linux下部分文件管理类基本命令汇总以及bash展开特性介绍
一、文件管理类基本命令
1.1、表格汇总
今天要讲解的命令如下表所示,按照外部命令和内建命令做基本划分:
内建命令列表:
| 命令名字 | 基本说明 |
|---|---|
| file | 检测文件类型 |
| cd | 改变shell的工作目录 |
| dirs | 显示目录堆栈信息 |
| popd | 从堆栈中移除目录 |
| pushd | 向堆栈中添加目录 |
外部命令列表:
| 命令名字 | 基本说明 |
|---|---|
| ls | 列出目录内容 |
| tree | 以"树状"格式列出目录内容 |
| pwd | 打印当前工作路径的名字(是一个绝对路径) |
| echo | 显示文本行 |
| cat | 连接文件内容,并打印到标准输出 |
| tac | 连接文件内容,颠倒输出,最后一行输出到第一行 |
| paste | 合并文本行 |
| rev | 反转一个或多个文件内容的行 |
| nl | 把指定单个或多个文件内容打印到标准输出并附上行号,多个文件内容按先后顺序标记上行号 |
| wc | 统计文件行数或字节数,或单词数 |
| more | 分屏不可逆文本查看器(对于大文本建议用more或less替代cat来查看文本内容) |
| less | 分屏可逆文本查看器(对于大文本建议用more或less替代cat来查看文本内容) |
| pr | 给文本输出加上标题并按照指定行数或者默认行数分割多个页面输出 |
| locate | 根据名字查找文件(find工具比较强大,我后续会有专题,本部分不会引入) |
| head | 输出文本的起始部分内容 |
| tail | 输出文本的尾部部分的内容 |
| tailf | 跟踪日志文件内容(调试工具之一) |
| sort | 排序文本文件行内容 |
| uniq | 报告或删除重复的行 |
| fmt | 简要优化格式化输出文本内容 |
| printf | 格式化输出文本内容 |
| column | 格式化输出文本,按照指定字符控制输出多列(有点和awk某些用法类似) |
| colrm | 列删除工具 |
| join | 通过相同字段来连接文件的行 |
| od | 以八进制或者其他格式转储文件内容(常用于查看二进制文件) |
| hexdump | 以ascii,十进制,16进制,八进制显示文本内容(常用于查看二进制文件) |
| cp | 复制文件或目录(文件) |
| mv | 移动或重命名文件 |
| touch | 改变文件时间戳属性(可以创建普通文本文件) |
| mkdir | 创建目录(文件) |
| mkfifo | 创建命名管道(有名管道)文件 |
| rmdir | 删除空目录(文件) |
| rm | 删除文件或目录(危险基础指令top10之一) |
| ln | 在文件之间做链接关系 |
| du | 评估文件实际空间使用情况 |
| tr | 转换或删除字符 |
| split | 把文件切割成多个零碎的部分 |
1.2、详细解析
1.2.1、ls
语法结构:ls [OPTION]... [FILE]...
