项目报告: 《数字图像处理》自动定位、分割、识别汽车车牌 (非深度学习方法,使用传统数字图像处理方法)-2019
自动定位、分割、识别汽车车牌
1 实验内容与目的
本次《数字图像处理》课程作业要求使用数字图像处理技术自动定位,分割和识别车牌。其中数据需要使用老师提供的数据(50张车牌图片),尽量使用课程中老师讲授的传统的数字图像处理领域的知识,不使用深度学习(除非仅仅使用老师提供的数据集)。
2 方法概述
整个算法的流程见下表:
| 序号 | 步骤 |
|---|---|
| 1 | 图像的预处理 |
| 2 | 车牌粗定位 |
| 3 | 车牌精定位 |
| 4 | 车牌区域切割 |
| 5 | 字符切割 |
| 6 | 字符识别 |
2.1 图像的预处理
由于老师所给的数据集中每一种车牌的背景颜色不同,有白色的车牌、黄色的车牌以及最常见的蓝色的车牌,所以这里对于不同背景颜色的车牌进行分开讨论。我们在这里使用背景为蓝色的车牌举例说明图像预处理的部分。
首先考虑到待识别的图片的背景比较复杂,并且有较多的噪声,所以这里将RGB像素值比较低的彩(蓝)色噪声去掉,防止噪声对于后续操作的干扰。
然后接着将蓝色的区域进行提取,并在灰度图中尽量显示出来,这里提取的方法主要使用的是蓝色的RBG值为(0,0,255)。然后再对于蓝色提取后的区域进行归一化,并使用二值化的函数进行二值化的操作,从而的到原图像对应的灰度(二值化)图像。
接着对于以上的二值化的图像(二维的二值化图像)进行连通区域的标记,这里是为了找到“蓝色”区域中面积最大的区域,并将其初步认为其是车牌所在的区域,并使用函数对于连通区域的属性进行度量,来判断具体哪一个区域为蓝色所标记的区域。再对于这些区域的面积进行排序,将面积比较大的区域进行初步的标记。
选择得到初步的车牌位置后需要对于图像进行闭运算,使用因为使用闭运算可以使得轮廓线更为光滑,而且可以消弥狭窄的间断和长细的鸿沟,消除小的空洞,并填补轮廓线中的断裂,这样就可以将车牌中的字体(通常在一个图片中面积比较小)也纳入到上面所标记的所谓的车牌的区域中。
进行完成图像聚类(图像的闭运算,填充图像后),我们再一次对于连通的区域进行标记,与上一次操作不同的是,这里我们仅仅选择面积最大的区域作为我们所认定的暂时的车牌区域,并将此二值化的图片(矩阵)送入下一个“车牌的粗定位”步骤中进行进一步的操作。
其实这一步的图像预处理等价于使用了形态学滤波的方法进行了图像的预处理工作。
2.2 车牌粗定位
这里的粗定位的方法其实可以与上一步联系在一起,因为其实在图像的预处理中已经找到了车牌的位置,这里的车牌粗定位的工作是确定行的起始位置和终止位置,以及列的起始位置和终止位置,并将其原来的彩色图像恢复,用于下一步真正的细定位的工作。
具体的做法是,首先为了不改变图像的分辨率,将其变更为double类型的图片。
接着,首先确定行的起始位置和终止位置,这里将图像预处理工作得到的结果在横向上进行了加和,由于是二值化的图像,所以只有0和1两个数值,所以可以很明显的在通过统计的曲线看出黑白区域的边界部分,从而可以比较好的确定具体的行的起始位置和终止位置。
然后确定列的起始位置和终止位置,这里将图像预处理工作得到的结果在纵向上进行了加和,由于是二值化的图像,所以只有0和1两个数值,所以可以很明显的在通过统计的曲线看出黑白区域的边界部分,从而可以比较好的确定具体的列的起始位置和终止位置。
