深度学习笔记(十五)---生成对抗GAN
目录
1.摘要
2.GAN原理介绍
2.1 网络概况
2.1.1 Discriminator Network
2.1.2 Generator Network
2.2 数学理解
3.代码实现
1.摘要
前面学习的自动编码器和变分自动编码器都是通过计算生成图像和输入图像在每个像素点的误差来生成 loss,这样就会造成,因为不同的像素点可能造成不同的视觉结果,但是可能他们的 loss 是相同的,所以通过单个像素点来得到 loss 是不准确的,那么生成对抗网络就应运而生!
2.GAN原理介绍
2.1 网络概况
网络是由两部分组成的,第一部分是生成,第二部分是对抗。简单来说,就是有一个生成网络和一个判别网络,通过训练让两个网络相互竞争,生成网络来生成假的数据,对抗网络通过判别器去判别真伪,最后希望生成器生成的数据能够以假乱真。
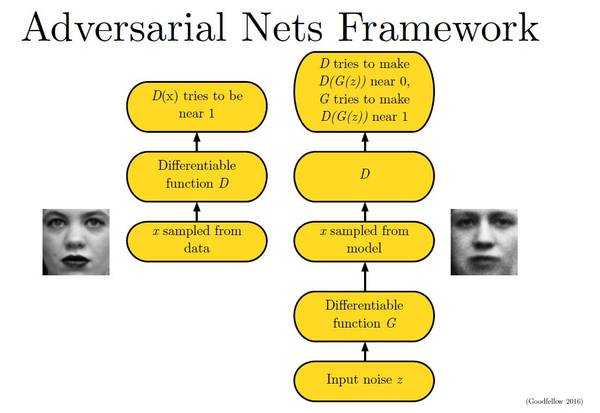
可以用这个图来简单的看一看这两个过程
2.1.1 Discriminator Network
对抗过程简单来说就是一个判断真假的判别器,相当于一个二分类问题,我们输入一张真的图片希望判别器输出的结果是1,输入一张假的图片希望判别器输出的结果是0。这其实已经和原图片的 label 没有关系了,不管原图片到底是一个多少类别的图片,他们都统一称为真的图片,label 是 1 表示真实的;而生成的假的图片的 label 是 0 表示假的。
我们训练的过程就是希望这个判别器能够正确的判出真的图片和假的图片,这其实就是一个简单的二分类问题,对于这个问题可以用我们前面讲过的很多方法去处理,比如 logistic 回归,深层网络,卷积神经网络,循环神经网络都可以。
2.1.2 Generator Network
接着我们看看生成网络如何生成一张假的图片。首先给出一个简单的高维的正态分布的噪声向量,如上图所示的 D-dimensional noise vector,这个时候我们可以通过仿射变换,也就是 xw+b 将其映射到一个更高的维度,然后将他重新排列成一个矩形,这样看着更像一张图片,接着进行一些卷积、转置卷积、池化、激活函数等进行处理,最后得到了一个与我们输入图片大小一模一样的噪音矩阵,这就是我们所说的假的图片。
这个时候我们如何去训练这个生成器呢?这就需要通过对抗学习,增大判别器判别这个结果为真的概率,通过这个步骤不断调整生成器的参数,希望生成的图片越来越像真的,而在这一步中我们不会更新判别器的参数,因为如果判别器不断被优化,可能生成器无论生成什么样的图片都无法骗过判别器。
