深度学习鱼书笔记
What I cannot create, I do not understand.—— Richard Phillips Feynman
本书不使用任何现有的深度学习框架,尽可能仅使用最基本的数学知识和Python 库,从零讲解深度学习核心问题的数学原理,从零创建一个经典的深度学习网络。
文章目录
- 1-python基础
- 2-朴素感知机(人工神经元)
- 2-1 感知机是什么
- 2-2 简单的逻辑电路
- 2-3 感知机的实现
- 2-4 感知机的局限性
- 2-5 多层感知机
- 3-神经网络
- 3-1 激活函数
- 3-2 阶跃函数和sigmoid函数以及Relu函数
- 3-2-1 sigmoid函数
- 3-2-2 阶跃函数
- 3-2-3 sigmoid函数和阶跃函数的比较
- 3-2-4 非线性函数
- 3-2-5 Relu函数
- 3-3 多维数组的使用
- 3-3-1 多维数组
- 3-3-2 矩阵乘法
- 3-3-3 神经网络的内积
- 3-4 3层神经网络的实现
- 3-4-1 符号的规定
- 3-4-2 各层间信号的传递
- 3-4-3 3层神经网络代码小结
- 3-5 输出层的设计
1-python基础
python基础
numpy库的使用
matplotlib库的使用
2-朴素感知机(人工神经元)
感知机是深度学习的起源算法,学习感知机的构造就是学习深度学习的一种重要思想。这一章讲述的是单层的感知机。
2-1 感知机是什么
感知机接收多个输入信号,输出一个信号。
输入
权重
输出
阈值
输入信号被送往神经元时,会被分别乘以固定的权重(w1x1、w2x2)。神经元会计算传送过来的信号的总和当输出超过阈值时,才会输出信号。这也称为“神经元被激活”。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1xkdMcXq-1582985168073)(en-resource://database/1101:1)]
感知机的多个输入信号都有各自固有的权重,这些权重发挥着控制各个信号的重要性的作用。也就是说,权重越大,对应该权重的信号的重要性就越高。
2-2 简单的逻辑电路
与门、与非门、或门的感知机构造是一样的。实际上,3 个门电路只有参数的值(权重和阈值)不同。也就是说,相同构造的感知机,只需通过适当地调整参数的值,就可以像“变色龙演员”表演不同的角色一样,变身为与门、与非门、或门。
2-3 感知机的实现
简单的代码实现
导入权重和偏置
**权重:**不同信号对神经元的影响程度,用于控制各个信号的重要程度。
**偏置:**偏置是调整神经元被激活的容易程度(输出信号为1 的程度)的参数。
偏置的值决定了神经元被激活的容易程度。
使用权重和偏置的实现
2-4 感知机的局限性
感知机可以实现与门、与非门、或门三种逻辑电路。当时感知机不能实现异或门(XOR gete)
异或门又被称作逻辑异或电路
线性和非线性:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SnZtlwxB-1582985168075)(en-resource://database/1103:1)]
2-5 多层感知机
单层感知机不能实现异或门,但是我们可以多层感知机来实现异或门。因此下一章我们将学到神经网络。
3-神经网络
前面提到的感知机是朴素感知机,神经网络是多层感知机。
朴素感知机: 单层网络,指的是激活函数使用了阶跃函数的模型。(阶跃函数是指一旦输入超过阈值,就切换输出的函数。)
多层感知机: 是指神经网络,即使用sigmoid函数(后述)等平滑的激活函数的多层网络。
实际上,上一章介绍的感知机和接下来要介绍的神经网络的主要区别就在于这个激活函数。其他方面,比如神经元的多层连接的构造、信号的传递方法等,基本上和感知机是一样的。
3-1 激活函数
激活函数: 将输入信号的总和转换为输出信号。先计算输入信号的加权总和,然后用激活函数转换这一总和。激活函数是连接感知机和神经网络的桥梁。
a = b + w1x1 + w2x2
y = h(a)
其中 函数h就是激活函数