最终,通过行列的统计结果,即标记的行列的终止和起始的位置,从原彩色图片中切割出粗定位后的图片,并予以显示。
2.3 车牌精定位
接下来是图片精定位的工作,由于上一步骤中图像的粗定位中仍然存在一下的问题:首先是角度不一定是水平的,这是因为数据本身的拍摄角度不同,有很多的照片使用前面的粗定位和图像预处理后,整个的车牌的角度并不是水平,这就会对于以后的字符切割工作造成麻烦,所以进行角度的旋转是很必要的;另外一方面,我们还需要对于水平的图像进行裁剪。期间每进行完一次的操作后,都是用直方图对于操作后的结果进行分析。
首先进行角度变换之前,要进行如下的操作,由于取得的是车牌粗处理的图片,首先进行resize将不同大小的区域都resize为同样大小的区域;接着进行二值化和形态学的开操作,一个开操作是一个腐蚀操作再接着一个膨胀操作使用相同的结构元素。这样可以求得图片的主要的特征,并且将噪声进一步的去除。然后再找出图像的主要目标以及其对应的最大的连通区域。
接下来我们可以根据以上操作的结果来进行角度的变化,这里的角度变换的前提是车牌粗定位的时候,边界的区域比较精确而且完全近似于矩形,这里我们直接使用MATLAB自带的函数计算矩形的长边长与水平方向的夹角,从而得到需要的旋转角度,再使用MATLAB自带的图像旋转工具进行图像的旋转。
由于经过旋转后的图像的分辨率会下降很多,所以这里我继续对于旋转后的图片进行了基于形态学的开运算。
最后将最终的图像进行切割,得到最终的车牌精定位的结果,并把结果转换为二值化的图像,方便以后的字符识别。在过程中,我每操作一步都会使用直方图检验分割的效果。
2.4 车牌区域切割
上步骤中的车牌精定位的效果达到了预期的目标,但是在图像的周围还是存在“黑边”这对于后续的字符的识别会产生严重的干扰,所以我们还是需要“真正”体现车牌信息的区域进行切割。
这里考虑的方法就是,在横向最左和最右端分别以一个像素的步长向中心移动,直到遇到“白色”的像素值,这里为了防止“白色”噪声的干扰,通过设置阈值或者说是形态学直方图的阈值对于条件进行判断,从而增加模型的鲁棒性能。在纵向也相同,最上端和最下端分别以一个像素的步长向中心移动,直到遇到“白色”的像素值,这里为了防止“白色”噪声的干扰,通过设置阈值或者说是形态学直方图的阈值对于条件进行判断,从而增加模型的鲁棒性能。
经过“车牌区域切割”的操作后,我们得到的就是完整并且不带任何“边界”的纯车牌信息了。
2.5 字符切割
经过上面的四步骤,我们得到了完整并且不带任何“边界”的纯车牌图片,所以接下来进行字符的切割操作。
这里的字符切割完全考虑到的是单行的车牌的识别,对于数据集中出现的两行的车牌暂时没有考虑这种情况。
算法中首先需要计算得到区域中有多少个文字出现,这里考虑的是使用计算连通区域的方法,与图像预处理的想法基本一致,计算有多少个面积大于一定阈值的连通区域就确定为多少个文字(英文字母)出现,另外一点,一般的车牌的文字+字母+数字的个数不会超过8个,所以这里我将连通区域的数目规定为小于8个。
然后我们使用MATLAB自带的函数对于连通区域进行判断与定位,并将其初步使用bbox进行定位。接着对于所有的bbox分别计算他们在水平和竖直方向上的长度,并将这个平均长度视为每一个文字区域的长度,在竖直方向也一样,将平均的宽度视为每一个文字区域的宽度。但是对于水平方向还需要如下的进一步细分,还是判断在每一个文字区域内的连通区域,一般来说如果分类正确应该在每一个文字区域中只有一个连通区域(这里的中文由于进行了开运算,也是可以看作为一个连通区域,即使文字出现了偏旁部首)。如果发现了多个(一般为两个或者三个)连通区域,那么就将切割范围在水平方向上进行细微的调动,直到完成每一个文字中有且只有一个连通区域的目标。
