NVIDIA之TLT迁移学习训练自己的数据集
0 背景
NVIDIA Transfer Learning Toolkit是英伟达推出的迁移学习工具包,使用提供的预训练模型来训练自己的数据,并可以完成模型裁剪、导出到deepstream框架中,实现快速部署。流程如下:

本文以训练faster rcnn为例,对TLT的使用方法进行介绍,并记录我在部署过程中踩过的那些(深)坑,如果你要训练其它模型,方法是类似的。参考资源
官网介绍:https://developer.nvidia.com/transfer-learning-toolkit
开发文档:https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/index.html
版本信息:v2.0_dp_py2,更新时间:2020年5月7日
注:2020.08.05 v2.0_py3版本更新,使用方法类似

1 安装方法
1.1 拉取镜像
TLT需要在docker中运行,因此第一步拉取镜像
首先登陆NGC,如果你是第一次注册NGC,你需要获得一个API KEY,这个值需要保存下来,因为他只会显示一次,并且以后会经常用到
docker login nvcr.io
# 用户名固定为 $oauthtoken
# 密码为你自己的API_KEY
docker pull nvcr.io/nvidia/tlt-streamanalytics:v2.0_dp_py2这个过程比较漫长,第一次拉完之后,如果有自己的镜像仓库,可以推送到本地镜像仓库,以后下载时就会快很多
1.2 启动容器
镜像下载好之后,启动容器
sudo nvidia-docker run --gpus 4 -it --name tlt -v /your/local/path/tlt-experiments/:/workspace/tlt-experiments -p 8888:8888 nvcr.io/nvidia/tlt-streamanalytics:v2.0_dp_py2:v2.0_dp_py2 /bin/bash
有几个点需要注意:
- --gpus要根据自己硬件条件设置,我这里有4张显卡可以用,就设置为4
- -v表示将自己本地目录/your/local/path/tlt-experiments/与容器中的/workspace/tlt-experiments目录绑定,这样方便拷贝我们的训练数据
1.3 修改entrypoint.sh文件
2.0DP版本的镜像有个bug,就是当你启动容器退出后无法再次进入,根据docker logs tlt可以看到报错信息是:
mkdir: cannot create directory ‘/opt/ngccli’: File exists(具体看参考论坛提问)
并且会重复下载ngccli_reg_linux.zip文件,这里的解决方法是注释掉相关代码,entrypoint.sh文件在进入容器后的上一级目录(cd ..)
#!/usr/bin/env bash
set -e
## Run startup command
#mkdir -p /opt/ngccli
#wget https://ngc.nvidia.com/downloads/ngccli_reg_linux.zip -P /opt/ngccli
#unzip -o /opt/ngccli/ngccli_reg_linux.zip -d /opt/ngccli/
#rm /opt/ngccli/*.zip
#chmod u+x /opt/ngccli/ngc
## Running passed command
if [[ "$1" ]]; then
eval "$@"
fi2.0GA版本对应的是修改 install_ngc_cli.sh脚本
#!/usr/bin/env bash
set -eo pipefail
# Select NGC CLI type based on command line arg
BATCH_CLI='ngccli_bat_linux.zip'
REG_CLI='ngccli_reg_linux.zip'
# Installing NGC CLI type based on env variable.
if [ "x$NGC_INSTALL_CLI" == 'xBATCH' ]; then
CLI="$BATCH_CLI"
elif [ "x$NGC_INSTALL_CLI" == 'xREGISTRY' ]; then
CLI="$REG_CLI"
else
echo "Invalid NGC_INSTALL_CLI asked for. Exiting"
exit 1
fi
## Download and install
#mkdir -p /opt/ngccli && \
#wget "https://ngc.nvidia.com/downloads/$CLI" -P /opt/ngccli && \
#unzip -u "/opt/ngccli/$CLI" -d /opt/ngccli/ && \
#rm /opt/ngccli/*.zip && \
#chmod u+x /opt/ngccli/ngc
## Running passed command
if [[ "$1" ]]; then
eval "$@"
fi
2 准备数据集
接下来准备我们的训练数据,数据集的要求如下:

tlt-train不支持多分辨率图片的训练,需要将图片resize到统一大小,同时要对应的更改lable。官方建议图片的宽高应为16的整数倍,例如1920x1080
- 图片resize的方法可以参考下边的代码
def resize_img(img_path, save_path, img_size):
w = img_size[0]
h = img_size[1]
img_list = os.listdir(img_path)
for i in img_list:
if i.endswith('.jpg'):
img_array = cv2.imread((img_path + '/' + i), cv2.IMREAD_COLOR)
new_array = cv2.resize(img_array, (w, h), interpolation=cv2.INTER_CUBIC)
img_name = str(i)
if os.path.exists(save_path):
print(i)
save_img = save_path + img_name
cv2.imwrite(save_img, new_array)
else:
os.mkdir(save_path)
save_img = save_path + img_name
cv2.imwrite(save_img, new_array)- 提供一个label resize的思路:先将xml中的xmin\ymin\xmax\ymax进行归一化保存,然后再乘以新的长宽即可
2.1 label转换
TLT的训练标注数据需要用KITTI数据集格式,所以如果你的数据集是其它格式的,需要做一个转化,这里我们提供VOC数据集和coco数据集的转化方法
2.1.1 voc数据集转换方法
import xml.etree.ElementTree as ET
import os
base_xml_dir = "./vocdata/Annotations/"
xml_list = os.listdir(base_xml_dir)
kitti_saved_dir = "./kitti/kitti_txt/"
def convert_annotation(file_name):
in_file = open(base_xml_dir + file_name)
tree = ET.parse(in_file)
root = tree.getroot()
with open(kitti_saved_dir + file_name[:-4] + '.txt', 'w') as f:
for obj in root.iter('object'):
cls = obj.find('name').text
xmlbox = obj.find('bndbox')
xmin, ymin, xmax, ymax = xmlbox.find('xmin').text, xmlbox.find('ymin').text, \
xmlbox.find('xmax').text, xmlbox.find('ymax').text
f.write(cls + " " + '0' + " " + '0' + " " + '0' + " " + str(xmin) + '.0' + " "
+ str(ymin) + '.0' + " " + str(xmax) + '.0' + " " + str(ymax) + '.0' + " " +
'0' + " " + '0' + " " + '0' + " " + '0' + " " + '0' + " " + '0' + " " + '0' + '\n')
for i in xml_list:
convert_annotation(i)
2.1.2 coco数据集转换方法
def coco2kitti(coco_path, kitti_path, classes):
width = 1280
height = 720
# 创建保存结果的文件夹
if not os.path.exists(kitti_path):
os.mkdir(kitti_path)
for root, _, files in os.walk(coco_path):
for file in files:
filename, extension = os.path.splitext(file)
print("------------------"+file+"------------------")
if extension == '.txt':
file_path = os.path.join(root, file)
out_file = open(kitti_path + '%s.txt'%(filename), 'w')
with open(file_path, "r") as fr:
lines = fr.readlines()
for line in lines:
data = line.split(" ")
try:
class_id = int(data[0])
x = float(data[1])
y = float(data[2])
w = float(data[3])
h = float(data[4])
except:
print(file + 'is wrong')
os.remove(file_path)
# 删除有问题的label
# os.remove(img_path + '%s.jpg'%(filename))
os.remove(kitti_path + '%s.txt'%(filename))
continue
Xmax = (2*x*width + w* width) / 2
Xmin = (2*x*width - w* width) / 2
Ymax = (2*y*height + h* height) / 2
Ymin = (2*y*height - h* height) / 2
bb = (round(Xmin, 2), round(Ymin, 2), round(Xmax, 2), round(Ymax, 2))
print(bb)
out_file.write(classes[class_id] + " 0 0 0 " + " ".join([str(a) for a in bb]) + " 0 0 0 0 0 0 0" + '\n')2.2 创建目录
按照下边的目录结构创建各级目录(用下边的目录名字配置文件改动最少)
└── tlt-experiments
├── data
│ ├── faster_rcnn
│ ├── testing
│ │ └── image_2
│ └── training
│ ├── image_2
│ └── label_2
└── tfrecords
└── kitti_trainval
创建完文件夹后,将自己的训练图片和对应的KITTI标签放到training目录对应位置,在testing文件夹中放入测试图片
3 模型训练
TLT提供了很多jupyter notebook文件,将运行的命令都封装起来了,我们直接使用这些文件来进行训练就可以,当然也可以在容器中自己敲命令来训练。
进入容器中后,在workspace路径下,运行下边的启动命令
jupyter notebook --ip 0.0.0.0 --allow-root然后根据token,在自己的浏览器中打开对应的IP和端口,打开后内容如下