生成器的效果可以看看下面的图示
2.2 数学理解
在GAN中,我们用NN的参数表示PG的参数θ:
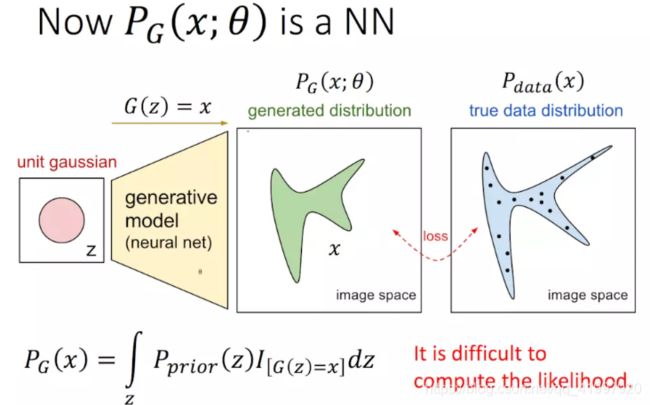
那么 ,GAN的基本原理如下:

最终的求解目标是:
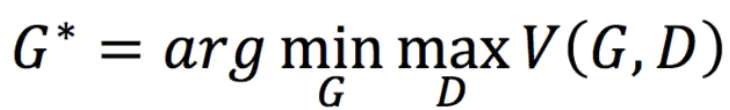
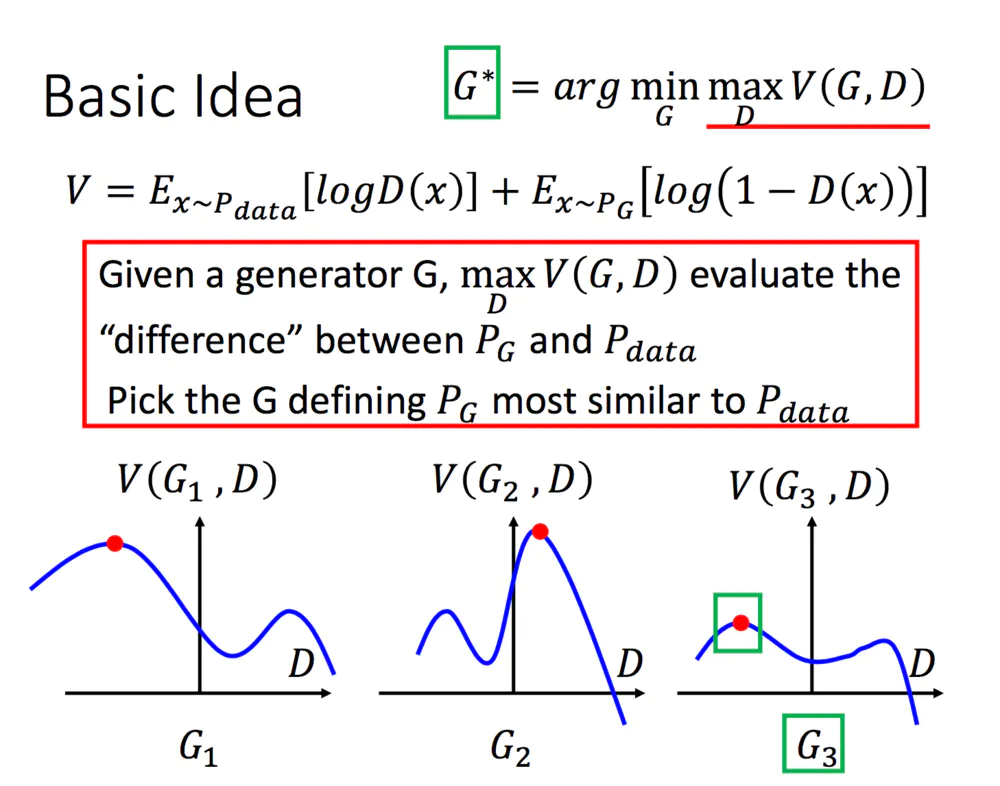
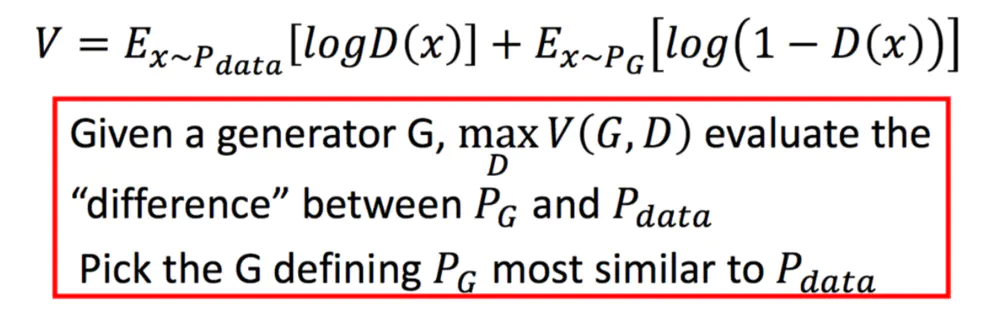
为什么V要写成这样能表示二者的差异呢?先做一个通俗的解释:
- 整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
- D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
- G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
- D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)
下面这幅图片很好地描述了这个过程:
当然这也可以通过严格的数学证明推导出,这里,对于一个给定的G,我们来求解maxV(G,D):

对于任何一个常数,因为Pdata和G这里都是给定的,我们可以认为这里是常数,那么D取什么可以得到最大呢,很简单,导数为0的情况下。
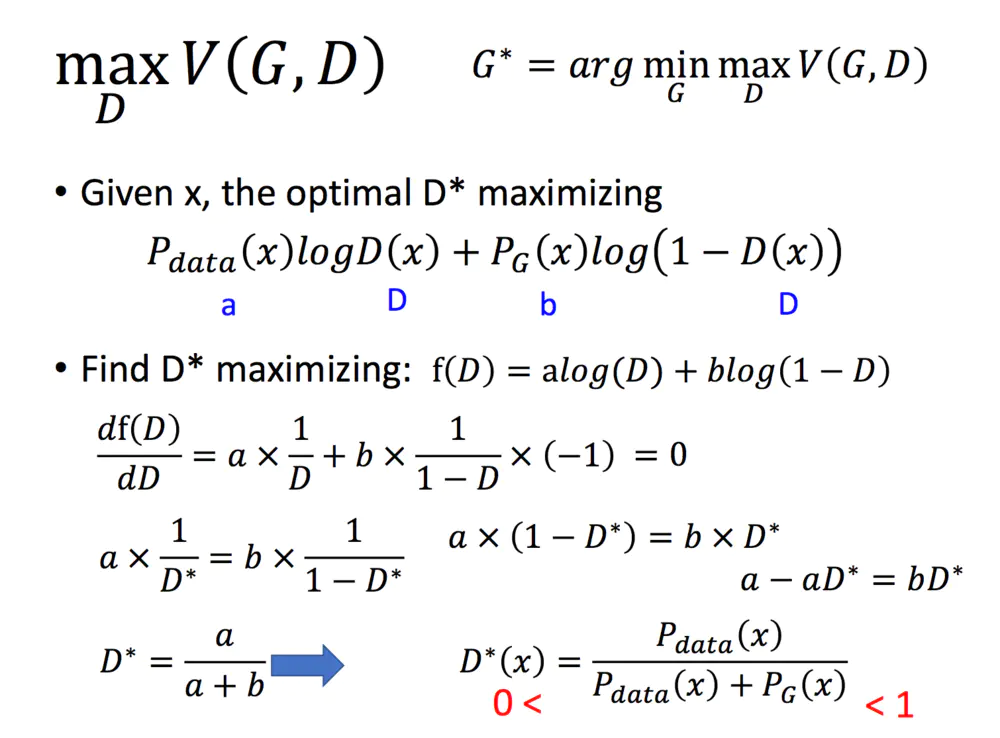
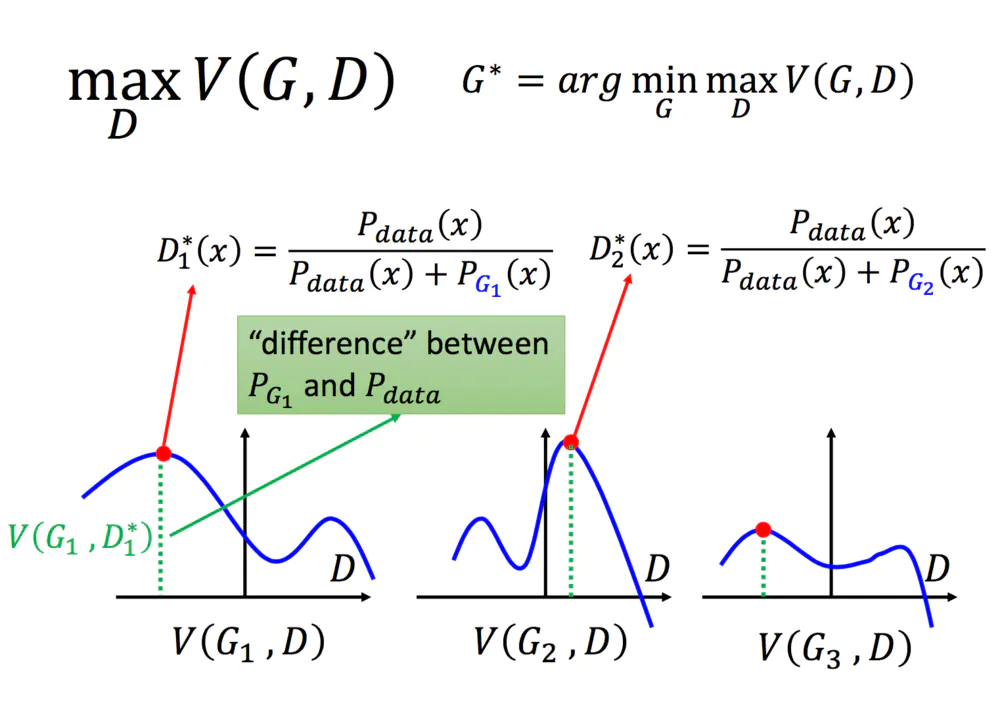
在有了D的值之后,我们就可以带入原式中啦:

继续化简,我们可以得到两个KL散度,进而得到JS散度:
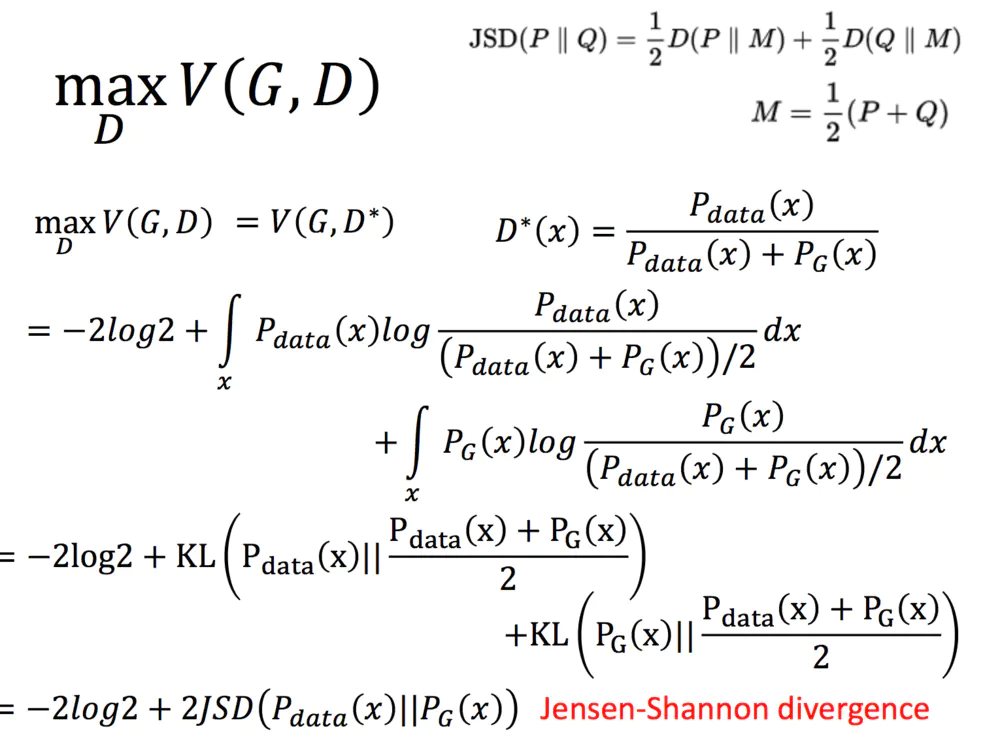
给定了一个G,我们能够通过最大化V得到D,那么我们如何求解G呢,用梯度下降就好啦:
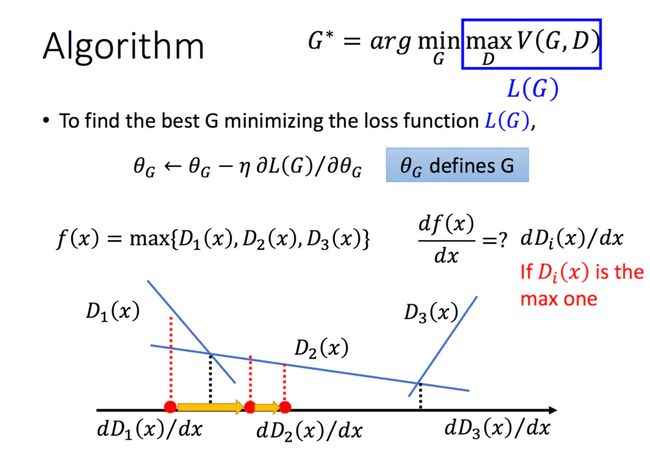
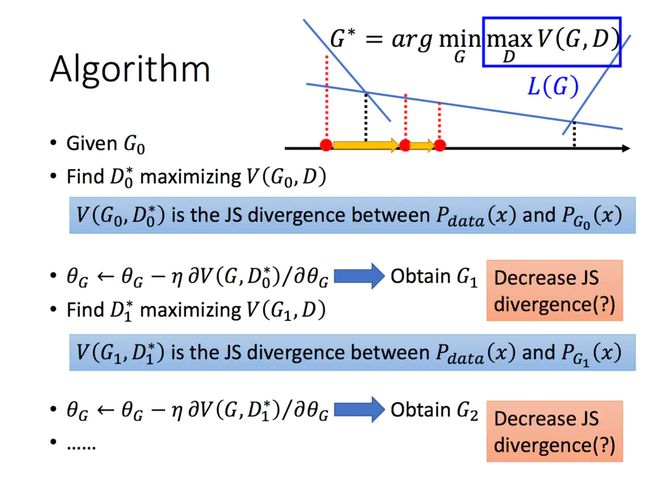
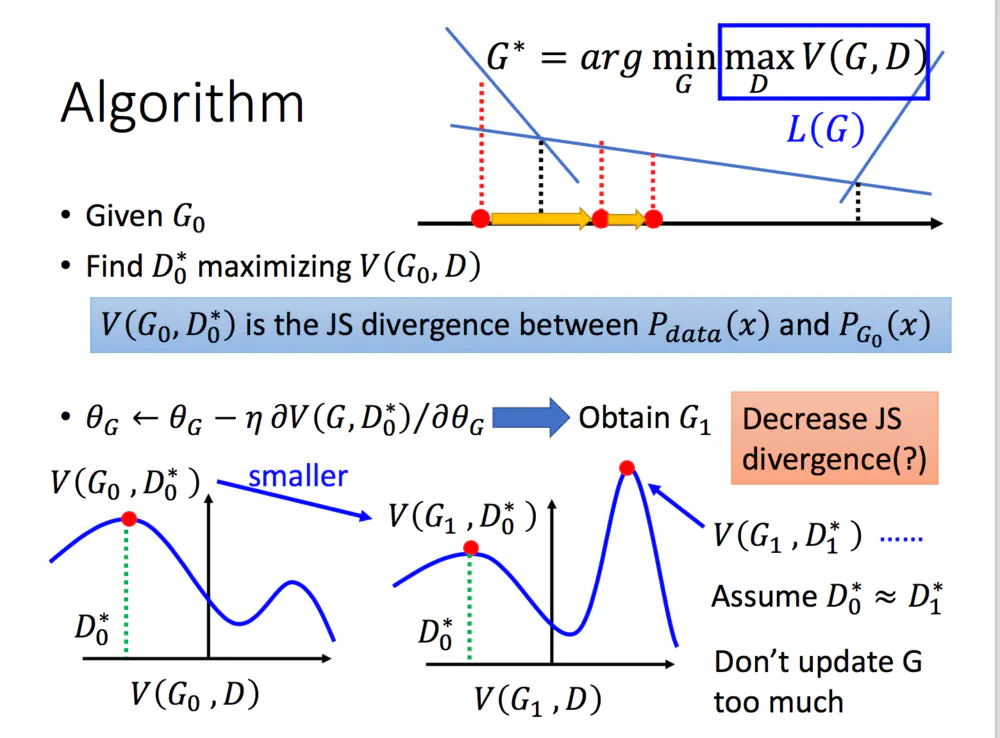
那么如何用随机梯度下降法训练D和G?论文中也给出了算法:
 这里红框圈出的部分是我们要额外注意的。第一步我们训练D,D是希望V(G, D)越大越好,所以是加上梯度(ascending)。第二步训练G时,V(G, D)越小越好,所以是减去梯度(descending)。整个训练过程交替进行。
这里红框圈出的部分是我们要额外注意的。第一步我们训练D,D是希望V(G, D)越大越好,所以是加上梯度(ascending)。第二步训练G时,V(G, D)越小越好,所以是减去梯度(descending)。整个训练过程交替进行。
3.代码实现
下面是pytorch框架实现的GAN-conv,在mnist数据集上的测试结果:
import torch
from torch import nn
from torch.autograd import Variable
import torchvision.transforms as tfs
from torch.utils.data import DataLoader, sampler
from torchvision.datasets import MNIST
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
#figsize(12.5, 4) # 设置 figsize
#plt.rcParams['savefig.dpi'] = 300 #图片像素
#plt.rcParams['figure.dpi'] = 300 #分辨率
# 默认的像素:[6.0,4.0],分辨率为100,图片尺寸为 600&400
# 指定dpi=200,图片尺寸为 1200*800
# 指定dpi=300,图片尺寸为 1800*1200
# 设置figsize可以在不改变分辨率情况下改变比例
#Interpolation/resampling即插值,是一种图像处理方法,它可以为数码图像增加或减少象素的数目。
#某些数码相机运用插值的方法创造出象素比传感器实际能产生象素多的图像,
# 或创造数码变焦产生的图像。实际上,几乎所有的图像处理软件支持一种或以上插值方法。
# 图像放大后锯齿现象的强弱直接反映了图像处理器插值运算的成熟程度
plt.rcParams['figure.figsize'] = (10.0, 8.0) # 设置画图的尺寸
plt.rcParams['image.interpolation'] = 'nearest' # 最近邻差值: 像素为正方形
plt.rcParams['image.cmap'] = 'gray'# 使用灰度输出而不是彩色输出