其中OPTION表示选项,可以省略不用。FILE表示查看的文件,也可以省略,可以多个。这里
的文件表示的是广义的文件,可以是文本文件,目录文件或者其他特殊文件等。
常见选项以及含义:
-a, --all:隐藏文件也会被列举出来
-l:长格式显示列出的文件
-i, --inode:打印列出文件的索引编号
-d, --directory:列出目录文件本身,不是目录下的文件内容
-R, --recursive:列出包含子目录在内的目录和文件(递归列出)
-h, --human-readable:结合-l选项一起用。因为这个选项是和文件分配占用大小有关的(不一定是实际占用大小),
显示易读的大小属性,例如1K,234M,2G等
-Z, --context:显示SElinux安全上下文属性信息
举例子:
a.>查看隐藏目录
从图中可以看出,以符号"."开头的文件或目录文件都被列举出来了。这里补充说明一下,linux下,除了以符号"."开头的是隐藏文件外,在每个路径目录下,都有两个特殊的目录,它们分别是".","..",其中"."表示当前目录,".."表示当前目录的上级目录,至于为什么有这两个目录,这就是工具C语言源码实现定义的两个特殊属性。
b.> 长格式输出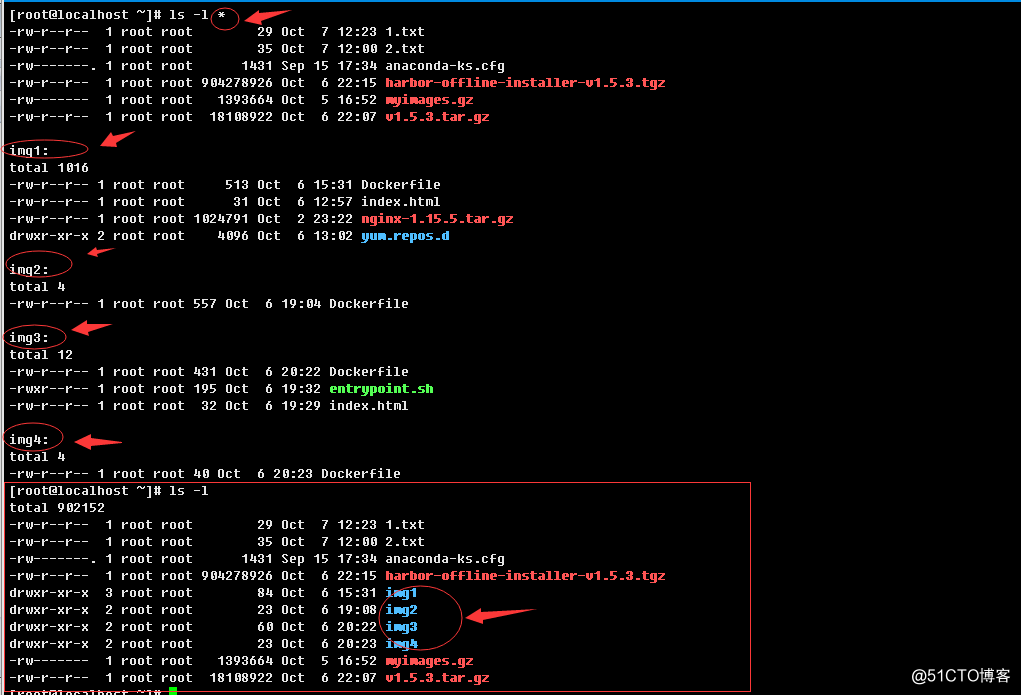
长格式输出非常有用。我们简单来说说每一列的含义:
第一列:对象权限属性和selinux标志或acl权限标志
第二列:对象硬链接数
第三列:对象所有者(属主)
第四列:对象所有组(属组)
第五列:对象大小属性,此大小仅供参考,实际占用大小请用其他工具统计(例如du),例如稀疏文件以及其他特殊文件,
这一列的值不一定准确。
第六列:对象mtime属性中的月份英文缩写
第七列:对象mtime属性中的日数字
第八列:对象mtime属性中的时分
第九列:对象本身名字
额外说明:当ls -l查看的是字符设备或者块设备时候,条目属性共有9列,第四列表示的不是
属组了而是硬件类型,第五列表示 的不是对象大小属性而是硬件的主次版本号(主和次
版本号之间用逗号隔开),其他列和普通对象一致。
这里关于第一列做一下补充说明,最后权限位之后的最后一位可以为"空格"或"."或"+".
