相连接。但是实际上,我们可以将f1层看作是卷积核大小为 m × m m\times m m×m,通道数为 n 1 n_1 n1的卷积层,这样卷积后得到的输出是 1 × 1 × n 1 1\times1\times n_1 1×1×n1的(不加padding),效果和全连接层一样。然后,再将f2层看作是卷积核大小为 1 × 1 1\times1 1×1,通道数为 n 2 n_2 n2的卷积层;将f3层看作是卷积核大小为 1 × 1 1\times1 1×1,通道数为 n 3 n_3 n3的卷积层(道理同f1层一样)。
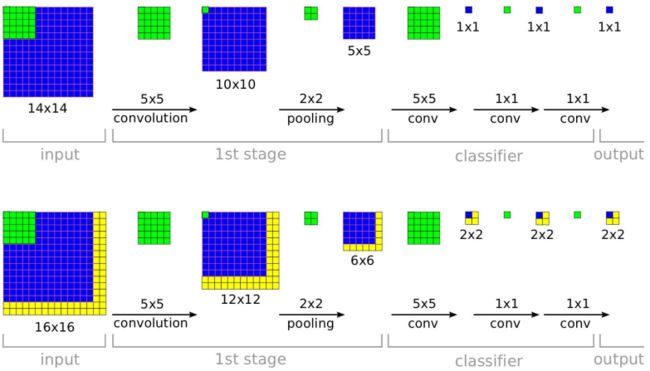
- 上面证明了可以将全连接层转变为卷积层,下面来讲一下这么做的效果,为什么能起到密集crop的效果。 如下图所示(图片来自于论文Overfeat),假设训练时网络接受的图像大小是 14 × 14 14\times14 14×14,最后输出的是它所属的类别。假设测试时缩放后的图片大小为 16 × 16 16\times16 16×16,在将全连接层转变成卷积层后 ,我们将这个缩放后的图像直接输入给网络,而不是crop出 14 × 14 14\times14 14×14的大小,可以发现,最后得到的是4个结果而不是它上面所示的1个。其实这4个结果分别相当于在缩放后的图像上crop出左上、右上、左下、右下4个 14 × 14 14\times14 14×14图像的分类结果。然后将多个位置的结果取平均作为整个图像的最终结果。相比于在缩放后的图像上crop出多个图像后再分别放入网络进行分类,这种操作省去了许多重复性的运算,所有的卷积操作只需要做一遍即可。值得注意的是,在这个例子中,相当于每滑动两个像素crop一个图像,这是因为中间有一个步长为2的 2 × 2 2\times2 2×2的pooling操作。所以有时当pooling操作较多时,这种方法可能反而没有直接多次crop得到的结果精细。
(2)multi-crop evaluation
相当于AlexNet中所使用的crop方法的加强版。在GoogleLeNet中描述的详细过程如下:将图片缩放到不同的4种尺寸(纵横比不变,GoogleLeNet使用的4种尺寸为:缩放后的最短边长度分别为:256,288,320和352)。
- 对于得到的每个尺寸的图像,取左、中、右三个位置的正方形图像(边长就是最短边的长度。对于纵向图像来说,则取上、中、下三个位置),因此每个尺寸的图像得到3个正方形图像;
- 然后再在每个正方形图像的4个crop顶点和中心位置处crop处 224 × 224 224\times224 224×224的图像,此外再加上将这个正方形图像缩放到 224 × 224 224\times224 224×224大小的图像,因此每个正方形图像得到6个 224 × 224 224\times224 224×224的图像;
- 最后,再将所有得到的 224 × 224 224\times224 224×224的图像水平翻转。
- 因此,每个图像可以得到 4 × 3 × 6 × 2 = 144 4\times3\times6\times2=144 4×3×6×2=144个 224 × 224 224\times224 224×224大小的图像。将这些图像分别输入神经网络进行分类,最后取平均,作为这个图像最终的分类结果。
- 而VGG中则使用的是3种尺寸,每个尺寸在5个位置处取正方形图像(四个顶点加中心),每个正方形图像crop出5个 224 × 224 224\times224 224×224大小的图像,最后水平翻转,即 3 × 5 × 5 × 2 = 150 3\times5\times5\times2=150 3×5×5×2=150。
4. 对比试验
(1)单尺度评估
评估上面提出的几个网络模型,测试时,对于固定的S,取Q=S;对于可变的S,取 Q = 0.5 ( S m i n + S m a x ) Q=0.5(S_{min}+S_{max}) Q=0.5(Smin+Smax)。实验结果如下:
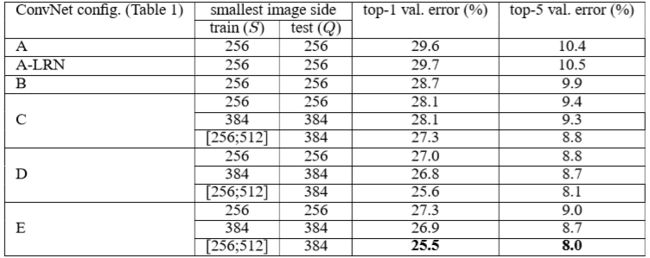
- A-LRN是指应用了LRN的A网络结构,和A网络相比性能并没有提升,在之后的网络结构都不适用LRN(Local Response Normalization)技术;
- 可以看到,分类误差随着网络深度的增加而降低;
- 值得注意的是,B和C拥有相同的 3 × 3 3\times3 3×3的卷积层数,只是C有额外的 1 × 1 1\times1 1×1的卷积层,结果表明C的性能由于B,说明额外的非线性可以提高网络的性能;
- C和D拥有相同的卷积层数,只是C有一些 1 × 1 1\times1 1×1的卷积层,而D只有 3 × 3 3\times3 3×3的卷积层,结果表明D的性能由于C,说明抓取空间局部信息也同样重要;
- 训练时,使用可变的尺度(尺度抖动,scale jittering)比固定的尺度效果更好。
