【知识图谱】——8种Trans模型
知识图谱对实体和它们丰富的关系的结构化信息编码。虽然一个典型的知识图谱可能得到数百万的实体和数以亿计的关系事实,但离补全还很远。知识图谱补全旨在通过现有知识图谱来预测实体之间的关系。知识图谱补全能够找到新的关系事实,这是对从纯文本进行关系抽取的重要补充。知识图谱扫盲:https://www.jiqizhixin.com/articles/2018-06-20-4
在社交网络分析上,知识图谱补全和链接预测很相似,但是由于以下原因知识图谱补有更多的挑战:
(1)知识图谱中的实体具有不同的类型和属性;
(2)知识图谱中的关系具有不同的类型。对于知识图谱补全,我们不仅要判断两个实体之间是否有关系,而且还要预测关系的具体类型。
由于这个原因,传统的链接预测的方法并不能胜任知识图谱补全。近年来,一种很有前景的方法被应用到知识图谱补全,它将知识图谱嵌入到一个连续的向量空间并且保留一定的图中的信息。
下面介绍对知识图谱向量化表示的八种模型做一个介绍:
1、TransE模型
Translating embeddings for modeling multi-relational data
Bordes A, Usunier N, Weston J, et al. NIPS. 2013.
写作动机
之前像 single layer model 以及 NTN 等传统方法,存在着训练复杂和不易拓展等问题。本文提出了一种将实体与关系嵌入到低维向量空间中的简单模型 TransE。该模型已经成为了知识图谱向量化表示的 baseline,并衍生出不同的变体。

正如目标函数所述,算法核心是令正例的 h+r-l 趋近于 0,而负例的 h+r-l 趋近于无穷大,这里的 d 表示 L1 或 L2 范式, \gamma 表示边际距离。整个 TransE 模型的训练过程比较简单,首先对头尾节点以及关系进行初始化,然后每对一个正例取一个负例样本(本文负例选取方式为固定中间的 relation,头尾节点任意替换一个),然后利用 hinge loss function 尽可能使正例和负例分开,最后采用 SGD 方法更新参数。
2、TransH模型
Knowledge Graph Embedding by Translating on Hyperplanes
Wang Z, Zhang J, Feng J, et al. AAAI. 2014.
写作动机
虽然 TransE 模型具有训练速度快、易于实现等优点,但是它不能够解决多对一和一对多关系的问题。以多对一关系为例,固定 r 和 t,TransE 模型为了满足三角闭包关系,训练出来的头节点的向量会很相似。而本文提出一种将头尾节点映射到关系平面的 TransH 模型,能够很好地解决这一问题。
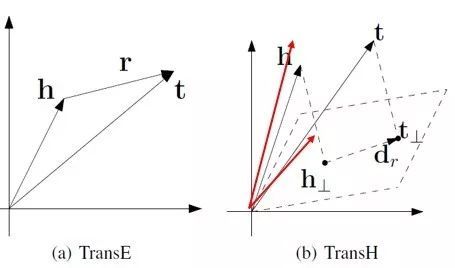
以下图为例,对于多对一关系,TransH 不在严格要求 h+r-l=0,而是只需要保证头结点和尾节点在关系平面上的投影在一条直线上即可,因此能够得到图中头结点向量(红线)正确的表示。
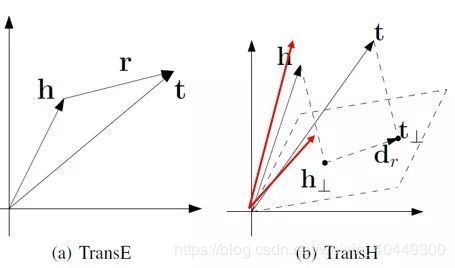
模型
![]()
![]()
本文的模型其实比较简单,首先通过上述公式 1 分别将 head 和 tail 节点映射到关系 r 所对应的平面,之后整个训练方式同 TransE 一致。虽然 TransH 比 TransE 增加了一步向量转换,但其实整体参数只增加了 wr 一项,整体的算法效率还是很高的。
此外,不同于 TransE 模型随机替换 head 和 tail 节点作为负例的方法,本文分别赋给头结点和尾节点一个采样概率,具体计算公式计算如下:

即对于多对一的关系,替换尾节点,对于一对多的关系,替换头节点。
3、TransR模型
Learning Entity and Relation Embeddings for Knowledge Graph Completion
Lin Y, Liu Z, Zhu X, et al. AAAI. 2015.