如果没有SElinux上下文标识,也没有acl权限属性,就用空格;
如果没有SElinux上下文标识,但是有acl权限属性,就用加号;
如果有SElinux上下文标识,没有acl权限属性,就用点号;
如果有SElinux上下文标识,且同时又acl权限属性,还是用加号;
请参考下面的示例:
-rw-r--r-- root root ? a.file #没有SElinux上下文,没有ACL
-rw-r--r--+ root root ? b.file #只有ACL,没有SElinux上下文
-rw-------. root root system_u:object_r:admin_home_t:s0 my.cnf #只有SElinux上下文,没有ACL
-rw-rw-r--+ root root unconfined_u:object_r:user_tmp_t:s0 dd.c #有SElinux上下文,有ACL
c.> 查看inode编号
inode编号也分配消耗殆尽(正常控制情况下不会),inode的作用,我们要想知道原理,要对磁盘分区知识有了解才能
知道原理。暂时只需要基础,inode的引入是为了效率和方便管理,inode叫索引编号。
d.> 查看目录本身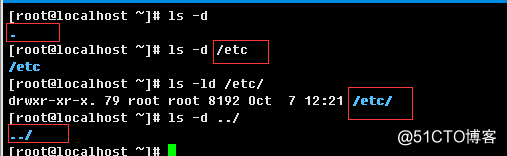
e.> 递归查看目录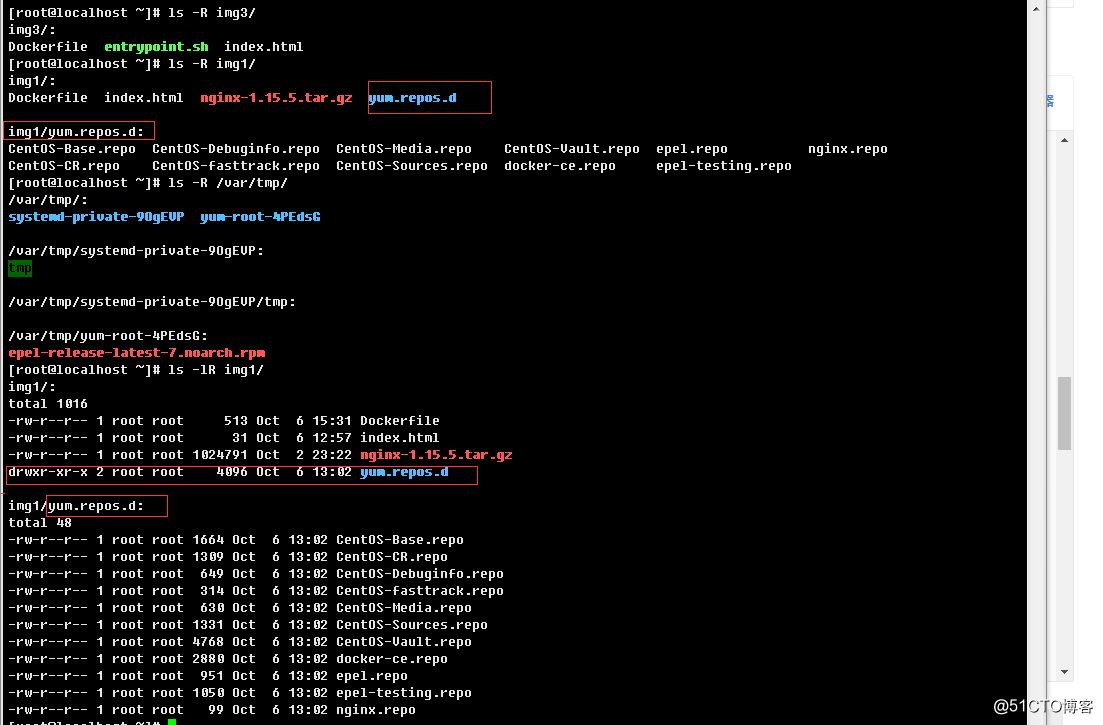