计算加权输入信号和偏置的总和,记为a。然后用h()函数将a转换为输出y。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ifGtuU3B-1582985168077)(en-resource://database/1105:1)]
表示神经元的○中明确显示了激活函数的计算过程,即信号的加权总和为节点a,然后节点a被激活函数h() 转换成节点y。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jKMDkHZI-1582985168081)(en-resource://database/1107:1)]
3-2 阶跃函数和sigmoid函数以及Relu函数
阶跃函数: 表示的激活函数以阈值为界,一旦输入超过阈值,就切换输出。
在激活函数的众多候选函数中,感知机使用了阶跃函数。如果感知机使用其他函数作为激活函数的话会怎么样呢?实际上,如果将激活函数从阶跃函数换成其他函数,就可以进入神经网络的世界了。下面我们就来介绍一下神经网络使用的激活函数。
3-2-1 sigmoid函数
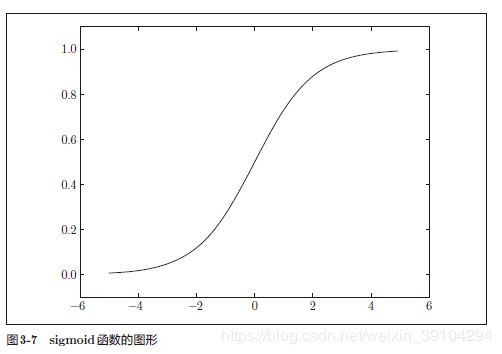
h(x)=1/(1+e^{-x})
e是纳皮尔常数2.7182 . . .
sigmoid函数的实现:
def sigmoid(x):
return 1 / (1 + np.exp(-x))
3-2-2 阶跃函数

阶跃函数的实现
def step_funcction(x):
if x>0:
return 1
else:
return 0
#该阶跃函数存在缺陷
上面这阶跃函数的缺陷在于只能接受浮点数作为参数,而不支持Numpy的矩阵作为参数输入。因此我们要更改一下阶跃函数,利用Numpy中的 astype方法转换数组的数据类型。
def step_function(x):
y = x > 0
return y.astype(np.int)
我们利用下面这段代码来详细理解我们新设定的阶跃函数
x = np.array([-1.0, 1.0, 2.0])
y = x > 0
#array([False, True, True], dtype=bool)
y = y.astype(np.int)
#array([0, 1, 1])
#由此看到从矩阵变成了布尔类型再到整形的转换
阶跃函数的图像
3-2-3 sigmoid函数和阶跃函数的比较

不同点1:“平滑性”的不同。sigmoid 函数是一条平滑的曲线,输出随着输入发生连续性的变化。而阶跃函数以0 为界,输出发生急剧性的变化。sigmoid 函数的平滑性对神经网络的学习具有重要意义。
不同点2:相对于阶跃函数只能返回0 或1,sigmoid 函数可以返回0.731 . . .、0.880 . . . 等实数(这一点和刚才的平滑性有关)。也就是说,感知机中神经元之间流动的是0 或1 的二元信号,而神经网络中流动的是连续
的实数值信号。
阶跃函数和sigmoid 函数的共同性质
阶跃函数和sigmoid函数虽然在平滑性上有差异,但是如果从宏观视角看它们具有相似的形状。
实际上,两者的结构均是“输入值较小时,输出接近0(为0);随着输入增大,输出向1 靠近(变成1)”。
也就是说,当输入信号为重要信息时,阶跃函数和sigmoid函数都会输出较大的值;当输入信号为不重要的信息时,两者都输出较小的值。还有一个共同点是,不管输入信号有多小,或者有多大,输出信号的值都在0 到1 之间。
3-2-4 非线性函数
阶跃函数和sigmoid 函数还有其他共同点,就是两者均为非线性函数。sigmoid 函数是一条曲线,阶跃函数是一条像阶梯一样的折线,两者都属于非线性的函数。
在介绍激活函数时,经常会看到“非线性函数”和“线性函数”等术语。函数本来是输入某个值后会返回一个值的转换器。向这个转换器输入某个值后,输出值是输入值的常数倍的函数称为线性函数(用数学式表示为h(x) = cx。c 为常数)。因此,线性函数是一条笔直的直线。而非线性函数,顾名思义,指的是不像线性函数那样呈现出一条直线的函数。
神经网络的激活函数必须使用非线性函数。换句话说,激活函数不能使用线性函数。为什么不能使用线性函数呢?因为使用线性函数的话,加深神经网络的层数就没有意义了。
Why?为什么神经网络的激活函数不能是线性函数?
