用cifar10训练一个卷积神经网络
今天按照教程搭建了一个神经网络,这里总结一下。搭建神经网络的结构如下所示:
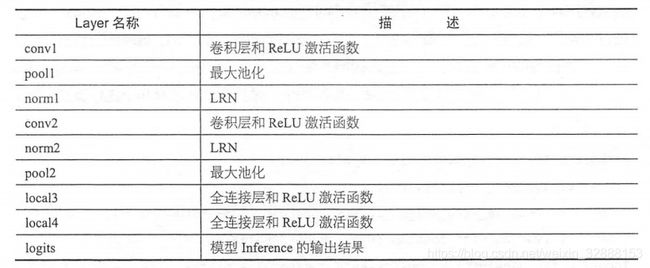
我们搭建自己的网络时,一般先确定自己的网络架构,然后计算个层参数,做好这些预备工作之后就可以开始写代码了。
#导入所需要的包
import cifar10,cifar10_input
import tensorflow as tf
import numpy as np
import time
import math
max_step=3000#迭代3000次
batch_size=128#每次迭代使用128张图片
#下载cifar10的默认路径
data_dir='/tmp/cifar10_data/cifar-10-batches-bin'
#定义权重函数
def variable_with_weight_loss(shape,stddev,w1):
var=tf.Variable(tf.truncated_normal(shape,stddev=stddev))
if w1 is not None:
weight_loss=tf.multiply(tf.nn.l2_loss(var),w1,name='weight_loss')
# 我们使用tf.add_to_collection把weight loss统一存到一个collection,这个collection名为"losses",它会在后面计算神经网络总体loss时被用上
tf.add_to_collection("losses", weight_loss)
return var
# 下载cifar10类的数据集,并解压,展开到其默认位置
cifar10.maybe_download_and_extract()
#按每一批次来读取数据
images_train,labels_train=cifar10_input.distorted_inputs(
data_dir=data_dir,
batch_size=batch_size)
images_test,labels_test=cifar10_input.inputs(eval_data=True,
data_dir=data_dir,
batch_size=batch_size)
# 因为batch_size在之后定义网络结构时被用到了,所以数据尺寸中的第一个值即样本条数需要被预先设定,而不能像以前那样设置为None
# 而数据尺寸中的图片尺寸为24*24即是剪裁后的大小,颜色通道数则设为3
# 这里写batch_size而不是None 因为后面代码中get_shape会拿到这里面的batch_size
#训练集多少行,就有多少个Label
image_holder=tf.placeholder(tf.float32,[batch_size,24,24,3])
labels_holder=tf.placeholder(tf.int32,[batch_size])
#第一个卷积层,64个卷积核,卷积核大小是5*5,3通道
weight1=variable_with_weight_loss(shape=[5,5,3,64],stddev=5e-2,
w1=0.0)#初始化参数
kernel1=tf.nn.conv2d(image_holder,weight1,[1,1,1,1],padding='SAME')#卷积
bias1=tf.Variable(tf.constant(0.0,shape=[64]))#初始化参数
conv1=tf.nn.relu(tf.nn.bias_add(kernel1,bias1))#使用激活函数激活
# 使用尺寸3*3步长2*2的最大池化层处理数据,这里最大池化的尺寸和步长不一样,可以增加数据的丰富性
pool1=tf.nn.max_pool(conv1,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
# 使用LRN对结果进行处理
norm1=tf.nn.lrn(pool1,4,bias=0.1,alpha=0.001/9.0,beta=0.75)
#第二个卷积层
weight2=variable_with_weight_loss(shape=[5,5,64,64],stddev=5e-2,
w1=0.0)#初始化参数
kernel2=tf.nn.conv2d(norm1,weight2,[1,1,1,1],padding='SAME')#卷积
bias2=tf.Variable(tf.constant(0.1,shape=[64]))#初始化参数
conv2=tf.nn.relu(tf.nn.bias_add(kernel2,bias2))#使用激活函数激活
# 使用LRN对结果进行处理
norm2=tf.nn.lrn(conv2,4,bias=0.1,alpha=0.001/9.0,beta=0.75)
# 使用尺寸3*3步长2*2的最大池化层处理数据,这里最大池化的尺寸和步长不一样,可以增加数据的丰富性
pool2=tf.nn.max_pool(norm2,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
#全连接层
#使用tf.reshape函数将每个样本都变成一维向量,使用get_shape函数获取数据扁平化之后的长度
reshape=tf.reshape(pool2,[batch_size,-1])
dim=reshape.get_shape()[1].value
# 接着初始化权值,隐含节点384个,正太分布的标准差设为0.04,bias的值也初始化为0.1
# 注意这里我们希望这个全连接层不要过拟合,因此设了一个非零的weight loss值0.04,让这一层具有L2正则所约束。
weight3=variable_with_weight_loss(shape=[dim,384],stddev=0.04,w1=0.004)
bias3=tf.Variable(tf.constant(0.1,shape=[384]))#写0.1是为了Relu小于0时全为0,所以给0.1不至于成为死亡神经元
# 最后我们依然使用ReLU激活函数进行非线性化
local3=tf.nn.relu(tf.matmul(reshape,weight3)+bias3)
#第二个全连接层
weight4=variable_with_weight_loss(shape=[384,192],stddev=1/192.0,w1=0.0)
bias4=tf.Variable(tf.constant(0.0,shape=[192]))
local4=tf.nn.relu(tf.matmul(local3,weight4)+bias4)
#最后一层(输出层)
weight5=variable_with_weight_loss(shape=[192,10],stddev=1/192.0,w1=0.0)
bias5=tf.Variable(tf.constant(0.0,shape=[10]))
logits=tf.add(tf.matmul(local4,weight5),bias5)
#定义loss函数
def loss(logits,labels):
labels=tf.cast(labels,tf.int64)
#把softmax的计算和cross_entropy的计算合在了一起
cross_entropy=tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=logits,labels=labels,name='cross_entropy_per_example')
#对 cross entropy计算均值
cross_entropy_mean=tf.reduce_mean(cross_entropy,name='cross_entropy')
#使用tf.add_n将整体losses的collection集合中的全部loss求和,得到最终的loss
tf.add_to_collection('losses',cross_entropy_mean)
return tf.add_n(tf.get_collection('losses'),name='total_loss')
loss=loss(logits,labels_holder)#logits输出的结果
train_op=tf.train.AdamOptimizer(1e-3).minimize(loss)
# 使用 tf.nn.in_top_k()函数求输出结果中 top k的准确率,默认使用top 1,也就是输出分数最高的那一类的准确率
top_k_op=tf.nn.in_top_k(logits,labels_holder,1)
sess=tf.InteractiveSession()
tf.global_variables_initializer().run()
# 启动图片数据增强的线程队列,这里一共使用了16个线程来进行加速,如果不启动线程,那么后续inference以及训练的操作都是无法开始的
tf.train.start_queue_runners()
#训练
for step in range(max_step):
start_time=time.time()
image_batch,label_batch=sess.run([images_train,labels_train])
_,loss_value=sess.run([train_op,loss],
feed_dict={image_holder:image_batch,labels_holder:label_batch})
duration=time.time()-start_time
if step %10 == 0:
examples_per_sec=batch_size/duration
sec_per_batch=float(duration)
format_str=('step %d,loss=%.2f(%.1f examples/sec;%.3f sec/batch)')
print(format_str%(step,loss_value,examples_per_sec,sec_per_batch))
#评测模型在测试集上的准确率
num_examples=10000
num_iter=int(math.ceil(num_examples/batch_size))
true_count=0
total_sample_count=num_iter*batch_size
step=0
while step