f.> 长格式输出易读的文件大小属性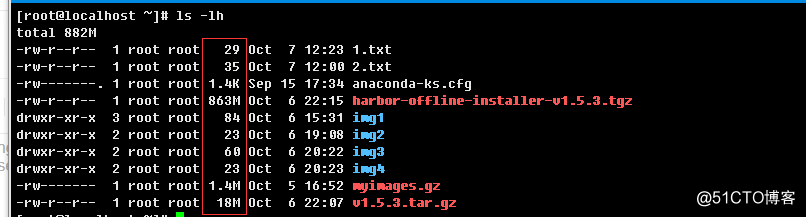
这里的易读,是文件空间预分配占用大小占用实际文件比率会自动转换成K,M,G等单位的数值。通常要配置长格式
输出来一起使用。因为长格式输出中有关于文件大小属性的记录。
g.> 查看文件selinux安全上下文属性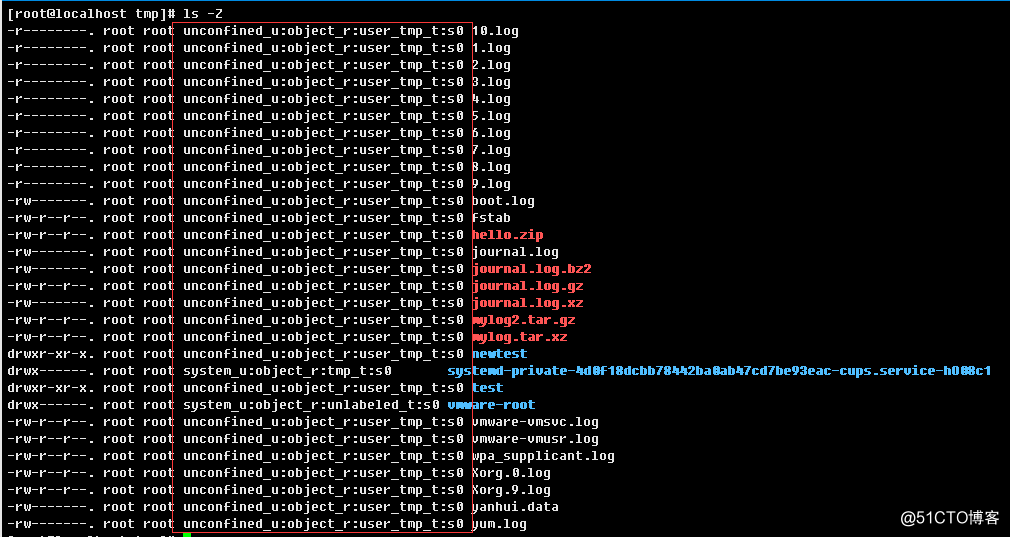
SElinux安全上下文属性比较复杂,暂时只需要知道,图中红色框框标记的就是安全上下文属性。如果关闭了
SElinux,正常情况框框中的部分在selinux关闭后对文件属性有变更的文件会显示符号"?",关闭selinux后,文件属性没有变化的,还是会显示其SElinux安全上下文属性。
列出目录内容
1.2.2、tree
语法结构:
tree [-acdfghilnpqrstuvxACDFQNSUX] [-L level [-R]] [-H baseHREF] [-T title] [-o filename] [--nolinks] [-P pattern]
[-I pattern] [--inodes] [--device] [--noreport] [--dirsfirst] [--version] [--help] [--filelimit #] [--si] [--prune]
[--du] [--timefmt format] [directory ...]
