Win10下使用CLion编写CUDA代码cmake编译并运行
此方法是基于的情形是
- visual studio 2017安装完成
- cuda10.0安装完成
- Clion安装完成
1. 使用CLion创建一个新的项目
File->New Project->C++ Executable->Create
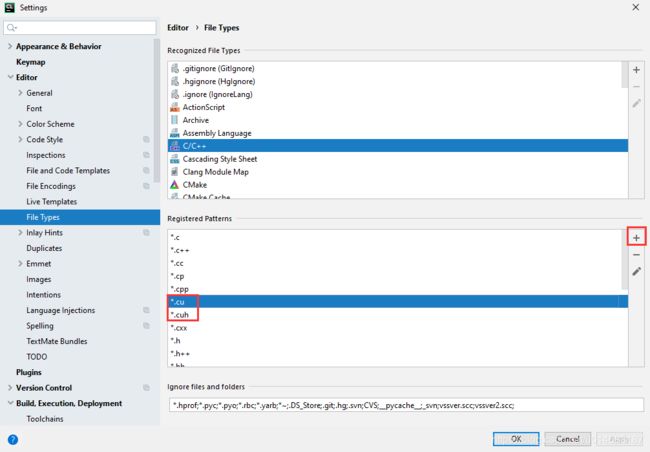
2. 设置CLion支持.cu和.cuh
File->Setting->Editor->File Types->C++
3. 新建一个cu文件
文件名为kernel.cu,内容如下
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include 4. 编写cmakelists.txt
cmake_minimum_required(VERSION 3.14)
project(Hello)
set(CMAKE_CXX_STANDARD 14)
find_package(CUDA REQUIRED)
file(GLOB CU kernel.cu)
cuda_add_executable(kernel kernel.cu)
5. 设置toolchains
File->Setting->Build,Execution,Deployment->Toolchains
设置如下所示
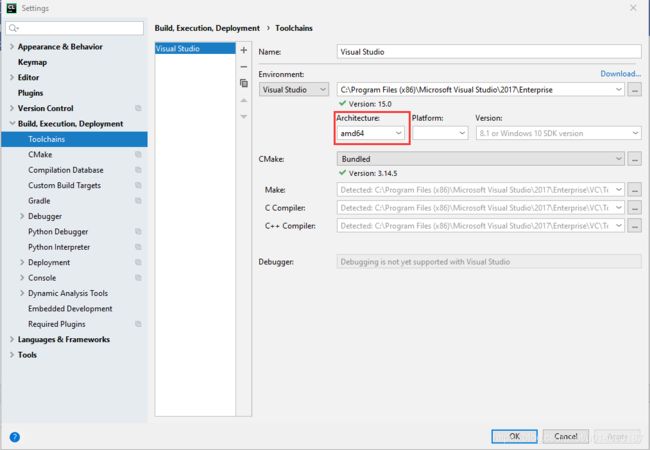
选择amd64位
6. 运行
得到如下结果