3.1 环境设置
我们依次点击examples/faster_rcnn/faster_rcnn.ipynb,进入jupyter文件,如下
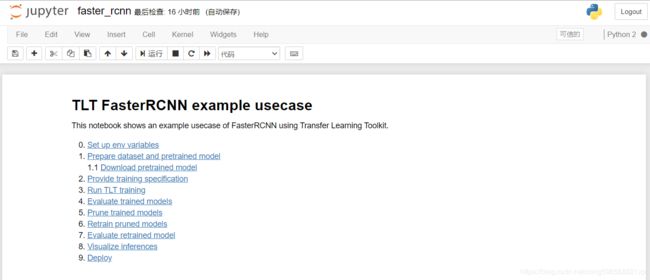
将第0步中KEY的值替换为自己的KEY值,获取方法参考1.1步骤,然后运行这个cell,就会输出运行结果
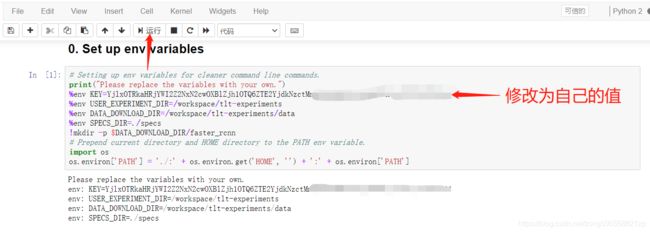
下边的第1步是下载KITTI数据集,因为我们准备了自己的数据集,这一步可以跳过不运行,为了防止出错,可以把cell中的代码全部注释掉,如下

3.2 生成tfrecords
接下来的步骤是生成tfrecords文件,首先需要修改tfrecords spec文件,这个文件里配置了数据集的位置信息
依次点击打开examples/faster_rcnn/specs/frcnn_tfrecords_kitti_trainval.txt文件,然后修改里边的值,如果你按照我上边的方法创建了文件夹,路径那些都不需要修改,如果你的图片是jpg格式,则只需要把imge_extension改一下,如下

其它都使用默认即可,修改完之后ctrl + s 保存一下,回到faster_rcnn的jupyter文件
依次运行接下来的两个cell
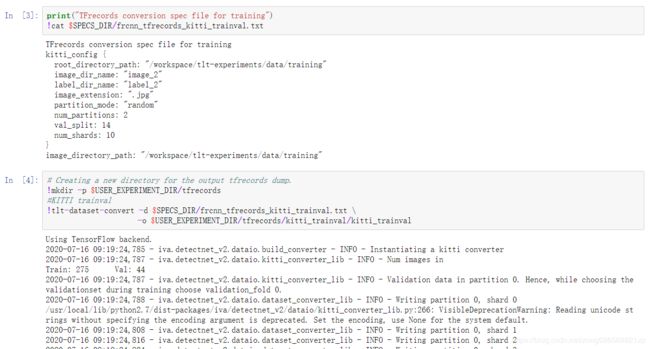
接下来你可以显示你生成的tfrecords文件

3.3 预训练模型
jupyter中提供了预训练模型的下载方法,但速度比较慢,我们注释掉,直接从NGC中手动下载
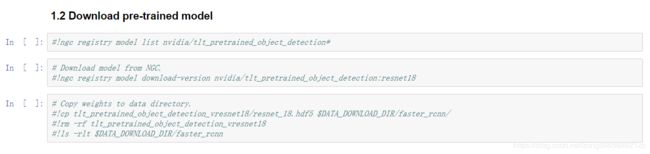
进入NGC官网,选择MODELS中的TLT Object Detection