这样我们就可以定位到每一个文字区域的边界点(定位点),从而进行切割操作。这里为了方便,我们将切割的目标区域的数量定位7个。因为一般的车牌号码是:省的简称+一个字母(两个字母)+五个数字(四个数字)组成的。这样我们将最终切割得到了7个文字区域交给下一个字符识别来进行。
2.6 字符识别
由于不能使用现成的OCR以及深度神经网络进行这里的字符识别,严格来说是字符的匹配。其中匹配的模板是自己切割的数字0-9是个数字以及a-z这26个字母,其中这里的字母I和O因为在车牌中和数字1和0基本完全相同,所以这里没有识别字母I和字母O的,这里一切都是直接使用数字1和数字0来代替。
我们这里将识别汉字和识别数字、字母分开来看,首先来看数字和字母的识别。
我们如果默认车牌是由7个字符组成的,即省的简称+一个字母(两个字母)+五个数字(四个数字)组成的话,那么后六个应该就是数字以及字母的位置。这里考虑首先对于切割出来的每一个字符区域与数字+字母的模板(切割的数字0-9是个数字以及a-z这26个字母),进行点乘,其目的在于进一步匹配两者的近似程度,还有一个细节是,我自己制作的模板与前一步分割出来的字符正好的相反的,即模板的“黑色”区域是切割出来字符的“白色”区域,所以在进行点乘之前需要先将区域进行二值化的反转操作,使用阈值为0.5的反转函数就可以轻易的实现。进行点乘完后,我们对于点乘后的图片(矩阵),再进行连通区域的标定,并且计算出其最大的面积,使用这个最大的面积与模板在进行MSE的计算,对于一个字符区域与每一个模板进行上述的操作,从中找到一个MSE最小的标定块,并认为其就是与字符相同的模板。这也就达到了识别的效果。不过这一切识别正确的前提是,之前的图像预处理、车牌的细分割以及最后的字符的分割做的准确无误。
接下来是汉字的识别。我们如果默认车牌是由7个字符组成的,即省的简称+一个字母(两个字母)+五个数字(四个数字)组成的话,那么第一个区域应该就是数字以及字母的位置。其中一个细节是,我自己制作的模板与前一步分割出来的字符正好的相反的,即模板的“黑色”区域是切割出来字符的“白色”区域,所以在进行操作之前需要先将区域进行二值化的反转操作,使用阈值为0.5的反转函数就可以轻易的实现。在这里我首先对于字符进行较为微弱的腐蚀运算接着使用这个字符区域与每一个中文字符模板进行MSE的计算操作,最终MSE最小的模板就直接认为其是正确的模板,并认为其就是与字符相同的模板。这也就达到了识别的效果。不过这一切识别正确的前提是,之前的图像预处理、车牌的细分割以及最后的字符的分割做的准确无误。
所以模型最后的字符识别成功,关键在于前面定位以及分割算法的精细程度以及准确率。
3 源代码的解释与说明
3.1 图像预处理源代码说明
图像预处理算法的源代码在rgb2filtered.m文件中。
首先考虑到待识别的图片的背景比较复杂,并且有较多的噪声,所以这里将RGB像素值比较低的彩(蓝)色噪声去掉,防止噪声对于后续操作的干扰。然后接着将蓝色的区域进行提取,并在灰度图中尽量显示出来,这里提取的方法主要使用的是蓝色的RBG值为(0,0,255)。主要的实现代码如下:

然后再对于蓝色提取后的区域进行归一化,并使用二值化的函数进行二值化的操作,从而的到原图像对应的灰度(二值化)图像。
![]()
接着对于以上的二值化的图像(二维的二值化图像)进行连通区域的标记,这里是为了找到“蓝色”区域中面积最大的区域,并将其初步认为其是车牌所在的区域,并使用函数对于连通区域的属性进行度量,来判断具体哪一个区域为蓝色所标记的区域。再对于这些区域的面积进行排序,将面积比较大的区域进行初步的标记。

选择得到初步的车牌位置后需要对于图像进行闭运算,使用因为使用闭运算可以使得轮廓线更为光滑,而且可以消弥狭窄的间断和长细的鸿沟,消除小的空洞,并填补轮廓线中的断裂,这样就可以将车牌中的字体(通常在一个图片中面积比较小)也纳入到上面所标记的所谓的车牌的区域中。
![]()
进行完成图像聚类(图像的闭运算,填充图像后),我们再一次对于连通的区域进行标记,与上一次操作不同的是,这里我们仅仅选择面积最大的区域作为我们所认定的暂时的车牌区域,并将此二值化的图片(矩阵)送入下一个“车牌的粗定位”步骤中进行进一步的操作。

同样的方法如果是黄色背景或者其他颜色的背景,可以直接将提取的颜色设置为需要的RGB颜色即可,另一方面,为了鲁棒性的优势,这里可以将RGB的提取范围扩大,从而将更多的区域归入其中,从而提高识别的效率和准确性等程度。
3.2 车牌粗定位源代码说明
车牌粗定位的源代码在rough_locate.m文件中。
这里的粗定位的方法其实可以与上一步联系在一起,因为其实在图像的预处理中已经找到了车牌的位置,这里的车牌粗定位的工作是确定行的起始位置和终止位置,以及列的起始位置和终止位置,并将其原来的彩色图像恢复,用于下一步真正的细定位的工作。
首先是确定行的起始位置和终止位置,这里将图像预处理工作得到的结果在横向上进行了加和,由于是二值化的图像,所以只有0和1两个数值,所以可以很明显的在通过统计的曲线看出黑白区域的边界部分,从而可以比较好的确定具体的行的起始位置和终止位置。

然后确定列的起始位置和终止位置,这里将图像预处理工作得到的结果在纵向上进行了加和,由于是二值化的图像,所以只有0和1两个数值,所以可以很明显的在通过统计的曲线看出黑白区域的边界部分,从而可以比较好的确定具体的列的起始位置和终止位置。

最终,通过行列的统计结果,即标记的行列的终止和起始的位置,从原彩色图片中切割出粗定位后的图片,并予以显示。
![]()
3.3 车牌精定位源代码说明
车牌精定位的源代码在precise_locate.m文件中。
首先是二值化和形态学的开操作,一个开操作是一个腐蚀操作再接着一个膨胀操作使用相同的结构元素。这样可以求得图片的主要的特征,并且将噪声进一步的去除。然后再找出图像的主要目标以及其对应的最大的连通区域。

接下来我们可以根据以上操作的结果来进行角度的变化,这里的角度变换的前提是车牌粗定位的时候,边界的区域比较精确而且完全近似于矩形,这里我们直接使用MATLAB自带的函数计算矩形的长边长与水平方向的夹角,从而得到需要的旋转角度,再使用MATLAB自带的图像旋转工具进行图像的旋转。

最后将最终的图像进行切割,得到最终的车牌精定位的结果,并把结果转换为二值化的图像,方便以后的字符识别。

在过程中,我每操作一步都会使用直方图检验分割的效果,基本的代码为:

3.4 车牌区域切割源代码说明
车牌区域切割源代码在final_crop.m文件中。
对于去除黑边,这里考虑的方法就是,在横向最左和最右端分别以一个像素的步长向中心移动,直到遇到“白色”的像素值,这里为了防止“白色”噪声的干扰,通过设置阈值或者说是形态学直方图的阈值对于条件进行判断,从而增加模型的鲁棒性能。在纵向也相同,最上端和最下端分别以一个像素的步长向中心移动,直到遇到“白色”的像素值,这里为了防止“白色”噪声的干扰,通过设置阈值或者说是形态学直方图的阈值对于条件进行判断,从而增加模型的鲁棒性能。