(2)多尺度评估
多尺度估计,就是在测试时,将图像缩放到几个不同的尺度,即Q的取值有多个,再将每个尺度得到的结果平均,得到最终的结果。对于固定的S,令Q={S-32,S+32};对于可变的S,令Q={ S m i n S_{min} Smin, 0.5 ( S m i n + S m a x ) 0.5(S_{min}+S_{max}) 0.5(Smin+Smax), S m a x S_{max} Smax}。实验结果如下:
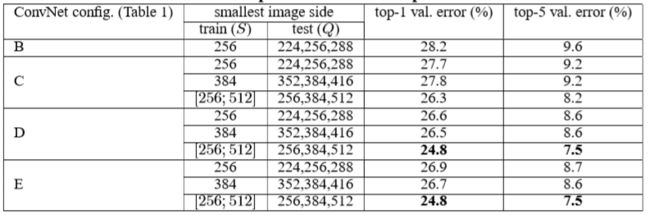
通过和单尺度的结果对比,可以发现在测试时使用多尺度(尺度抖动),可以提升准确率。
(3)multi-crop评估
比较了dense和multi-crop两种方法的性能,此外,还将这两种方法结合起来,得到了更高的准确率。结果如下:
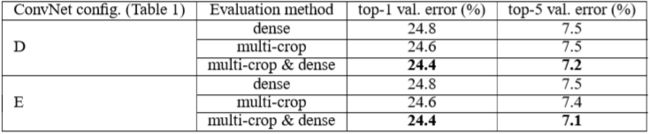
- multi-crop方法略好于dense(可能原因:网络中包含很多pooling操作,导致dense的方法实际上每隔很多个像素才会进行crop,反而不如multi-crop采样出的图像多);
- 将两种方法结合起来会在一定程度上提升性能,因为这两种方法有一定的互补性。它们在卷积层提取特征时padding方式不同: multi-crop每次crop出图像后分别放入网络,故所有crop出的图像在卷积层中的padding方式都是补0;而dense则不同,处理在原图像边缘位置之外,其余的都相当于在卷积层padding时补的是它们附近的像素。
(4)多个网络结合
论文还将训练的多个网络模型的结果相结合得到最终的分类结果,显然,这会提升分类的准确率以及稳定性,结果如下:

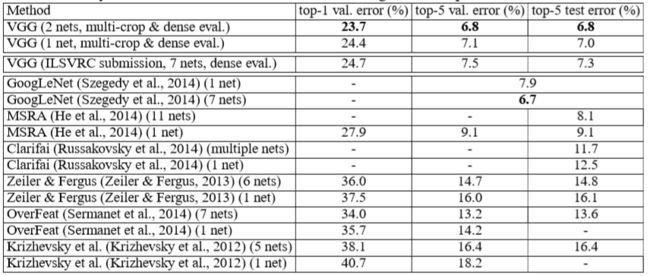
(5)与其他方法相比较
5. TensorFlow实现
ImageNet数据训练VGGNet耗时较长,因此值评测其forward(inference)耗时和backward(training)耗时。
代码
'''
VGG-16
'''
from datetime import datetime
import math
import time
import tensorflow as tf
# 设置batch_size和num_batches
batch_size = 32
num_batches = 100
'''
conv_op:用来创建卷积层并把本层的参数存入参数表
输入:input_op--输入的tensor、name--名称、kh--卷积核的高、kw--卷积核的宽、n_out--卷积核数量(输出通道数)、
dh--步长的高、dw--步长的宽、p--参数列表
'''
def conv_op(input_op, name, kh, kw, n_out, dh, dw, p):
n_in = input_op.get_shape()[-1].value #get_shape()[-1].value--获取输入input_op的通道数
with tf.name_scope(name) as scope:
kernel = tf.get_variable(scope+"w",
shape=[kh, kw, n_in, n_out], dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d()) #tf.contrib.layers.xavier_initializer_conv2d()--参数初始化
conv = tf.nn.conv2d(input_op, kernel, (1, dh, dw, 1), padding='SAME')
bias_init_val = tf.constant(0.0, shape=[n_out], dtype=tf.float32)
biases = tf.Variable(bias_init_val, trainable=True, name='b')
z = tf.nn.bias_add(conv, biases)
activation = tf.nn.relu(z, name=scope)
p += [kernel, biases]
return activation
'''
fc_op:全连接层的创建函数
输入:input_op--输入通道数、name--名称、n_out--输出的通道数、p--参数列表
'''
def fc_op(input_op, name, n_out, p):
n_in = input_op.get_shape()[-1].value
with tf.name_scope(name) as scope:
kernel = tf.get_variable(scope+'w',
shape=[n_in, n_out], dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer())