进入后选择File Browser,选择自己要训练的预训练模型,这里我们选择的是RESNET 50,然后点击下载到本地
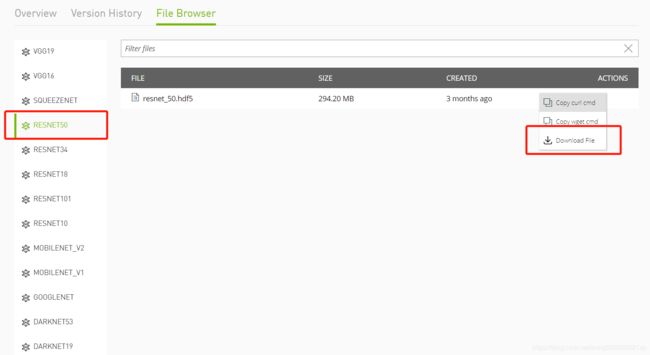
下载完后,拷贝到/workspace/tlt-experiments/data/faster_rcnn路径下,并重命名为resnet50.hdf5,至此预训练模型准备完毕
3.4 训练配置文件
打开faster_rcnn/specs下边的default_spec_resnet50.txt文件,从上到下依次有下边内容需要修改:
- size_height_width中的height和width修改为自己图片的实际值
- image_extension修改为jpg
- target_class_mapping要修改为自己的类别,将key和value一一对应,比如我自己的类别是bicycle和motorbike,则改成下边的内容
target_class_mapping {
key: 'bicycle'
value: 'bicycle'
}
target_class_mapping {
key: 'motorbike'
value: 'motorbike'
}
- output_image_width和output_image_height修改为自己图片的实际值
- batch_size_per_gpu:根据自己显卡情况设置,如果显存不大,可以设成较小值,比如设成1或4
- num_epochs:训练回合数,根据经验100-200可以有一个好的效果,太小了什么也检测不出来,我自己设成了200
- freeze_bn:默认为True,当你的batch size大于16的时候可以设置为False,让BN层自动计算均值和偏差
- checkpoint_interval:设置训练过程中保存模型的间隔,默认为1,可以根据自己需求调整
- inference_config/model修改为/workspace/tlt-experiments/data/faster_rcnn/frcnn_kitti_resnet50.epoch200.tlt
- evaluation_config/model修改为/workspace/tlt-experiments/data/faster_rcnn/frcnn_kitti_resnet50.epoch200.tlt
保存退出
要指定验证数据,请使用validation_fold,同时指定validation_data_source
validation_fold: 0
# For evaluation on test set
# validation_data_source: {
# tfrecords_path: "/path/to/test_tfrecords/*"
# image_directory_path: "/path/to/test_root"
# }3.5 开始训练
使用tlt-train指令开始训练,注意要改成自己的配置文件,如果有多个GPU的话,可以指定使用的GPU个数,默认为1
为了避免出现显存报错问题,训练前先设置下环境变量:
$ export TF_FORCE_GPU_ALLOW_GROWTH=true
3.6 检测模型
经过漫长的等待,训练结束后,可以验证以下自己的模型效果

会输出每个类别的AP值以及mAP值,如果模型效果不错的话可以进行裁剪,如果mAP值很低,或者直接 mAP = 0的话,说明训练有问题,需要检查下自己的配置文件重新训练
4 模型优化
经过上述步骤,我们得到了一个检测效果不错的模型,但不会直接拿来部署,而是需要prune裁剪一下,然后第二次训练,得到最终模型
4.1 模型剪枝
使用tlt-prune指令对模型进行剪枝

4.2 重新训练
首先宝贝一份specs/default_spec_resnet18_retrain_spec.txt为default_spec_resnet50_retrain_spec.txt,然后打开做几处修改,和3.4中修改的内容类似,额外需要修改下边的内容
- feature_extractor修改为resnet:50
- num_epochs可以设置的比第一阶段小一些,我这里设置了100
- 对应的把inference_config和evaluation_config中的model修改为/workspace/tlt-experiments/data/faster_rcnn/frcnn_kitti_resnet50_retrain.epoch100.tlt
- 把全文resnet18的地方都替换为resnet50
然后可以开始训练
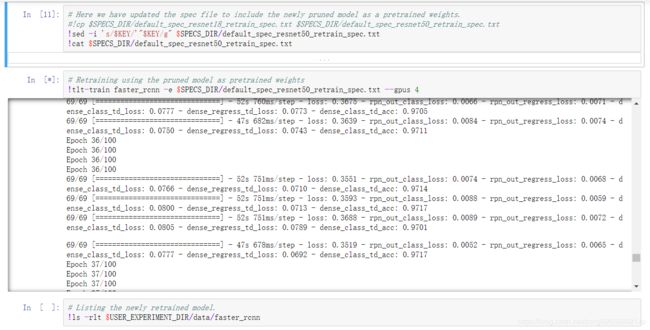
训练完之后,同样可以使用tlt-evaluate来计算一下模型的mAP,看看与未剪枝的模型相比是否有大的下降
4.3 可视化结果
可以使用tlt-infer工具对模型的检测效果进行可视化,运行后会输出两个文件夹,分别是faster_rcnn/inference_results_imgs_retrain和faster_rcnn/inference_dump_labels_retrain,用来保存检测结果图片和标签