接着再使用切割得到车牌的矩形区域。

3.5 字符切割源代码说明
字符切割源代码在seperate_characters.m文件和get_character.m文件中。
算法中首先需要计算得到区域中有多少个文字出现,这里考虑的是使用计算连通区域的方法,与图像预处理的想法基本一致,计算有多少个面积大于一定阈值的连通区域就确定为多少个文字(英文字母)出现,另外一点,一般的车牌的文字+字母+数字的个数不会超过8个,所以这里我将连通区域的数目规定为小于8个。

然后我们使用MATLAB自带的函数对于连通区域进行判断与定位,并将其初步使用bbox进行定位。接着对于所有的bbox分别计算他们在水平和竖直方向上的长度,并将这个平均长度视为每一个文字区域的长度,在竖直方向也一样,将平均的宽度视为每一个文字区域的宽度。但是对于水平方向还需要如下的进一步细分,还是判断在每一个文字区域内的连通区域,一般来说如果分类正确应该在每一个文字区域中只有一个连通区域(这里的中文由于进行了开运算,也是可以看作为一个连通区域,即使文字出现了偏旁部首)。如果发现了多个(一般为两个或者三个)连通区域,那么就将切割范围在水平方向上进行细微的调动,直到完成每一个文字中有且只有一个连通区域的目标。


这样我们就可以定位到每一个文字区域的边界点(定位点),从而进行切割操作。

3.6 字符识别源代码说明
字符识别的源代码在characters_recognition.m文件中。
由于不能使用现成的OCR以及深度神经网络进行这里的字符识别,严格来说是字符的匹配。其中匹配的模板是自己切割的数字0-9是个数字以及a-z这26个字母,其中这里的字母I和O因为在车牌中和数字1和0基本完全相同,所以这里没有识别字母I和字母O的,这里一切都是直接使用数字1和数字0来代替。
首先是我们如果默认车牌是由7个字符组成的,即省的简称+一个字母(两个字母)+五个数字(四个数字)组成的话,那么后六个应该就是数字以及字母的位置。这里考虑首先对于切割出来的每一个字符区域与数字+字母的模板(切割的数字0-9是个数字以及a-z这26个字母),进行点乘,其目的在于进一步匹配两者的近似程度,还有一个细节是,我自己制作的模板与前一步分割出来的字符正好的相反的,即模板的“黑色”区域是切割出来字符的“白色”区域,所以在进行点乘之前需要先将区域进行二值化的反转操作,使用阈值为0.5的反转函数就可以轻易的实现。

进行点乘完后,我们对于点乘后的图片(矩阵),再进行连通区域的标定,并且计算出其最大的面积,使用这个最大的面积与模板在进行MSE的计算,对于一个字符区域与每一个模板进行上述的操作,从中找到一个MSE最小的标定块,并认为其就是与字符相同的模板。这也就达到了识别的效果。

3.7 主函数的源代码说明
这里主函数的功能就是将以上的六个步骤总结在一起,并从选取待识别图片开始进行,一步一步进行图像预处理、车牌粗定位、车牌细定位、车牌切割、字符切割以及最终的字符识别的工作。具体的实现方式如下:

4 识别结果展示
我们这里使用两个图片的结果说明:23.jpg和test0101.jpg。
首先23.jpg的图像预处理的结果(左侧为原图,右侧为处理后的图片,这个图片仅仅是对于选定颜色的提取结果以及二值化后的结果):


然后是经过连通区域以及闭运算后的结果,期间也使用了形态学滤波的方法进行了分析,过程也在下面进行显示,分别显示横向和纵向的统计结果:



接着根据以上的结果,进行车牌的粗定位,并在原图中进行截取,截取的粗定位的车牌如下图:

接下来首先对于上面的车牌粗定位的图像进行开运算并进行二值化的操作,并在水平和竖直方向分别统计,结果如下:



然后对于上面的二值化图像进行旋转,使得其水平。并在水平和竖直方向分别统计,结果如下:



接着对于车牌进行细微的再分割,目的是与最终的匹配的模板一致,将上下左右侧的黑边去除,算法运行后的切割的结果如下:

然后对于上面的图像进行字符级别的切割,结果如下(这是7个单独的图片):

