David silver 强化学习公开课笔记(一):介绍
1 废话
一星期前上完了 Davild silver 的强化学习的公开课,记了些笔记,为了再巩固一下,写几篇博客总结一下,毕竟能讲清楚和能听懂还是有很大差距的。先介绍一下 David silver 吧,Alpha go 的项目负责人, 也是 nature 上 alpha go 那篇论文的一作加通讯作者,在强化学习领域,Deep mind 和 Open AI 可以说独领风骚吧,所以 David silver 的课还是很值得一看的。很多人推荐的 Richard Sutton 的书我没看,近期也没打算看,感觉这门课比较基础,通过这门课就算是把基础给打了,打算总结完过一段再看看伯克利的那个强化学习课,更加深入一下。好了,废话不多说了,开始总结。
2 整体介绍
首先做一个整体的总结吧,这节课一共是10节课,我在bilibili上看的,分享两个链接,一个是没有字幕的但比较清晰的:https://www.bilibili.com/video/av10576305,另外一个是有中文字幕的,但画质较模糊一些:https://www.bilibili.com/video/av9831889。还有课程的课件,包括每节课的PPT和最好的考试及答案,网页链接为:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
这节课共10节课,每节课所讲的内容如下:
(1)Introduction to Reinforcement Learning
(2)Markov Decision Process
(3)Planning by Dynamic Programming
(4)Model-Free Prediction
(5)Model Free Control
(6)Value Function Approximation
(7)Policy Gradient Methods
(8)Integrating Learning and Planning
(9)Exploration and Exploitation
(10)Classic Games
前几节课听得还可以,后几节课听的稍微有点懵逼,希望我总结一下可以理解的更深刻一些吧!下面就按照顺序进行总结,最后再写一个整体的总结,争取每一节课写一篇博客吧~
3 第一节课:强化学习介绍
3.1 概述
说起强化学习,大家一定都会想到监督学习和无监督学习。简而言之,监督学习需要知道期望输出,而无监督学习不需要,也就是说监督学习需要我们告诉他正确的结果,而无监督学习不需要。但是强化学习是什么呢?我举一个简单的例子,也是我最爱的例子来说明:就是婴儿学习走路的过程:
婴儿期初是不知道怎么走路的,于是随机尝试着走路,但是开始走不稳,就会摔倒,摔倒了呢就会感觉到疼痛,于是下次就不这么走了,就这样反复尝试,就学会走路了。
强化学习也是不需要告诉它正确的结果的(不能直接告诉婴儿每个关节转多少度,每块肌肉用多大的力),而是只需要告诉它它做的对不对(摔倒与否),或者说是给它的行为做一个打分,做的越好打分越高,做的越不好打分越低(摔倒的疼痛高,走的越差,走的越慢,摔得越疼),它自己反复尝试最终做的趋于最好(学会走路)。
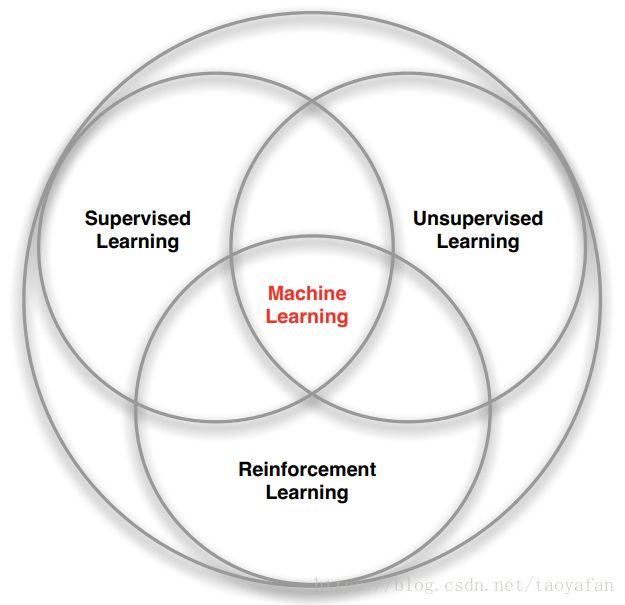
我一直认为强化学习就是无监督学习中的一种,但是看 david 的课感觉并非如此,他对于这三种学习方式是用了图1来描述,可见三者互有交集,当然我们也不过分纠结于此,没准发展着发展着发现其实他们是一个东西呢。
3.2 基本名词解释
3.2.1 Agent 和 Environment
在介绍其他名词前我们必须先介绍这两个对象,因为一切都是基于这两个对象而存在的。还以婴儿学习走路来说明,agent 就是婴儿,就是尝试学习某一件事的智能体。environment 就是婴儿之外的物理世界。agent 在运动的过程中会与 environment 交互,而交互的结果就由environment 反馈给 agent。图 2 中大脑就是 agent,地球就表示的 environment 。而接下来要介绍了 action,reward 和 observation 也在图中展现出来。