简化后:
tree [-L level [-R]] [--inodes] [directory ...]常用选项及其含义:
-L level:显示最大的目录树深度;
--inodes:显示inode编号信息;举例:
a.>简单用法以及指定具体树状深度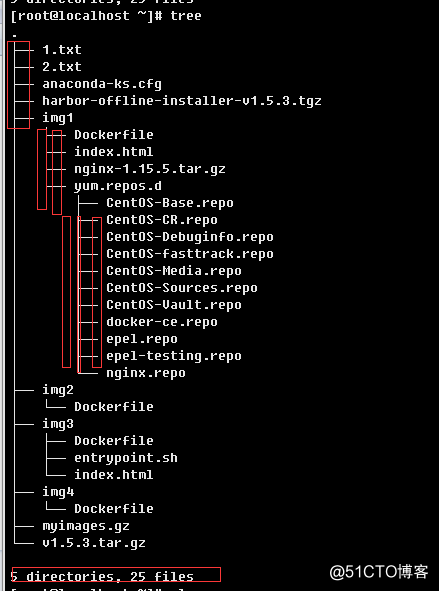
正常情况有多少层,就会显示多少层。切记不可在目录层级较多的目录做统计,统计会带来较大的io和cpu时钟消耗。可以通过-L指定统计的层级深度。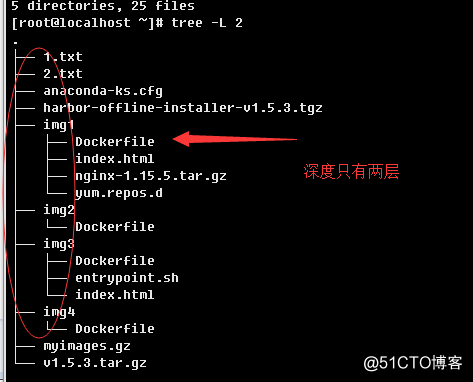
b.> 加上索引编号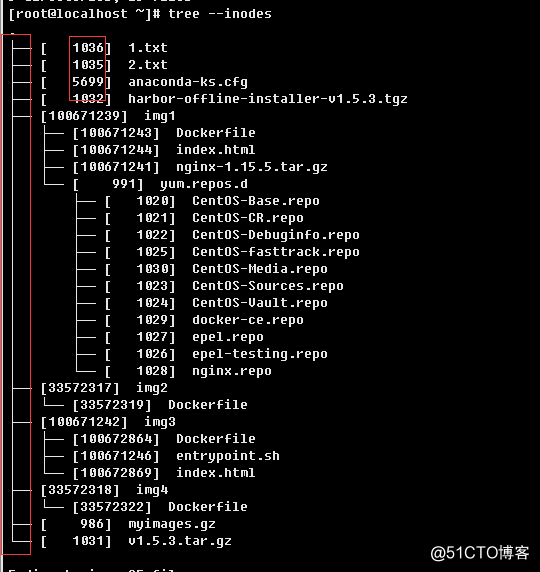
1.2.3、pwd
语法结构:
pwd [OPTION]...
选项可以省略
常用选项:无
用的最多的就是在一个环境下操作,命令行下,有时候不知道具体切换的深度,可以直接利用pwd打印出
当前所在工作目录。举例省略,打印的结果是一个以符号"/"开头的绝对路径。
1.2.4、echo
语法结构:
echo [SHORT-OPTION]... [STRING]...