当然也可以运行未剪枝的配置文件来检测未剪枝模型的检测效果
5 模型部署
TLT支持两种类型的模型导出,分别是etlt格式和engine格式,都可以用在deepstream中,但是engine是平台相关的,跟cuda、tensorrt等版本相关,所以如果部署的平台与训练的平台环境有差异,不建议直接导出engine使用,而是导出etlt模型,然后在deepstream中自动生成engine。
5.1 导出etlt模型
支持导出三种精度的模型,分别是FP32/FP16/INT8,如果要生成INT8模型,还需要生成一个量化表calibration cache file,具体方法如下

实际上,无论选择的是哪种类型(FP32/FP16/INT8),导出的模型都是相同大小的,类型都是FP32,只不过如果选择INT8的时候,会额外生成INT8 calibration table。(来源)

5.2 导出engine模型
也可以直接导出tensorrt的engine模型,方法如下
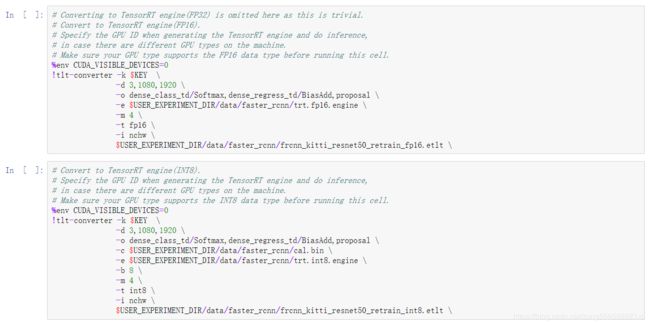
5.3 模型推理
可以使用上述的模型进行推理,计算mAP值,方法如下

5.4 deepstream部署
导出的这些模型可以直接在deepstream中进行部署,关于具体的部署方法,参考另一篇文章《DeepStream5.0系列之TLT模型调用》。
6 问题记录
6.1 XLA_GPU_JIT错误
tensorflow.python.framework.errors_impl.InvalidArgumentError: Invalid device ordinal value (5). Valid range is [0, 4].
while setting up XLA_GPU_JIT device number 5实际可用GPU与docker指定GPU不符,例如启动docker时指定--gpus all,而运行时第5张卡被占用无法使用,就会报错,
同样的,如果你指定一张不存在的GPU,比如只有gpu0,而你指定了--gpus 2则会报类似的错
6.2 类别问题
ValueError: Layer #206 (named "dense_class_td"), weight has shape (2048, 8), but the saved weight has shape (2048, 7). 6.3 OOM问题
tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[1,128,120,160] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[{{node b3_conv4_1_bn/batchnorm/mul_1}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[[{{node loss/dense_regress_td_loss/cond_3/Min/Switch}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.这个是显存不足导致的,将batch设置的小一些即可,注意TLT的GPU默认从0号开始,所以指定多GPU的时候,显卡不要有其它任务,否则也容易报显存不足问题
6.4 datasize问题
tensorflow.python.framework.errors_impl.InvalidArgumentError: Invalid JPEG data or crop window, data size 688128首先检查图片有没有问题,然后图片需要resize到统一大小,不支持不同分辨率的图片一起训练,同时要注意标签要一起修改

6.5 loss nan问题
训练开始时,如果报错Invalid loss, terminating training,则需要调整学习率