def show_images(images): # 定义画图工具
images = np.reshape(images, [images.shape[0], -1])
sqrtn = int(np.ceil(np.sqrt(images.shape[0]))) #ceil返回整数
sqrtimg = int(np.ceil(np.sqrt(images.shape[1])))
fig = plt.figure(figsize=(sqrtn, sqrtn))
gs = gridspec.GridSpec(sqrtn, sqrtn)
gs.update(wspace=0.05, hspace=0.05)
for i, img in enumerate(images):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(img.reshape([sqrtimg,sqrtimg]))
return
def preprocess_img(x):
x = tfs.ToTensor()(x)
return (x - 0.5) / 0.5
def deprocess_img(x):
return (x + 1.0) / 2.0
class ChunkSample(sampler.Sampler):
def __init__(self,num_samples,start=0):
self.num_samples = num_samples
self.start = start
def __iter__(self):
return iter(range(self.start,self.start + self.num_samples))
def __len__(self):
return self.num_samples
NUM_TRAIN = 50000
NUM_VAL = 5000
NOISE_DIM = 96
batch_size = 128
train_set = MNIST('./mnist',train=True,download=True,transform=preprocess_img)
train_data = DataLoader(train_set,batch_size=batch_size,sampler=ChunkSample(NUM_TRAIN,0))
val_set = MNIST('./mnist',train=True,download=True,transform=preprocess_img)