echo LONG-OPTION
常用选项:
-n:不打印新换行符,默认会打印行尾的换行符
-e:解析反斜杠指定特殊字符含义
-E:默认选项。不解析反斜杠指定特殊字符的含义
特殊反斜杠字符含义:
\b backspace 退格
\n new line 新行
\t horizontal tab 横向制表符
\\ backslash 反斜线本身
\0nnn 八进制值表示的字节NNN(0到3个八进制数字)
\xHH 十六进制值表示的字节HH(1或2个16进制数字)特殊用法:标记颜色
echo命令可以修改字体类型,字体背景色以及字体颜色,
转义序列\033(八进制用法)可以用于改变字体属性。
要使转义序列生效,必须使用-e选项。
下面列出了部分转义代码:
[0m: 正常
[1m: 粗体
[4m: 字体加上下划线
[7m: 逆转前景和背景色
[8m: 不可见字符
[9m: 跨行字体
[30m: 灰色字体
[31m: 红色字体
[32m: 绿色字体
[33m: 棕色字体
[34m: 蓝色字体
[35m: 紫色字体
[36m: 浅蓝色字体
[37m: 浅灰字体
[38m: 黑色字体
[40m: 黑色背景
[41m: 红色背景
[42m: 绿色背景
[43m: 棕色背景
[44m: 蓝色背景
[45m: 紫色背景
[46m: 浅蓝色背景
[47m: 浅灰色背景
举例说明:
a.>正常使用,不加选项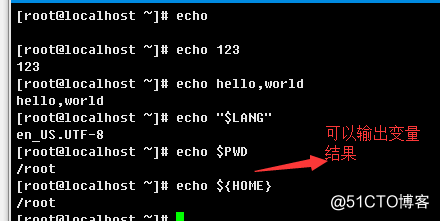
b.> 转移特殊字符,换行,横向制表符等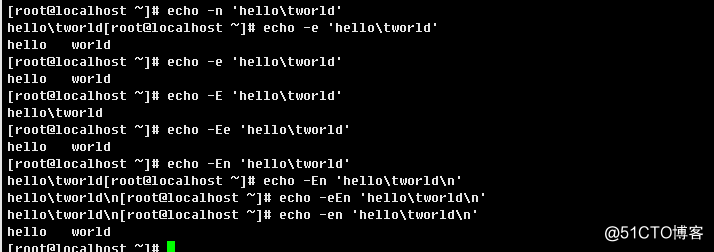
d.>打印颜色字体(加粗,下划线,字体色,背景色应用)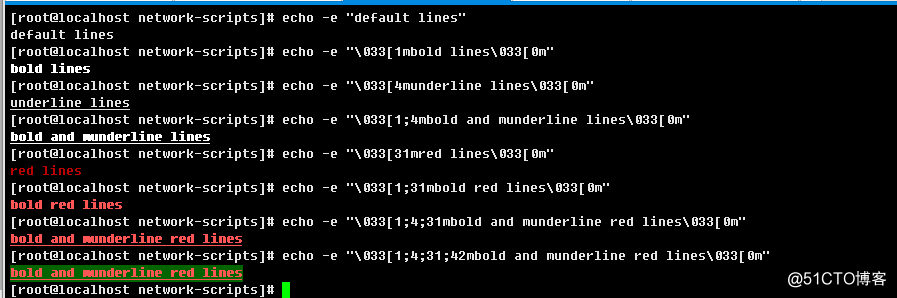
从上到下,依次输出:
正常字体,不带颜色;
加粗字体,不带颜色;
下划线字体,不带颜色;
下划线加粗字体,不带颜色;
正常字号,红色字体;
加粗红色字体;
加粗下划线红色字体;
加粗下划线红色字体,绿色背景色;
1.2.5、cat,tac
cat语法结构:
cat [OPTION]... [FILE]...
如果省略FILE,或者FILE为-,表示cat从标准输入中读内容。例如:
cat f - g:表示输出f的内容,标准输入,然后是g的内容;
cat:表示复制标准输入到标准输出。(从键盘中得到什么,屏幕就会显示什么)
PS:与管道以及重定向结合的方式,我们这里就不介绍了。常用的就一个
cat << EOF
......
EOF
tac语法结构:
tac [OPTION]... [FILE]...