线性函数的问题在于,不管如何加深层数,总是存在与之等效的“无隐藏层的神经网络”。为了具体地(稍微直观地)理解这一点,我们来思考下面这个简单的例子。这里我们考虑把线性函数h(x) = cx 作为激活函数,把y(x) = h(h(h(x))) 的运算对应3 层神经网络A。这个运算会进行y(x) = c × c × c × x 的乘法运算,但是同样的处理可以由y(x) = ax(注意,a = c 3)这一次乘法运算(即没有隐藏层的神经网络)来表示。如本例所示,使用线性函数时,无法发挥多层网络带来的优势。因此,为了发挥叠加层所带来的优势,激活函数必须使用非线性函数。
3-2-5 Relu函数
在阶跃函数和sigmoid 函数的基础上,我们引入一个新的激活函数Relu函数。
ReLU函数在输入大于0 时,直接输出该值;在输入小于等于0 时,输出0。

Relu函数的实现:
def relu(x):
return np.maximum(0, x)
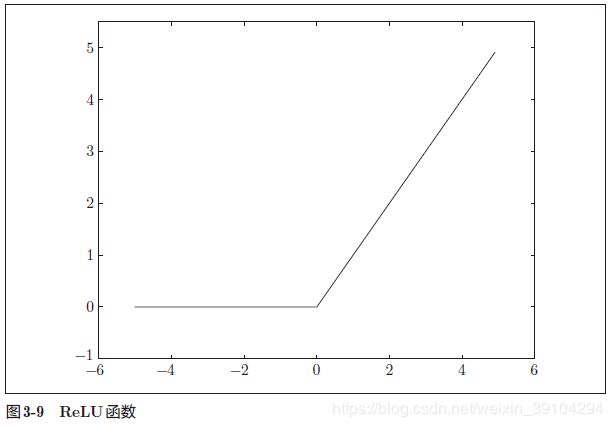
这里使用了NumPy的maximum函数。maximum函数会从输入的数值中选择较大的那个值进行输出。
3-3 多维数组的使用
3-3-1 多维数组
数组的维数可以由np.dim()计算得到;数组的形状可以通过实例变量shape获得。
Eg:
>>> import numpy as np
>>> A = np.array([1, 2, 3, 4])
>>> print(A)
[1 2 3 4]
>>> np.ndim(A)
1
>>> A.shape
(4,)
>>> A.shape[0]
4
这里的A.shape的结果是个元组(tuple),因此结果是(4, )。如果A是二维数组时返回的是元组(4,3),三维数组时返回的是元组(4,3,2)。
3-3-2 矩阵乘法
用点乘运算,np.dot() 直接上代码
>>> A = np.array([[1,2], [3,4]])
>>> A.shape
(2, 2)
>>> B = np.array([[5,6], [7,8]])
>>> B.shape
(2, 2)
>>> np.dot(A, B)
array([[19, 22],
[43, 50]])
Note:np.dot(A, B) 和np.dot(B, A) 的值可能不一样。学过线性代数的应该都知道。另外在进行矩阵乘法之前,一定要用shape()函数对矩阵的形状大小进行检查。
矩阵A·B=C ,运算结果的矩阵C的形状是由矩阵A的行数和矩阵B的列数构成的。
3-3-3 神经网络的内积
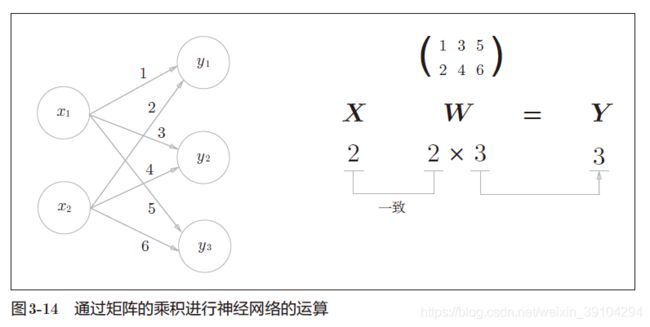
实现该神经网络时,要注意X、W、Y的形状,特别是X和W的对应维度的元素个数是否一致,这一点很重要。