val_data = DataLoader(val_set,batch_size=batch_size,sampler=ChunkSample(NUM_VAL,NUM_TRAIN))
imgs = deprocess_img(train_data.__iter__().next()[0].view(batch_size,784)).numpy().squeeze()
class build_dc_classifier(nn.Module):
def __init__(self):
super(build_dc_classifier, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 32, 5, 1),
nn.LeakyReLU(0.01),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 5, 1),
nn.LeakyReLU(0.01),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(1024, 1024),
nn.LeakyReLU(0.01),
nn.Linear(1024, 1)
)
def forward(self, x):
x = self.conv(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
class build_dc_generator(nn.Module):
def __init__(self, noise_dim=NOISE_DIM):
super(build_dc_generator, self).__init__()
self.fc = nn.Sequential(
nn.Linear(noise_dim, 1024),
nn.ReLU(True),
nn.BatchNorm1d(1024),
nn.Linear(1024, 7 * 7 * 128),
nn.ReLU(True),
nn.BatchNorm1d(7 * 7 * 128)
)
self.conv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, padding=1),
nn.ReLU(True),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 1, 4, 2, padding=1),
nn.Tanh()
)
def forward(self, x):
x = self.fc(x)
x = x.view(x.shape[0], 128, 7, 7) # reshape 通道是 128,大小是 7x7
x = self.conv(x)
return x
def train_dc_gan(D_net, G_net, D_optimizer, G_optimizer, discriminator_loss, generator_loss, show_every=250,
noise_size=96, num_epochs=10):
iter_count = 0
for epoch in range(num_epochs):
for x, _ in train_data:
bs = x.shape[0]
# 判别网络
real_data = Variable(x) # 真实数据
logits_real = D_net(real_data) # 判别网络得分
sample_noise = (torch.rand(bs, noise_size) - 0.5) / 0.5 # -1 ~ 1 的均匀分布
g_fake_seed = Variable(sample_noise)
fake_images = G_net(g_fake_seed) # 生成的假的数据
logits_fake = D_net(fake_images) # 判别网络得分
d_total_error = discriminator_loss(logits_real, logits_fake) # 判别器的 loss
D_optimizer.zero_grad()
d_total_error.backward()
D_optimizer.step() # 优化判别网络
# 生成网络
g_fake_seed = Variable(sample_noise)
fake_images = G_net(g_fake_seed) # 生成的假的数据
gen_logits_fake = D_net(fake_images)
g_error = generator_loss(gen_logits_fake) # 生成网络的 loss
G_optimizer.zero_grad()
g_error.backward()
G_optimizer.step() # 优化生成网络