biases = tf.Variable(tf.constant(0.1, shape=[n_out],dtype=tf.float32),
name='b') #biases赋初值为0.1,避免dead neuron
activation = tf.nn.relu_layer(input_op, kernel, biases, name=scope) #tf.nn.relu_layer--对输入变量input_op与kernel做矩阵乘法并加上biases,再做ReLU非线性变换
p += [kernel, biases]
return activation
'''
mpool_op:最大池化的创建函数
输入:input_op--输入通道数、name--名称、kh--卷积核高度、kw--卷积核宽度、dh--步长高度、dw--步长宽度
'''
def mpool_op(input_op, name, kh, kw, dh, dw):
return tf.nn.max_pool(input_op,
ksize=[1, kh, kw, 1],
strides=[1, dh, dw, 1],
padding='SAME',
name=name)
'''
inference_op:VGGNet-16网络结构的函数
输入:input_op--输入通道数、keep_rob--dropout比率
'''
def inference_op(input_op, keep_prob):
p = [] #初始化参数列表
#第一段卷积
conv1_1 = conv_op(input_op, name="conv1_1", kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)
conv1_2 = conv_op(conv1_1, name="conv1_2", kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)
pool1 = mpool_op(conv1_2, name="pool1", kh=2, kw=2, dw=2, dh=2)
#第二段卷积
conv2_1 = conv_op(pool1, name="conv2_1", kh=3, kw=3, n_out=128, dh=1, dw=1, p=p)
conv2_2 = conv_op(conv2_1, name="conv2_2", kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)
pool2 = mpool_op(conv2_2, name="pool2", kh=2, kw=2, dh=2, dw=2)
#第三段卷积
conv3_1 = conv_op(pool2, name="conv3_1", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
conv3_2 = conv_op(conv3_1, name="conv3_2", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
conv3_3 = conv_op(conv3_2, name="conv3_3", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
pool3 = mpool_op(conv3_3, name="pool3", kh=2, kw=2, dh=2, dw=2)
#第四段卷积
conv4_1 = conv_op(pool3, name="conv4_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv4_2 = conv_op(conv4_1, name="conv4_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv4_3 = conv_op(conv4_2, name="conv4_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
pool4 = mpool_op(conv4_3, name="pool4", kh=2, kw=2, dh=2, dw=2)
#第五段卷积
conv5_1 = conv_op(pool4, name="conv5_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv5_2 = conv_op(conv5_1, name="conv5_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
conv5_3 = conv_op(conv5_2, name="conv5_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
pool5 = mpool_op(conv5_3, name="pool5", kh=2, kw=2, dw=2, dh=2)
#将卷积后的输出结果进行扁平化
shp = pool5.get_shape()
flattented_shape = shp[1].value * shp[2].value * shp[3].value
resh1 = tf.reshape(pool5, [-1, flattented_shape], name="resh1")
#全连接层6
fc6 = fc_op(resh1, name="fc6", n_out=4096, p=p)
fc6_drop = tf.nn.dropout(fc6, keep_prob, name="fc6_drop")
#全连接层7
fc7 = fc_op(fc6_drop, name="fc7", n_out=4096, p=p)
fc7_drop = tf.nn.dropout(fc7, keep_prob, name="fc7_prob")
#全连接层8、softmax、predictions
fc8 = fc_op(fc7_drop, name="fc8", n_out=1000, p=p)
softmax = tf.nn.softmax(fc8)
predictions = tf.argmax(softmax, 1)
return predictions, softmax, fc8, p
'''
time_tensorflow_run():评测函数
'''
def time_tensorflow_run(session, target, feed, info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target, feed_dict=feed)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s:step %d, duration = %.3f' % (datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' % (datetime.now(), info_string, num_batches, mn, sd))
'''
run_benchmark:评测主函数
'''
def run_banchmark():
with tf.Graph().as_default():
image_size = 224
#随机生成224*224的随机图片,使用tf.random_normal函数生成标准差为0.1的正态分布的随机数
images = tf.Variable(tf.random_normal([batch_size,
image_size,
image_size, 3],
dtype=tf.float32,
stddev=1e-1))
#创建keep_prob,调用inference_op构建VGGNet-16的网络结构
keep_prob = tf.placeholder(tf.float32)
predictions, softmax, fc8, p = inference_op(images, keep_prob)
#创建Session并初始化全局参数
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
'''
1. 将keep_prob设为1.0执行预测,使用time_tensorflow_run评测forward运算时间
2. 计算fc8的l2 loss
3. 使用tf.gradients求相对于这个loss的所有模型参数的梯度
4. 使用time_tensorflow_run评测backward运算时间,target为grad,keep_prob为0.5
'''
time_tensorflow_run(sess, predictions, {keep_prob: 1.0}, "Forward")
objective = tf.nn.l2_loss(fc8)
grad = tf.gradients(objective, p)
time_tensorflow_run( sess, grad, {keep_prob: 0.5}, "Forward-backward")
def main():
run_banchmark()
if __name__ == '__main__':
main()
实验结果(CPU计算耗时较长)
正向:
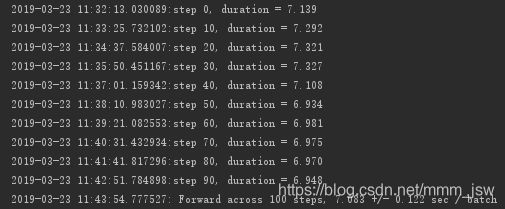
反向:
结论
VGGNet的模型参数虽然比AlexNet多,但反而只需要较少的迭代次数就可以收敛,主要原因是更深的网络和更小的卷积核带来的隐式的正则化效果。
参考
- 《TensorFlow实战》—— 黄文坚、唐源
- 《VGGNet》—— https://www.jianshu.com/p/5412d1dec69d