3.2.2 Action
Action 即为 agent 每次尝试的动作。
3.2.3 Reward
agent 每次 执行完某一个 action 后, environment 会反馈一个结果,也就是我在3.1中所介绍的得分,其实就是 Reward,agent 的行为做的越好,reward 就越高。
3.2.4 Observation
在婴儿学习走路的时候,他是能获得对环境的感知的,比如眼睛可以看到地是否是平的、脚可以通过压力感知到自己是不是站好了、身体还可感知到重心是不是偏了等等,这些 agent 感知到的环境信息我们称之为 observation。
3.2.5 State 和 History
history 就是一个序列,包括了过去的所有 observation、action 和 reward。相当于婴儿过去的每一次的经历的总和。
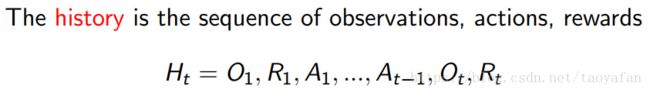
state 表示 agent 目前所在的状态,用来决定未来将会发生什么,他其实是对于 history 的一个函数。

3.2.6 三种 State
三种 state 分别是 agent state,environment state 和 information state。
agent state 为 agent 内部状态,其作用为得到 observation 后决定输出的 action。
environment state 是环境的内部状态,其作用为得到 agent 的 action 后决定输出的 reward 和 observation。
information state 也就是 Markov state(马尔科夫状态),他包含了历史所有有用的信息。它的定义如下:

3.2.7 Policy
中文名为“策略”,在婴儿学走路的例子中,婴儿根据当前的状态和感知到的信息来决定下一次的动作,那这个动作是如何决定的呢,其实就是根据自己的 policy 决定的,如果当前的状态包括的当前的 observation,那么,policy 就是 state 到 action 的映射。定义为如下式子:

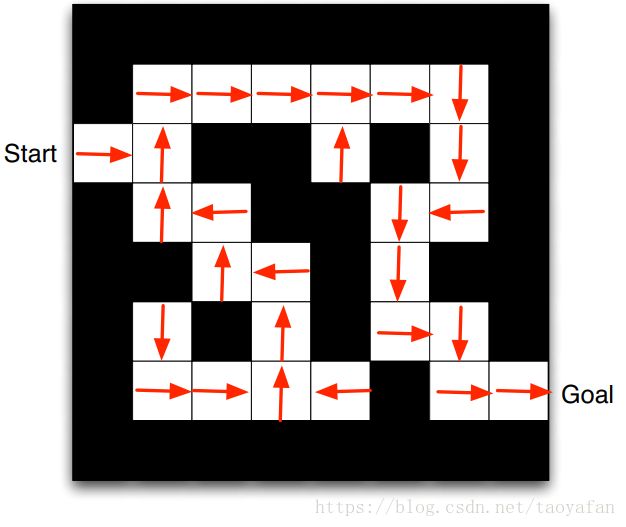
举一个走迷宫的例子,如图3所示,reward 为每走一步-1,action 为上下左右走一步,state 为 agent 的位置。