接着是使用模板匹配的方法进行字符识别,其中自己制作的模板如下图:

![]()
然后分别对于每一个分割后的字符进行模板的匹配,这里分别在横向和纵向对于图像进行分析匹配,匹配结果和横向的统计结果如下图(这里以英文和数字为例说明结果):

最后将匹配的结果通过命令行输出:

下面来看另外一个图片的例子:test0101.jpg。
首先test0101.jpg的图像预处理的结果(左侧为原图,右侧为处理后的图片,这个图片仅仅是对于选定颜色的提取结果以及二值化后的结果):


然后是经过连通区域以及闭运算后的结果,期间也使用了形态学滤波的方法进行了分析,过程也在下面进行显示,分别显示横向和纵向的统计结果:

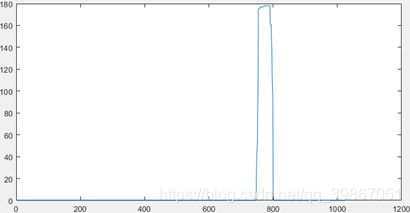

接着根据以上的结果,进行车牌的粗定位,并在原图中进行截取,截取的粗定位的车牌如下图:

接下来首先对于上面的车牌粗定位的图像进行开运算并进行二值化的操作,并在水平和竖直方向分别统计,结果如下:



然后对于上面的二值化图像进行旋转,使得其水平。并在水平和竖直方向分别统计,结果如下:



接着对于车牌进行细微的再分割,目的是与最终的匹配的模板一致,将上下左右侧的黑边去除,算法运行后的切割的结果如下:


然后对于上面的图像进行字符级别的切割,结果如下(这是7个单独的图片):

然后分别对于每一个分割后的字符进行模板的匹配,这里分别在横向和纵向对于图像进行分析匹配,匹配结果和横向的统计结果如下图(这里以英文和数字为例说明结果):

最后将匹配的结果通过命令行输出:

5 其他方法的尝试
5.1 基于卷积的特征提取和矩形度约束的方法
这个方法的效率比较低,其基于卷积运算首先对于特征进行提取,在由此进行的车牌的识别工作。这里使用的卷积核的形式如下:
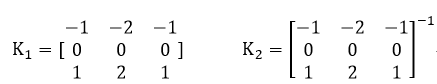
由此来检测水平方向和竖直方向的变化情况(并突出边缘的部分,使得车牌的部分更加清晰),对于(2)WJ03-警0037.jpg这个图片进行完如下的卷积操作以后的图形如下所示:


然后对于车牌进行二值化的操作,并计算出连通区域内的面积,通过设置阈值将面积小于一定数值的区域删除,留下来大的区域,同时这里还进行了连通区域的长宽比以及近似矩形度的计算,因为我们最后确定的区域应该是一个矩形域而且它的长宽比一定是确定范围内的数字,经过查阅查阅资料,一般的车牌的长宽比大约为4:1与5:1之间,所以可以根据这种条件来对于车牌的具体区域进行区分与寻找。这里的主要实现代码如下:

通过这套算法,最终得到的车牌的区域为:

对于上图进行canny算子进行边缘检测的结果为:

5.2 基于canny算子边缘检测的方法
5.2.1 图像的预处理
这里首先将输入的图片转化为灰度的图像,然后对其进行基于Canny算子的边缘检测。其结果如下图:这里使用test00000120050921201034561.jpg这幅图片举例:



这里使用Canny进行边缘检测是因为,车牌的背景与其周围的物体(车身)的颜色有明显区别,在颜色中使用梯度计算的话,这种差距更为明显,所以使用Canny算子进行边缘提取,可以比较好的找到车牌对应的位置,但是同时也会存在很多别的边缘,例如车身边缘与道路边缘等等,所以还需要后面继续处理。
这里的方法是首先使用线性的结构元素对于Canny算子计算得到的边缘图像进行腐蚀,其目的在于找到线性的边界位置,然后再使用矩形结构的元素遂于图像进行聚类与填充。腐蚀后的结果以及填充后的图像如下图所示:


可以从上面的结果看出,图像中还有许多的“噪声区域”,车牌的位置相比于这些“噪声区域”来说面积均比较大,所以这里从对象种移除面积小于2000的小对象,即进行形态学的滤波。其结果如下:

5.2.2 车牌的定位
进行车牌的定位的话,首先应该进行车牌的粗定位从而确定车牌的行列的起始位置和终止位置。这里直接对于上一步经过填充后的图进行白色像素点的统计,使用行方向像素点值的累计和和列方向像素点值的累计和来选择概率最大的车牌的位置。经过粗定位后的车牌的图像如下图所示,其行列方向的像素点值的累计和的图像见下图:



下面对于图像进行精定位。其主要工作之一就是去除车牌两侧的边框干扰,这里选择的方法是从四个边界向中心“推进”,以1为步长。遇到白色的区域即截止,遇到黑色值的点截止,并标记。从而最终得到精确定位的车牌的二值图像。最终的图像如下,这里我也在列方向对于像素点的灰度值进行了形态学的累计和。


5.2.3 字符的分割
这里采用的是倒序分割。其原因在于第一个字符一般为汉字,对于汉字的识别比较差,因为汉字本身比较复杂,而且本身数据集中图像分辨率就比较差,而且对于有偏旁部首的汉字,很容易就会将其分割为多个汉字。但是对于数字和字母来说其结构一般比较简单,所以这里采用倒序的分割方法。
具体的分割方法是,使用MATLAB自带的函数对于连通区域进行判断与定位,并将其初步使用bbox进行定位。接着对于所有的bbox分别计算他们在水平和竖直方向上的长度,并将这个平均长度视为每一个文字区域的长度,在竖直方向也一样,将平均的宽度视为每一个文字区域的宽度。但是对于水平方向还需要如下的进一步细分,还是判断在每一个文字区域内的连通区域,一般来说如果分类正确应该在每一个文字区域中只有一个连通区域(这里的中文由于进行了开运算,也是可以看作为一个连通区域,即使文字出现了偏旁部首)。如果发现了多个(一般为两个或者三个)连通区域,那么就将切割范围在水平方向上进行细微的调动,直到完成每一个文字中有且只有一个连通区域的目标。
最终的字符切割的结果如下:

5.2.4 字符的车牌识别
这里使用的与上面所描述的车牌识别方法完全相同,就是使用字符的匹配法。具体来说,使用分割所得的字符图片与模板点乘完后,我们对于点乘后的图片(矩阵),再进行连通区域的标定,并且计算出其最大的面积,使用这个最大的面积与模板在进行MSE的计算,对于一个字符区域与每一个模板进行上述的操作,从中找到一个MSE最小的标定块,并认为其就是与字符相同的模板。这也就达到了识别的效果。最终的上面的识别结果为:
进行点乘完后,我们对于点乘后的图片(矩阵),再进行连通区域的标定,并且计算出其最大的面积,使用这个最大的面积与模板在进行MSE的计算,对于一个字符区域与每一个模板进行上述的操作,从中找到一个MSE最小的标定块,并认为其就是与字符相同的模板。这也就达到了识别的效果:

5.3 基于图像增强的方法
这里的图像增强是主要考虑到图像的分辨率比较差,而且有部分的车牌数据是在黑暗的环境下的图像,且有部分的车牌比较“陈旧”亮度与新车牌不同,肉眼所见都比较模糊,所以这里在进行图像预处理的时候首先进行了图像的增强。
这里采用的图像增强的方式是使用了原始图像与背景图像做减法,从而突出待识别区域的“亮度”。再使用上述的方法就可以提高识别效果,这里的图像增强的结果如下图(依次为原始的黑白图像、背景图像以及增强后的图像):



这里我还考虑到使用《数字图像处理》课程中介绍的Top-hat(顶帽)或者是Black-hat(黑帽)等形态学滤波方法进行图像的增强,结果发现效果并不好,故不再使用这种方法。使用Top-hat的具体结果如下多图(分别为原图和算法处理后的图)。


