数据挖掘之模糊聚类算法学习和java实现
物以类聚,人以群分,模糊聚类算法最早从硬聚类目标函数的优化中导出的。首先由Dunn于1974年提出,后来1981年由Bezdek扩展到加权类内误差平方和的无限族,形成了FCM聚类算法的通用聚类准则。它主要是把含有n个样本的数据集分为c类,聚类结果用聚类中心和隶属度表示。模糊c均值是数据挖掘经典算法之一
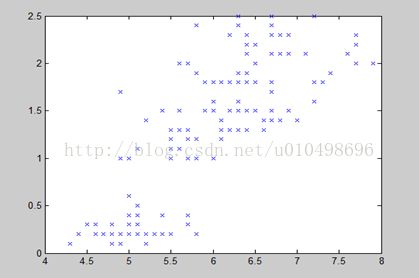
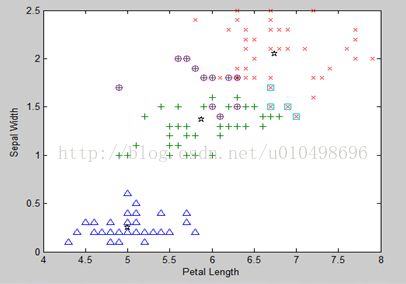
如下图所示:为了直观感受,下面给出经典的iris数据集(150个样本,每个样本4个属性)在坐标系下的显示和分类,数据集可以在http://archive.ics.uci.edu/ml/datasets.html获得。左图中的数据集经过模糊聚类划分为右图中的三类
图中只选取了2维显示,但是划分是按4维划分的。右图的划分中蓝色星星,绿色十字型和红色x号一共形成三类,三个五角星为聚类中心,其余形式为错误分类的样本。
下面是FCM算法原理,上面是目标函数和约束条件,为了求得目标函数的最小值,(箭头指向)下面是根据引入拉格朗日算子求导得到的隶属度和聚类中心的迭代公式。
显然,算法是通过隶属度U和聚类中心V的相互迭代优化完成的。当然这容易陷入局部最优,其他的求解目标函数最小值的方法有遗传算法,模拟退火,神经网络等,但比较费时。

下面给出算法迭代步骤:

下面直接贴出java代码:
package cluster;
/**
* @author jungege 2015.5.5
*/
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
/**
* @author
*
*/
public class Fcm_myself {
private static final String FILE_DATA_IN = "C:\\Users\\Administrator\\Desktop\\clusterdata\\data_in.txt";//输入的样本数据
private static final String FILE_PAR = "C:\\Users\\Administrator\\Desktop\\clusterdata\\parameters.txt";//参数配置
private static final String FILE_CENTER = "C:\\Users\\Administrator\\Desktop\\clusterdata\\center.txt";//聚类中心
private static final String FILE_MATRIX = "C:\\Users\\Administrator\\Desktop\\clusterdata\\matrix.txt";//隶属度矩阵
public int numpattern;//样本数
public int dimension;//每个样本点的维数
public int cata;//要聚类的类别数
public int maxcycle;//最大的迭代次数
public double m;//参数m
public Fcm_myself() {
super();
}
public Fcm_myself(int numpattern, int dimension, int cata, int maxcycle, double m, double limit) {
this.numpattern = numpattern;
this.dimension = dimension;
this.cata = cata;
this.maxcycle = maxcycle;
this.m = m;
this.limit = limit;
}
/**
* 读取配置文件
* @return
*/
public boolean getPar() {
//打开配置文件
BufferedReader br = null;
try {
br = new BufferedReader(new FileReader(FILE_PAR));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
//读取配置文件
String line = null;
for (int i = 0; i < 6; i++) {
try {
line = br.readLine();
} catch (IOException e) {
// TODO 自动生成 catch 块
e.printStackTrace();
}
switch(i) {
case 0: numpattern = Integer.valueOf(line); break;
case 1: dimension = Integer.valueOf(line); break;
case 2: cata = Integer.valueOf(line); break;
case 3: m = Double.valueOf(line); break;
case 4: maxcycle = Integer.valueOf(line); break;
case 5: limit = Double.valueOf(line); break;
}
}
//读取配置文件
/* try{
InputStream in = getClass().getResourceAsStream("E:\\weka_learing\\DataMing\\src\\initParam.properties");//将配置文件读取到InputStream对象中
Properties prop = new Properties();
prop.load(in);
numpattern = Integer.valueOf(prop.getProperty("numpattern"));
dimension = Integer.valueOf(prop.getProperty("dimension"));
cata = Integer.valueOf(prop.getProperty("cata"));
m = Integer.valueOf(prop.getProperty("m"));
maxcycle = Integer.valueOf(prop.getProperty("maxcycle"));
}catch(IOException e){
e.printStackTrace();
}
*/
return true;
}
/**
* 读取样本
* @param pattern
* @return
*/
//样本保存在二维数组中
public boolean getPattern(double[][] pattern) {
BufferedReader br = null;
try {
br = new BufferedReader(new FileReader(FILE_DATA_IN));
} catch (FileNotFoundException e) {
// TODO 自动生成 catch 块
e.printStackTrace();
}
//读取样本文件
String line = null;
String regex = "\\s+";//String regex = ",";
int row =0;
while (true) {
try {
line = br.readLine();
} catch (IOException e) {
// TODO 自动生成 catch 块
e.printStackTrace();
}
if (line == null)
break;
String[] split = line.split(regex);//字符串以','拆分
for (int i = 0; i < split.length; i++){
pattern[row][i] = Double.valueOf(split[i]);
}
row++;
}
return false;
}
/**
* 求数组最大值最小值
* @param a 输入
* @return 返回一个包含2个元素的一维数组
*/
public static double[] min_max_fun(double []a){
double minmax[] = new double[2];
double minValue=a[0];
double maxValue=a[1];
for(int i=1;imaxValue)
maxValue=a[i];
}
minmax[0]=minValue;
minmax[1]=maxValue;
return minmax;
}
/**
* 规范化样本
* @param pattern 样本
* @param numpattern 样本数量
* @param dimension 样本属性个数
* @return
*/
public static boolean Normalized(double pattern[][],int numpattern,int dimension){
double min_max[] = new double[2];
double a[] = new double[pattern.length];//提取列
//先复制pattern到copypattern
double copypattern[][] = new double[numpattern][dimension];
for(int i=0;i= numpattern || m <= 1)
return false;
//规格化样本--蠢哭了
Normalized(pattern,numpattern,dimension);
int dai =0,testflag=0;//迭代次数,迭代标志
//初始化隶属度
double temp[][] = new double[cata][numpattern];
for(int i=0;if)
f=cha[i][j];//f矩阵中最大值
}
}
if(f<=1e-6||dai>maxcycle)
testflag=1;
dai=dai+1;
result = objectfun(umatrix, rescenter, pattern, cata, numpattern, dimension,m);
System.out.println(result);//控制台输出目标函数值
}
return true;
}
/**
* 计算目标函数值
* @param u
* @param v
* @param x
* @param c
* @param pattern
* @param dimension
* @param m
* @return
*/
public double objectfun(double u[][],double v[][],double x[][],int c,int numpattern,int dimension,double m) {
//此函数计算优化的目标函数
int i,j,k;
double t=0,objectValue;
double J_temp[][] = new double[numpattern][c];
for(i=0;i
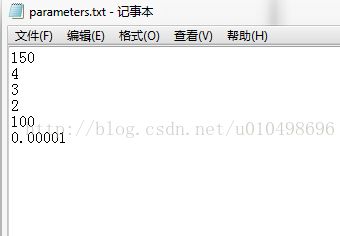
运行程序要注意修改文件路径里面包含4个文件:参数配置文件,数据集,输出隶属度文件和输出聚类中心文件
有关参数配置文件和数据集文件(不全,可在博客开头网站下载)如下:

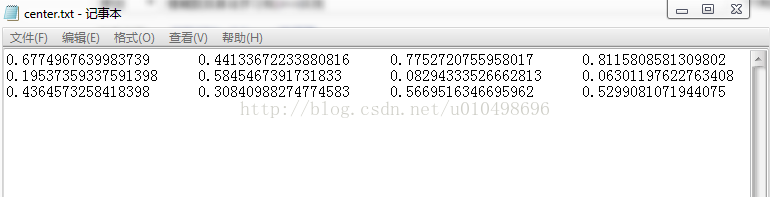
运行程序输出如下:

关于模糊聚类算法的研究方向有很多,如相似度度量(同一数据集使用不同的相似性度量聚类效果不同),目标函数的优化(引入各种先进算法)等。