写作动机
TransE 和 TransH 都假设实体和关系嵌入在相同的空间中。然而,一个实体是多种属性的综合体,不同关系对应实体的不同属性,即头尾节点和关系可能不在一个向量空间中。为了解决这个问题,本文提出了一种新的方法 TransR。
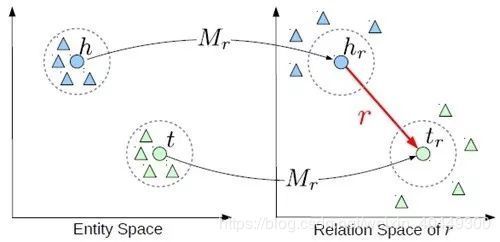
模型
TransR 的基本思想如上图所示。对于每个元组(h,r,t),首先将实体空间内的实体通过 Mr 矩阵投影到关系 r 所在的空间内,得到 hr 和 tr ,然后使 hr+t≈tr。特定的关系投影(彩色的圆圈表示)能够使得头/尾实体在这个关系下靠近彼此,使得不具有此关系(彩色的三角形表示)的实体彼此远离。
此外,仅仅通过单个的关系向量还不足以建立从头实体到尾实体的所有转移,即对于同一条关系 r 来讲,r 具有多种语义上的表示。本文提出对不同的头尾实体进行聚类和并且学习到关系在不同聚类簇的表示。作者这里首先利用 TransE 预训练(h,r,t)三元组,并且对 t-h(也就是关系 r)进行聚类,这样对于关系 r 来讲,头尾节点会被分到相应的簇中,并且利用下面的公式进行训练,该方法也被称为 CTransR。
![]()
4、TransD模型
Learning Entity and Relation Embeddings for Knowledge Graph Completion
Lin Y, Liu Z, Zhu X, et al. AAAI. 2015.
写作动机
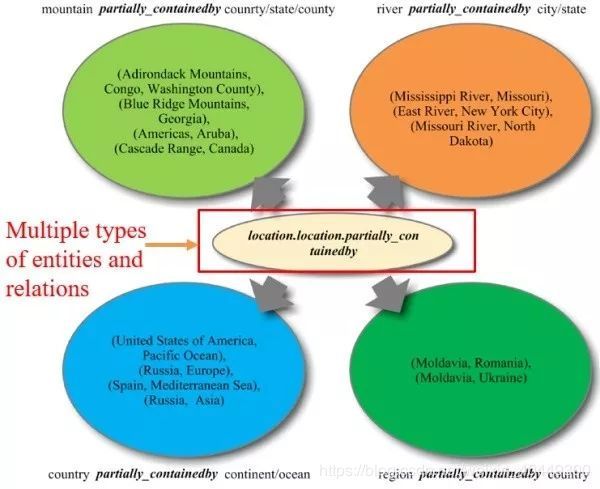
之前的 TransE、TransH 和 TransR 都认为每种关系只对应一种语义表示,而在实际情况中,关系r可能代表不同的含义。如下图所示,对于关系 location 来讲,它既可以表示山脉-国家之间的关系,又可以表示为地区-国家之间的关系,因此本文提出一种基于动态矩阵的 TransD 模型来解决这一问题。
模型
TransD 模型同 CTransR 模型一样,都是为了解决关系的多种语义表示。相比较 CTransR 采用聚类的方式,TransD 提出一种动态变化矩阵的方法。具体公式如下图所示:
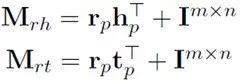
![]()
![]()
对于(h',r',t')两个实体和一种关系来讲,它们分别有两种表示,一种是构建映射矩阵的表示(hp,rp,tp),另外一种是自身的语义表示(h,r,t)。h 和 t 的动态转移矩阵分别由其自身的映射矩阵和关系r的映射矩阵所决定,而不是像 TransR 一样映射矩阵只和关系 r 相关。
此外,该模型的一个亮点在于它将 TransR 的矩阵运算转换成了向量间的运算,运算速度会大幅提升,具体公式如下:
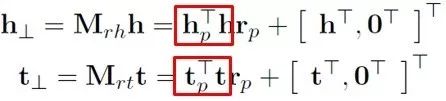
5、TransA模型
TransA: An Adaptive Approach for Knowledge Graph Embedding
Xiao H, Huang M, Hao Y, et al. Computer Science. 2015.