输入层是两个输入神经元,因此是一个2元数组。中间的隐藏层接收了输入层的2个神经元的输入值接着传给后面输出层的3个输出神经元,因此是一个[2x3]的矩阵。
>>> X = np.array([1, 2])
>>> X.shape
(2,)
>>> W = np.array([[1, 3, 5], [2, 4, 6]])
>>> print(W)
[[1 3 5]
[2 4 6]]
>>> W.shape
(2, 3)
>>> Y = np.dot(X, W)
>>> print(Y)
[ 5 11 17]
3-4 3层神经网络的实现
**这里我们重新梳理一下,神经网络的运算可以作为矩阵运算打包进行。**因为神经网络各层的运算是通过矩阵的乘法运算打包进行的(从宏观视角来考虑)
以图3-15 的3 层神经网络为对象,实现从输入到输出的(前向)处理。
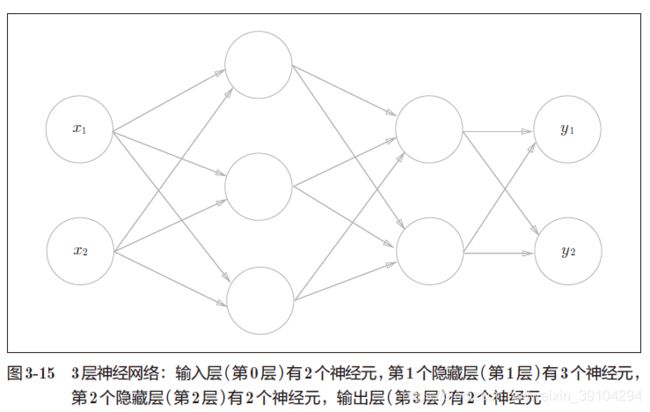
3-4-1 符号的规定
如图3-16 所示,权重和隐藏层的神经元的右上角有一个“(1)”,它表示权重和神经元的层号(即第1 层的权重、第1 层的神经元)。此外,权重的右下角有两个数字,它们是后一层的神经元和前一层的神经元的索引号。比如, ω 12 ( 1 ) \omega^{(1)}_{12} ω12(1)
表示前一层的第2 个神经元 x 2 x_{2} x2 到后一层的第1 个神经元 a 1 ( 1 ) a^{(1)}_{1} a1(1)的权重。权重右下角按照“后一层的索引号、前一层的索引号”的顺序排列。

3-4-2 各层间信号的传递
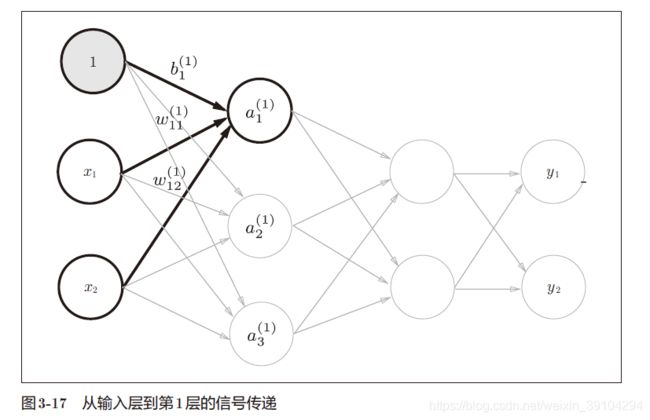
注意这里添加了灰色的神经元"1"来表示偏置。请注意,偏置的右下角的索引号只有一个。这是因为前一层的偏置神经元(神经元“1”)只有一个。而且右下角的索引1指的是隐藏层的第一个神经元。
于是我们可以得到神经元 a 1 ( 1 ) a^{(1)}_{1} a1(1)的值的表达式为 a 1 ( 1 ) = ω 11 ( 1 ) + ω 12 ( 1 ) ∗ x 2 + b 1 ( 1 ) a^{(1)}_{1}=\omega^{(1)}_{11}+\omega^{(1)}_{12}*x_{2}+b^{(1)}_{1} a1(1)=ω11(1)+ω12(1)∗x2+b1(1)
如果使用矩阵乘法,我们就能得到第1层的加权。
A 1 = X W 1 + B 1 A^{1}=XW^{1}+B^{1} A1=XW1+B1
A 1 A^{1} A1= ( a 1 ( 1 ) a 2 ( 1 ) a 3 ( 1 ) ) \begin{pmatrix}a^{(1)}_{1}&a^{(1)}_{2}&a^{(1)}_{3}\end{pmatrix} (a1(1)a2(1)a3(1))