6 实验结论与所思所想
本次实验我将自动定位、分割和识别汽车车牌这个任务分成了六个子任务来做,分别是图像的预处理、车牌的粗定位、车牌的精定位、车牌区域切割、字符切割以及字符识别。其中我的实验重点在图像的预处理这一部分,因为这一部分与课上所讲授的知识最贴合,而且对于最终的识别结果影响最大。
在图像的与处理中我分别使用了连通区域、开闭运算、图像聚类(图像填充)、基于形态学滤波、基于卷积的特征提取与矩形度的约束、图像增强(Top-hat以及Black-hat等方法)以及Canny等边缘检测等方法进行图像的预处理。从而得到了非规则的车牌可能出现的区域。
在车牌的粗定位处理中,我主要使用了基于统计学的方法对于图像进行水平方向和竖直方向的二值化图像的像素点值的累计和进行分析并初步确定车牌的矩形区域并删去面积小于一定阈值的区域。
在车牌的精定位处理和车牌区域切割中,首先进行二值化以及形态学的开操作(去除噪音),并使用角度变化使得车牌变水平,方便后面的车牌和字符切割操作。再对于周围的黑色边框进行去除,这个车牌的最终的区域。
在字符切割方面,通过连通区域和基于统计学的方法对于图像进行水平方向和竖直方向的二值化图像的像素点值的累计和对于每个字符的位置进行判断,从而得到最终的每一个字符的位置。
最终的字符识别方面,通过事先已经准备好的模板与我们的切割后的单个字符进行匹配,选择MSE最小的模板对应的文字(数字或字母)作为最终的字符识别的结果。
最终的结果,我的算法以及后面实现的一些单独步骤的算法可以在某些车牌数据中取得100%的识别结果(蓝色底色的),但是对于大部分的数据识别效果还是比较差。原因如下,首先车牌的数据相比于成熟算法所以用的数据集分辨率较差而且车辆(车牌)的尺寸明显较小,需要比较精细的定位。而且,图像中存在夜间以及不同环境下的图像,车牌的背景颜色不同,甚至有的车牌不是单行的,这导致对于算法的泛化性能要求就变高了。最后,可能自己的理论知识、实践能力以及代码能力比较差。
这个大作业可以从以下的几点进行改进:首先我算法中使用的前提是蓝色的背景的车牌,对于白色和黄色为背景颜色的车牌识别效果很差,所以这里可以使用边缘检测的方法对于车牌的位置进行寻找。这样可以进一步增加车牌识别的鲁棒性能。然后车牌的切割时,应该考虑到每一个字符的位置基本是确定的(国家应该有标准),所以可以以此作为一个约束进行车牌中字符位置的判断。另外,在图像的预处理方便,可以对于在黑夜中的信息进行图像的增强,对于分辨率很低的图像进行超像素等工作,来进一步提高字符切割以及字符识别的准确度。
7 实验心得与收获
本次实验通过传统的数字图像处理的算法进行车牌的自动定位、分割、识别,我个人觉得最大的收获在于,我们没有使用现在比较火热的深度学习的方法进行以上的工作,而完全使用传统的数字图像处理的方法进行识别。使用深度学习的我们或许根本就不会对于整个问题进行深入的分析,直接将其作为一个目标识别问题使用YOLO或者Faster RNN等网络进行定位车牌,再使用基于深度学习的OCR进行字符的识别,例如CRNN深度学习网络。这根本达不到我们分析问题解决问题的能力。
参考文献
[1] Yang F, Yang F. Detecting license plate based on top-hat transform and wavelet transform[C]//2008 International Conference on Audio, Language and Image Processing. IEEE, 2008: 998-1003.
[2] Anagnostopoulos C N E, Anagnostopoulos I E, Psoroulas I D, et al. License plate recognition from still images and video sequences: A survey[J]. IEEE Transactions on intelligent transportation systems, 2008, 9(3): 377-391.