tensorflow中crf模块函数解析
这篇博客主要想解释一下tensorflow中crf模块的几个函数的输入输出是什么意思。作为预备知识,建议英文好的同学先看下这篇博客,这篇博客有8个小节,前5个小节比较通俗易懂,后3个小节感觉不太理解。当然我也会先讲一下bilstm+crf的基本原理,主要讲一下模型的损失函数。
一、预备知识
首先说一下crf的输入是什么,crf的输入就是bilstm的输出,是一个三维矩阵,[batch_size,max_seq_len,num_tags],其中num_tags是命名实体识别中的标签个数。也就是每个sequence中的每个单词都会输出一个未经归一化的概率向量,向量长度是num_tags。
再说一下crf层的参数是什么,crf层的参数是一个状态转移矩阵(num_tags*num_tags),矩阵中的每个元素代表标签之间转移的概率。
最后说一下模型的损失函数,模型的损失函数就是由bilstm输出的三维矩阵P和状态转移矩阵A计算得到。公式如下。
公式1:
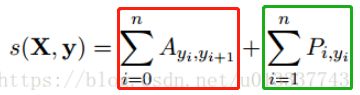
公式2:

s代表由sequence输入经过模型计算,得到某个标签序列的概率,最小化损失函数就是为了最大化真实标签序列的概率。
二、tensorflow中crf模块函数解析
<函数输入的解释>
tag_indices:[batch_size, max_seq_len],真实的标签序列;
sequence_lengths:[batch_size],每个序列的长度;
transition_params:[num_tags, num_tags] ,状态转移矩阵;
inputs/potentials:[batch_size, max_seq_len, num_tags],bilstm的输出,同时也是crf层的输入;
<函数的输入输出解释>
crf_binary_score(二元概率):
输入:tag_indices, sequence_lengths, transition_params
输出:[batch_size],向量中的每个元素是一个sequence中所有的转移概率加和,公式1中红色方框中的公式;
crf_unary_score(一元概率):
输入:tag_indices, sequence_lengths, inputs
输出:[batch_size],向量中的每个元素是一个sequence中所有的真实标签概率加和,公式1中绿色方框中的公式;
crf_sequence_score:
输入:inputs,tag_indices,sequence_lengths,transition_params
输出:[batch_size],向量中的每个元素是一个sequence的真实标签概率加和+所有的转移概率加和,即:crf_unary_score+crf_binary_score,公式2中红色方框中的公式;
crf_log_norm: 这个函数的实现比较复杂,tensorflow中的实现原理可参考这里,有兴趣的同学可以看一下。
输入:inputs,sequence_lengths,transition_params
输出:[batch_size],公式2中绿色方框中的公式;
crf_log_likelihood:
输入:inputs,tag_indices,sequence_lengths,
输出:
log_likelihood:[batch_size],向量中的每个元素为图二中红色方框中的公式减去绿色方框中的公式,也就是-logloss;
transition_params:[num_tags, num_tags] ,状态转移矩阵;
crf_decode: 这个函数用到了维特比算法。
输入:potentials,transition_params,sequence_length
输出:
decode_tags:[batch_size, max_seq_len],所有可能的输出序列中概率最大的那个序列;
best_score:[batch_size] ,概率最大的序列对应的序列概率;