X X X= ( x 1 x 2 ) \begin{pmatrix}x_{1}&x_{2} \end{pmatrix} (x1x2)
B ( 1 ) B^{(1)} B(1)= ( b 1 ( 1 ) b 2 ( 1 ) b 3 ( 1 ) ) \begin{pmatrix}b^{(1)}_{1}&b^{(1)}_{2}&b^{(1)}_{3} \end{pmatrix} (b1(1)b2(1)b3(1))
W ( 1 ) W^{(1)} W(1)=$$\begin{pmatrix}\omega{(1)}_{11}&\omega{(1)}{21}&\omega{(1)}_{31}\\omega{(1)}{12}&\omega{(1)}_{22}&\omega{(1)}_{32}\end{pmatrix}\$$
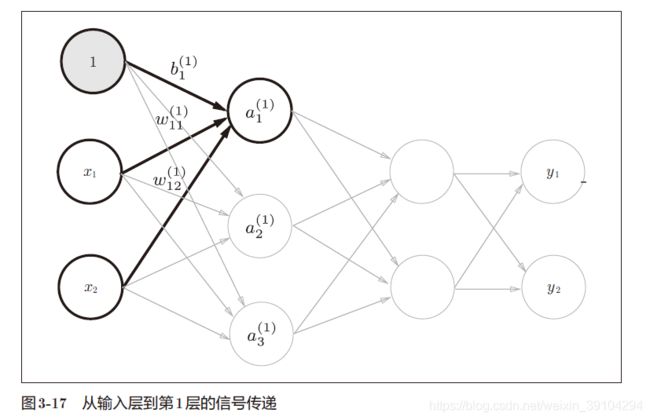
下面我们来用python的numpy来实现一下从输入层到第1层神经元的数据处理过程:
X = np.array([1.0, 0.5])#随机设定两个输入 1.0 和 0.5
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]) #设定每条路径上的参数
B1 = np.array([0.1, 0.2, 0.3]) #偏置对3个神经元产生的不同影响也用矩阵表示出来
print(W1.shape) # (2, 3)
print(X.shape) # (2,)
print(B1.shape) # (3,)
A1 = np.dot(X, W1) + B1 #至此,我们得到了第一层的结果 接着我们要导入进激活函数中
隐藏层的加权和(加权信号和偏置的总和)用a表示,被激活函数转换后的信号用z 表示。此外,图中h() 表示激活函数,这里我们使用的是sigmoid 函数。用python代码表示如下
Z1 = sigmoid(A1)
print(A1) # [0.3, 0.7, 1.1]
print(Z1) # [0.57444252, 0.66818777, 0.75026011]
至此,从输入层神经元到第1层神经元之间的数据计算就已经完成了。回顾一下可以看出是矩阵运算在加上激活函数的运算。
下面让我们来看看从第1层神经元到第2层神经元之间的传递过程的实现。
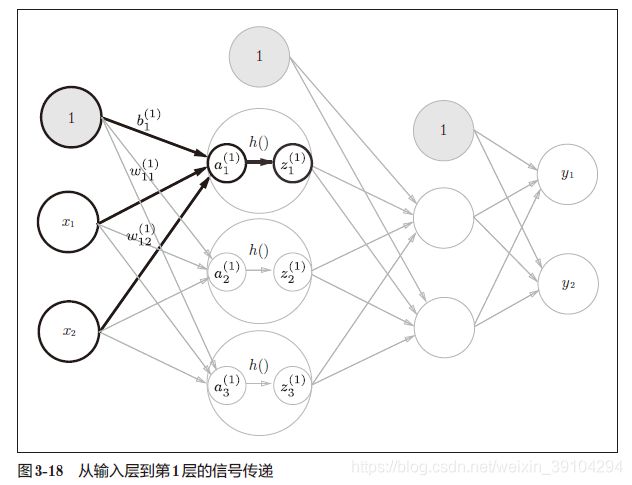
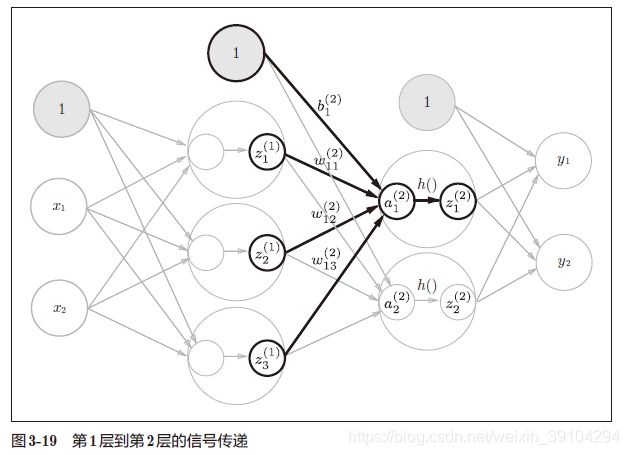
# 第1层到第2层
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
B2 = np.array([0.1, 0.2])
print(Z1.shape) # (3,)
print(W2.shape) # (3, 2)
print(B2.shape) # (2,)