写作动机
TransE 从根本上讲是一种欧式距离的计算,其图形对应的是一个圆,从下图可知蓝色部分为正例,红色部分为负例,TransE 模型划分错了七个点。而本文提出了一种基于马氏距离的 TransA 模型,其 PCA 降维图形对应的是一个椭圆,该模型只分错了三个点。
此外,之前的方法将等价对待向量中的每一维,但实际上各个维度的重要性是不同的,只有一些维度是有效的,而某些维度被认为是噪音,会降低效果。
如下图 2 所示,对于关系 haspart 而言,TransE 模型根据欧氏距离计算方法生成了像 Room-has-Goniff 这样的三元组,而正确的结果却是 Room-has-Wall。我们对 x,y 轴进行分解,发现 Room 在 x 轴上距离 Wall 更为相近,因此我们可以认为该图在 x 轴维度上更加重要。TransA 模型通过引入加权矩阵,赋给每一维度权重。

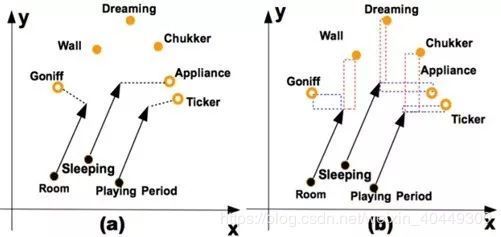
模型
其实 TransA 模型总体来看比较简单,相比较 TransE 模型,本文引入了 Wr 矩阵为不同维度的向量进行加权,并利用 LDL 方法对 Wr 进行分解,Dr 是一个对角阵,对角线上的元素表示不同维度上的权重。本篇文章的一个亮点在于通过图像来描述不同的损失度量函数,给人直观的感觉。
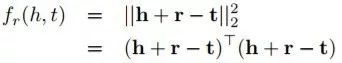
6、TransG模型
TransG: A Generative Mixture Model for Knowledge Graph Embedding
Xiao H, Huang M, Zhu X. TransG. ACL. 2016.
写作动机
本文提出的 TransG 模型同 CTransR、TransD 一致,都是为了解决关系的多种语义表达问题。作者首先做了一个比较有意思的实验,首先对预训练好的 t-h 进行聚类(也就是关系 r),发现对于每种关系 r 来讲,会得到不同的簇。从现实意义来看也不难理解,对于关系 Country,我们可以聚类得到美国、欧洲和其他国家这三个簇,表示电影所属的不同国家。
模型
TransG 利用贝叶斯非参数混合模型对一个关系生成多个表示,其实 TransG 的本质同 CTransR 一致,都是利用聚类方法生成 r 的不同种表示。不同点在于 CTransR 利用预训练的 TransE 向量进行聚类,而 TransG 采用边训练边聚类的方法。具体公式如下:
M 表示聚类的数目,πr,m 表示关系 r 的第 m 中表示的权重。
7、Transparse模型
Knowledge Graph Completion with Adaptive Sparse Transfer Matrix
Ji G, Liu K, He S, et al. AAAI. 2016.
写作动机
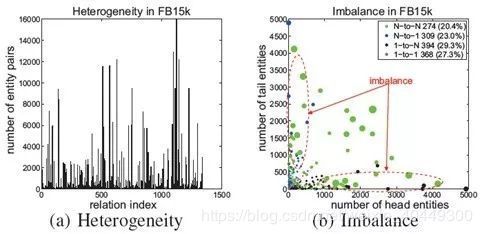
Knowledge Graph 中面临的两个主要问题,分别是 heterogeneous(异构性)和 unbalanced(不平衡性)。
异构性表示知识图谱中关系所连接的节点数目差异较大,不平衡性表示关系所连接的头尾节点数目不同。如果只用一个模型处理所有关系的话可能会导致对简单关系过拟合,对复杂关系欠拟合。本文提出两种模型 Transparse (share) 和 Transparse (separate) 分别解决这两个问题。
模型
Transparse 模型本质是 TransR 模型的扩展,区别在于对于那些复杂的关系令其转移矩阵稠密,而对于简单的关系令其转移矩阵稀疏。这个稀疏程度由 θr 控制,具体计算公式如下:
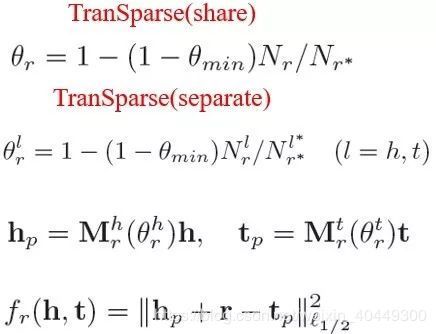
θmin 表示 0-1 之间的一个控制变量,Nr 表示关系 r 连接实体对的数量,Nr* 表示其中连接的最大值,同理 ![]() 表示关系 r 连接的头\尾实体数,
表示关系 r 连接的头\尾实体数,![]() 表示其中的最大值。
表示其中的最大值。
share 和separate 的区别在于 separate 模型为 head 和 tail 提供了两种不同的转移矩阵,而 share 模型 head 和 tail 的转移矩阵相同,具体公式如下所述:
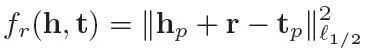
![]()
该篇文章的亮点在于针对知识图谱存在的异构性和不平衡性问题,作者分别提出两种不同的模型来解决,但缺陷是作者并没有将这两种模型进行融合,最后在 triplet classification 和 link prediction 上的结果并没有比 TransD 提升很多。
8、TransA+模型
Locally Adaptive Translation for Knowledge Graph Embedding
Jia Y, Wang Y, Lin H, et al. AAAI, 2016.
写作动机
之前所有模型的 margin 都是固定不变的,但局部不同的 margin 是否能够提升模型的效果呢?作者为了证明,首先做了一组实验,将 FB15K 分成两个子集,在不同数据集上分别得到达到最优效果的 margin,发现局部最优的 margin 不尽相同。
从理论来讲,Margin 变大,更多的数据被训练,容易导致过拟合。相反,margin 越小,容易欠拟合。所以也证明了 margin 对最终结果的影响。

模型
本文将 margin 分为 entity 和 relation 两部分,并利用线性插值进行组合。实体部分的 margin 应保证内层圆包含更多的正例,外层圆的外部应尽可能是负例。对于 relation 部分,本文利用 relation 的长度,即 L2 范式来衡量相似度关系。具体公式如下图所示:
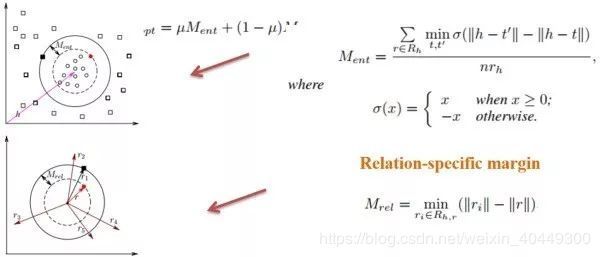
Rh,r 是除了关系 r 之外的所有关系的集合,它使得所有与关系 r 不相近的关系远离 r。本篇文章比较巧妙地利用局部 margin 的方式,在 link prediction 和 triple classification 结果上有了明显提升。
参考文献:
- Bordes A, Usunier N, Weston J, et al. Translating embeddings for modeling multi-relational data. NIPS. 2013.
- Wang Z, Zhang J, Feng J, et al. Knowledge Graph Embedding by Translating on Hyperplanes. AAAI. 2014.
- Lin Y, Liu Z, Zhu X, et al. Learning Entity and Relation Embeddings for Knowledge Graph Completion. AAAI. 2015.
- Lin Y, Liu Z, Zhu X, et al.Learning Entity and Relation Embeddings for Knowledge Graph Completion. AAAI. 2015.
- Xiao H, Huang M, Hao Y, et al. TransA: An Adaptive Approach for Knowledge Graph Embedding. Computer Science. 2015.
- Xiao H, Huang M, Zhu X. TransG: A Generative Mixture Model for Knowledge Graph Embedding. ACL. 2016.
- Ji G, Liu K, He S, et al. Knowledge Graph Completion with Adaptive Sparse Transfer Matrix. AAAI. 2016.
- Jia Y, Wang Y, Lin H, et al. Locally Adaptive Translation for Knowledge Graph Embedding. AAAI, 2016.