if (iter_count % show_every == 0):
print('Iter: {}, D: {:.4}, G:{:.4}'.format(iter_count,
d_total_error.item(), g_error.item()))
imgs_numpy = deprocess_img(fake_images.data.cpu().numpy())
show_images(imgs_numpy[0:16])
plt.show()
print()
iter_count += 1
bce_loss = nn.BCEWithLogitsLoss()
def discriminator_loss(logits_real, logits_fake): # 判别器的 loss
size = logits_real.shape[0]
true_labels = Variable(torch.ones(size, 1)).float()
false_labels = Variable(torch.zeros(size, 1)).float()
loss = bce_loss(logits_real, true_labels) + bce_loss(logits_fake, false_labels)
return loss
def generator_loss(logits_fake):
size = logits_fake.shape[0]
true_labels = Variable(torch.ones(size,1)).float()
loss = bce_loss(logits_fake,true_labels)
return loss
def get_optimizer(net):
optimizer = torch.optim.Adam(net.parameters(),lr=3e-4,betas=(0.5,0.999))
return optimizer
D_DC = build_dc_classifier()
G_DC = build_dc_generator()
D_DC_optim = get_optimizer(D_DC)
G_DC_optim = get_optimizer(G_DC)
train_dc_gan(D_DC, G_DC, D_DC_optim, G_DC_optim, discriminator_loss, generator_loss, num_epochs=5)
最终实现效果:
