游离态GLZ的NLP任务1:拼写纠错
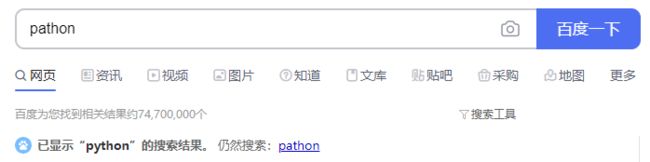
当我们使用搜索引擎的时候,经常会发现我们打错了我们想要检索的东西,但是搜索引擎仍旧给了我们正确的答案。比如我们把"python"打成了"pathon",百度成功识别了出来我们真正想要的。
1.利用编辑距离生成候选集合
实现拼写纠错时首先需要生成可能正确词的候选集合。其核心在于编辑距离这一NLP任务的常用基础算法。编辑距离等于把一个字符串通过删除、修改、插入三种操作改为另一个字符串的最短距离(强烈建议刷一下这道DP题)。
生成可能正确词的候选集合时,我们需要预先准备好一个词典库,代表常见的词汇(一般认为这些是正确的)。当用户输入一个可能拼写错误的词时,我们生成编辑距离一定的候选词,把这些候选词和词库中的词对比,如果一样则认为可能是用户拼错的输入真正想要的词。
为了实现方便选择编辑距离为1:
#加载词典库,注意用set,检索复杂度为0(1)
vocab = set(line.rstrip() for line in open("vocab.txt"))
#选出所有与用户输入编辑距离为1的词作为候选
def generate_candidates(input_word):
'''
input_word:用户输入(可能有错)
return:与用户输入编辑距离为1的候选词
'''
# 所有输入都已经归一化为小写
letters = 'abcdefghijklmnopqrstuvwxyz'
#遍历所有输入拆开的情况(拆开成为原始输入和空也算)
splits = [(input_word[:i],input_word[i:]) for i in range(len(input_word)+1)]
#插入情况
inserts = [L + c + R for L,R in splits for c in letters]
#删除情况
deletes = [L + R[1:] for L,R in splits]
#修改情况
replaces = [L + c + R[1:] for L,R in splits for c in letters]
candidates = set(inserts + deletes + replaces)
candidates = [word for word in candidates if word in vocab]
return candidates
测试效果:

注意实现的时候词典库使用set数据结构,这样检索的代价是O(1)。整体算法时间复杂度:
1.拆分输入:O(m)(m为用户输入长度)
2.删除、插入、修改方法的候选词生成:O(lm)(l为可能的字符数量)
3.筛选词:O(n)(n为生成的候选词数量,查找词典库O(1))
总体T = O(lm + n),代价并不大。
2.利用拼错的历史记录统计拼错概率
我们读取准备好的拼写错误历史记录,得到把某个单词拼写错误的字典,并且认为拼写错误成这些单词是等概率的。
def channel_probability():
channel_prob = {}
for line in open("spell-errors.txt"):
line = line.split(":")
correct = line[0].strip()
mistack = [word.strip() for word in line[1].strip('\n').split(',')]
channel_prob[correct] = {}
for mis in mistack:
channel_prob[correct][mis] = 1/len(mistack)
return channel_prob
3.bigram语言模型
利用nltk的路透社语料库统计单词以及两个单词相连出现的概率。句首增加起始符 < s > <s>用来体现句首出现某次的概率。
# 根据路透社语料库统计每个词出现的频率以及其bigram的频率,用于计算p(w2|w1)
def language_model():
word_count={}
bigram_count={}
for doc in corpus:
#增加句子起始符,可以考虑到起点词的概率
doc = [''] + doc
for i in range(len(doc)-1):
#bigram=[w_i,w_i+1]
word = doc[i]
bigram = doc[i:i+2]
bigram = ' '.join(bigram)
if word not in word_count:
word_count[word] = 1
else:
word_count[word] += 1
if bigram not in bigram_count:
bigram_count[bigram] = 1
else:
bigram_count[bigram] += 1
return [word_count,bigram_count]
4.拼写纠错的实现
给定某个错误拼写mistake,其真正应该是某单词correct,这个概率表示为:
p ( c o r r e c t ∣ m i s t a c k ) = p ( m i s t a c k ∣ c o r r e c t ) p ( c o r r e c t ) p ( m i s t a c k ) p(correct|mistack) = \frac{p(mistack|correct)p(correct)}{p(mistack)} p(correct∣mistack)=p(mistack)p(mistack∣correct)p(correct)
因为错误单词是给定的,因此可以认为 p ( m i s t a c k ) p(mistack) p(mistack)为常数,因此:
p ( c o r r e c t ∣ m i s t a c k ) = p ( m i s t a c k ∣ c o r r e c t ) p ( c o r r e c t ) p(correct|mistack) = p(mistack|correct)p(correct) p(correct∣mistack)=p(mistack∣correct)p(correct)
p ( m i s t a c k ∣ c o r r e c t ) p(mistack|correct) p(mistack∣correct)可用2中拼错概率表示, p ( c o r r e c t ) p(correct) p(correct)可用3中语言模型表示。
#修改文本中的错误
def main():
vocab = set([line.rstrip() for line in open('vocab.txt')])
word_count,bigram_count = language_model()
#语料库中的词语总类别数
V = len(word_count.keys())
channel_prob = channel_probability()
with open("testdata.txt") as f:
for line in f:
#把句子拆成英文单词列表
words = line.rstrip('.').split('\t')
words = words[2].split()
for word in words:
if word[-1] == ',':
word = word[:-2]
if words[-1][-1] == '.':
words[-1] = words[-1][:-2]
#print(words)
#对每个单词生成候选单词
for i,word in enumerate(words):
if word in vocab:
continue
print(word)
candidates = generate_candidates(word)
# 一种方式: if candidate = [], 多生成几个candidates, 比如生成编辑距离不大于2的
# TODO : 根据条件生成更多的候选集合
#简单实现只考虑编辑距离为1的
if len(candidates) < 1:
continue
#寻找可能性最高的candidates,根据贝叶斯公式,
# p(correct|mistack)= p(mistack|correct)p(correct)/p(mistack)(分母为常数)
# 等同于 log(p(mistack|correct))+ log(p(correct))
probs = []
for candidate in candidates:
prob = 0
# log(p(mistack|correct))部分计算channel_probability,即正确单词是这个的时候拼错成word的概率
if candidate in channel_prob and word in channel_prob[candidate]:
prob += np.log(channel_prob[candidate][word])
#print(prob)
else:
prob += np.log(0.0001) #认为是一个极小的概率,防止变0
# log(p(correct))部分计算语言模型,看看这个词是否合适出现在这
if i == 0:
biword = ' '+ word
else:
biword = words[i-1] + ' ' + word
if biword in bigram_count:
prob += np.log((bigram_count[biword]+1)/(word_count[word]+V))
print(prob)
else:
prob += np.log(1.0 / V)
probs.append(prob)
max_idx = probs.index(max(probs))
#print(probs)
#print(max_idx)
print(word, candidates[max_idx])