那么,policy 就表示为每个 state 应该向哪个方向走,如图 4 所示。
3.2.8 Value Function
这里是“值函数”,其实值函数有两种,第一节课上并没有说清楚,一种是状态值函数,一种是动作值函数,课上讲的其实就是状态值函数。
状态 S 的值函数的含义为:从 S 状态起到终止状态,能获得的 reward 是多少,表示一个状态的好坏程度。当然未来的 reward 与状态 S 可能有关系,但并不一定是决定性的关系,所以通过未来的 reward 计算 S 状态的值函数时会加一个“折扣”。状态值函数定义如下式:
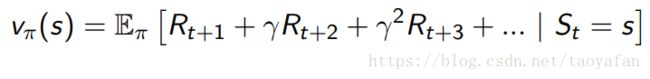
在迷宫的例子中,值函数就表示从当前位置走到终点后得到的 reward 之和(“折扣”为1),如图 5 所示。

动作值函数表示某一个动作的好坏,这在后面会详细讲解。
3.2.9 Model
模型预测 agent 做出 action 后将会得到什么样的 reward 和 state。在婴儿学走路的例子中,model 就是预测他用某个动作走一步后会不会摔倒、会不会重心不稳、会不会站稳等(动作完成后的 state 和 reward)。Model 可以用两个变量来表示:

同样的在迷宫的示例中,model 即预测每走一步后的 state(位置)和得到的 reward,如图 6 所示,但是下一次的 state 未表示出来。

3.3 强化学习的分类
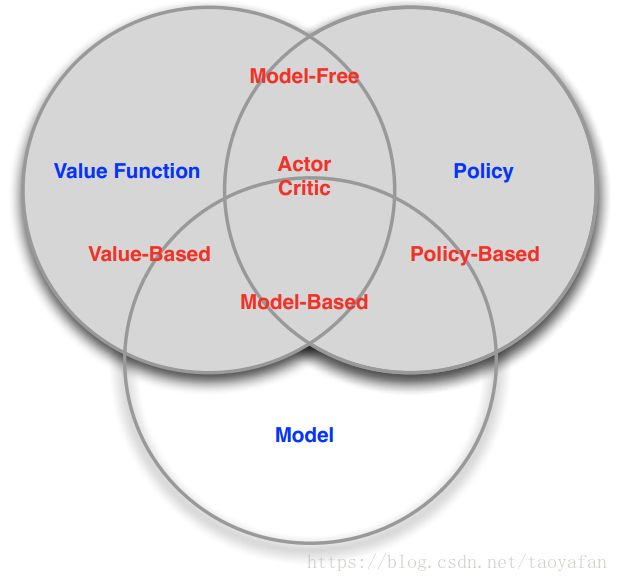
有两种分类方式,且互有交叉。第一种分为 value based、policy based 和 AC,如图 7 所示。

第二种分类基于有无模型进行分类,分为 model free 和 model based 如图8所示。

两种分类方式及几种类别的关系如图 9 所示:
3.4 Exploration(探索)and Exploitation(开发)
这部分内容是对学习过程中 policy 选择的讨论。就比如我们吃饭,很多餐厅是我们吃过的,而有一些餐厅我们没有吃过,那么我们到哪里吃饭呢?这里其实有两种选择, 一种是到没吃过的地方尝尝鲜,但是我们并不知道他好吃不,这就是 exploration;还有一种情况就是去我们吃过最好吃的地方去吃,这就是 exploitation。课程中对两者的定义如下:

3.5 Prediction 和 Control
这两者我在上第一节课的时候并没有搞懂,也是后边详细讲解的时候才明白的。其实也很简单。
所谓 prediction,就是给定一个策略,我去预测未来(通常是计算值函数)。
所谓 control,就是找到一个最佳的策略,去最大化未来的受益(计算值函数的同时更新策略,使得策略最优)。
4 最后的废话
终于写完了,太不容易了,本来计划1个小时写一节课,但是最终竟然写了2个多小时,稍微有点浪费时间了,不过还是希望对我以后有帮助吧,忘了可以回来再复习复习,毕竟博客上写的还是比我的笔记清晰的。