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)
最后是第2 层到输出层的信号传递,输出层的实现也和之前的实现基本相同。不过,最后的激活函数和之前的隐藏层有所不同。
def identity_function(x):
return x
W3 = np.array([[0.1, 0.3], [0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = identity_function(A3) # 或者Y = A3
这里我们定义了identity_function()函数(也称为“恒等函数”),并将其作为输出层的激活函数。恒等函数会将输入按原样输出,因此,这个例子中没有必要特意定义identity_function()。这里这样实现只是为了和之前的流程保持统一。另外,图3-20 中,输出层的激活函数用σ() 表示,不同于隐藏层的激活函数h()(σ读作sigma)。
输出层所用的激活函数,要根据求解问题的性质决定。一般地,回归问题可以使用恒等函数,二元分类问题可以使用sigmoid 函数,多元分类问题可以使用softmax 函数。
3-4-3 3层神经网络代码小结
至此,我们已经介绍完了3 层神经网络的实现。现在我们把之前的代码实现全部整理一下。这里,我们按照神经网络的实现惯例,只把权重记为大写字母W1,其他的(偏置或中间结果等)都用小写字母表示。
def init_network():
#init_network()函数会进行权重和偏置的初始化,并将它们保存在字典变量network中。这个字典变量network中保存了每一层所需的参数(权重和偏置)。
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
#forward()函数中则封装了将输入信号转换为输出信号的处理过程。
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [ 0.31682708 0.69627909]
另外,这里出现了forward(前向)一词,它表示的是从输入到输出方向的传递处理。后面在进行神经网络的训练时,我们将介绍后向(backward,从输出到输入方向)的处理。分别指的是前向传播和方向传播。
3-5 输出层的设计
神经网络可以用在分类问题和回归问题上,不过需要根据情况改变输出层的激活函数。一般而言,回归问题用恒等函数,分类问题用softmax 函数。
机器学习的问题大致可以分为分类问题和回归问题。分类问题是数据属于哪一个类别的问题。比如,区分图像中的人是男性还是女性的问题就是分类问题。而回归问题是根据某个输入预测一个(连续的)数值的问题。比如,根据一个人的图像预测这个人的体重的问题就是回归问题(类似“57.4kg”这样的预测)。