机器学习-西瓜书
章节目录
- 序章
- 线性回归
- 多分类学习
- 神经网络
- 支持向量机(SVM)
- 贝叶斯分类器
- 集成学习
序章
什么是机器学习?
机器学习是将人类的学习方法运用到计算机上,用一系列算法让计算机从有限的数据集(样本)中生成一种模型,来预测同类事件(整个样本空间)的输出。
从数据中获得模型的过程成为“学习”或“训练”,训练过程所使用的数据成为“训练数据”,每个样本称为“训练样本”,训练样本组成的集合称为“训练集”。
训练样本的结果称为“标记(label)”,在监督学习中,有两种学习任务,一个是“分类”(离散的预测),另一个是“回归”(连续的预测值)。
除了“监督学习”,另一种学习任务是“无监督学习”,训练样本没有label信息,“聚类”是其代表。
学习得到的模型不仅能用于训练样本,还能很好地适用于样本空间,这就是模型的“泛化”能力。
学习过程中有可能得到多个与训练集一致的“假设集合”,称为“版本空间”。(通过偏好得唯一结果)
机器学习算法在学习过程中对某种类型假设的偏好称为“归纳偏好”或“偏好”。
过拟合:
学习过程中把训练样本的特殊属性当成所有样本都潜在拥有的属性,导致泛化性能下降。
欠拟合:
对训练样本的一般性质尚未学好。

测试集:
用来测试模型的泛化能力的带有label的示例。
从示例中分出训练集和测试集的三种方法:
1.留出法:直接将数据集D划分为两个互斥的集合。
2.交叉验证法:将数据集D随机分成k个互斥子集,1-k个子集作为训练集,1个子集作为测试集。进行p次训练后取训练结果的平均值。 ”留一法“:一个子集一个样本。
3.自助法:假设m次中每次从D中随机出一个样本放进D’,然后再将该样本放进D中。进行m次之后没有在D’中的样本作为测试集,D’作为训练集。该方法适用于数据量较小的情况。
性能度量:
对模型的泛化能力的评估不仅要采取有效可行的实验估计方法,还需要一个评判标准,叫做“性能度量”反映了任务需求。不同的性能对模型的评判结果不同,也就是说,模型的“好坏”是相对的,在于性能度量怎么取。
回归任务最常用的性能度量是均方误差(mean squared error)


查准率:

查全率:

调和平均:

代价敏感错误率与代价曲线

在非均等代价下,强调的不是最小化错误次数,而是最小化总体代价
代价敏感错误率:

代价曲线:
横轴:正例概率代价 p是样例为正例的概率

纵轴:归一化代价


假设检验:
对模型泛化错误率分布的猜想
、
、
线性回归
线性模型
试图学得一个通过属性的线性组合来进行预测的函数

向量形式:

线性回归

用均方误差来度量线性回归任务,让其最小化
对于分类任务,采取对数几率回归函数表示:

转换成


线性判别分析

多分类学习
1.将多分类任务拆分为若干个二分类任务求解
2.将多个二分类的预测结果集成

决策树:
信息熵表示样本纯度,值越小,纯度越高

属性a对样本集D进行划分所获得的信息增益。信息增益越大意味着用用属性a来进行划分所获得的“纯度提升”越大

数据集D的纯度也可以用基尼指数来选择划分属性

属性a的基尼指数

剪枝是对付决策树学习算法过拟合的手段
预剪枝是在决策树生成过程中,对结点进行划分的时候先评估划分该结点能否提高泛化能力,若不行,将该结点标记为叶结点
后剪枝是在决策树生成之后自底向上地对每个非叶结点进行考察,若将该结点对应的字数替换成叶子能提高决策树的泛化能力,则将该子树替换成叶子
决策树对连续值的处理:
原理是选择某两个相邻点的值取平均值,取n-1个平均值中使信息增益最大的那个值进行划分点

.
.
神经网络

多层前馈神经网络:
每层神经元与下一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接

神经网络的学习过程就是根据训练数据不断调整神经元之间的连接权和神经元的阈值
误逆差传播算法(BP算法)

深度学习就是有多隐层的神经网络
深度学习和单隐层网络不同,因为单隐层网络只有一层隐层来对输入层信息进行提取,难度很大。而深度学习通过多层处理,逐渐将“低层”特征转化为“高层”特征,用较简单的模型就可以完成复杂的学习任务。因此也可将其称为“特征学习”或“表示学习”。具有代表性深度学习模型是卷积神经网络(CNN)
.
.
支持向量机(SVM)

划分超平面可通过如下线性方程表示:

ω \omega ω为法向量,b是位移量

支持向量机(SVM)的基本型:(需用到拉格朗日乘子法)

核函数:
若原始空间不存在一个划分超平面,可将原始空间映射到更高维的特征空间,使得样本再这个特征空间内线性可分


软间隔
现实生活中很难找到核函数满足的超平面,软间隔允许向量机在一些样本上出错

.
.
贝叶斯分类器
对于一个多分类任务,找到一个适合的函数h使总体分类错误损失最小


h称为贝叶斯最优分类器,整体风险R(h)称为贝叶斯风险
误判损失

生成式模型

朴素贝叶斯分类器,基于每一个分类相互独立,对属性发生影响的思想

.
.
集成学习
集成学习通过构建并建立多个学习器来完成学习任务

T为基分类器的个数,集成错误率为

目前的集成学习方法大致分为两大类:
1.个体学习器间存在强依赖关系、必须串行生成的序列化方法(代表:Boosting)
2.个体学习器间不存在强依赖关系、可同时生成的并行化方法(代表:Random Forest)
Boosting


Bagging


随机森林




多个基学习器的集成方法

1)简单平均法

2)加权平均法(通常要求所有权值之和=1)
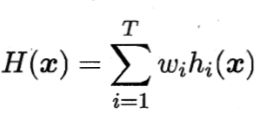
3)投票法