以cat为例,tac类似。
cat常用选项:
-n, --number:显示行号;
-A:显示所有特殊字符(linux换行符用$表示,windows换行符部分的回车符用^M表示,横向制表符用^I表示)
-v, --show-nonprinting:use ^ and M- notation, except for LFD and TAB,这里可以勉强理为windows的回车用^M标记;
-T, --show-tabs:用^I来标记文本中的横向制表符;
-E, --show-ends:用$来标记每一行的末尾的换行符;
举例:
a.>查看一个或多个文本内容,输出不带行号
b.>查看一个或多个文本内容,输出带行号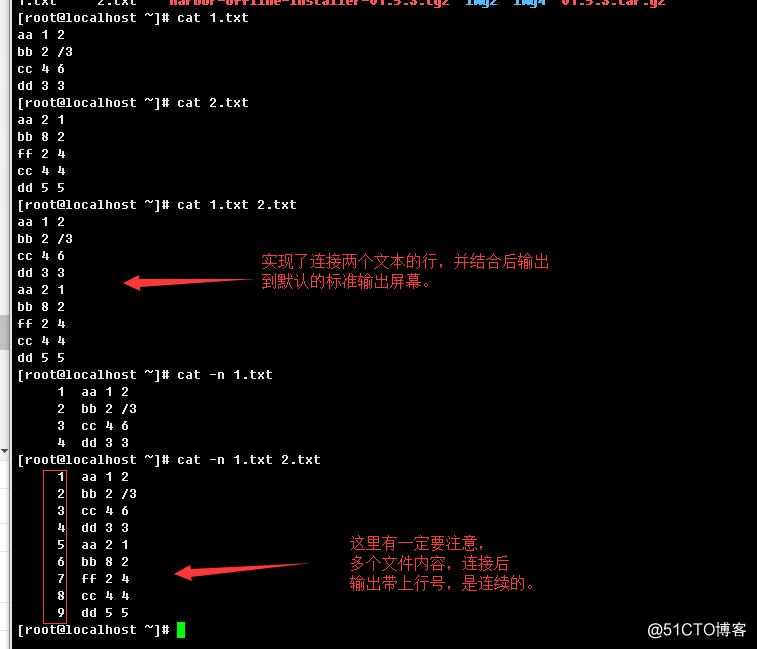
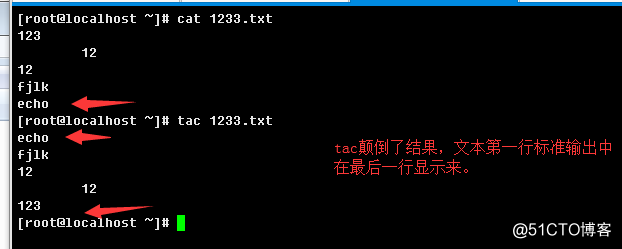
c.>显示所有特殊字符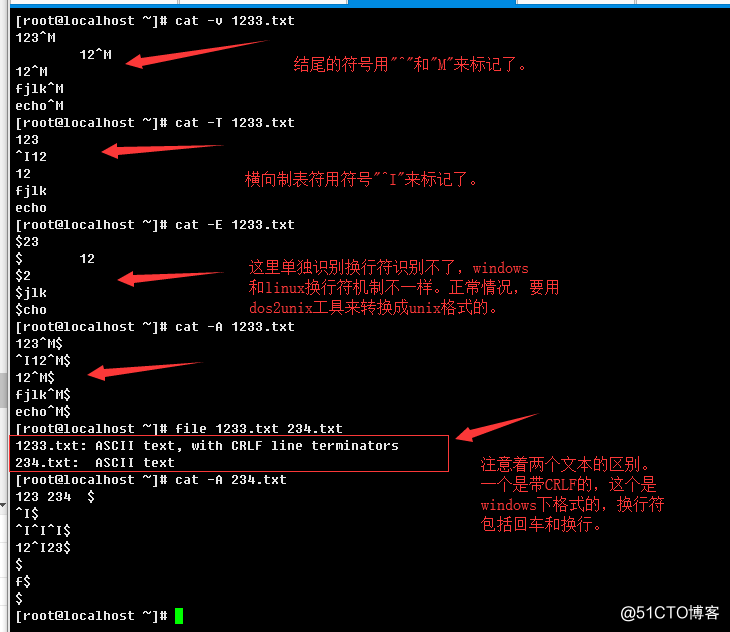
1.2.6、paste
语法结构:
paste [OPTION]... [FILE]...
常用选项及说明:
-d, --delimiters=LIST:粘贴文本之间的分隔符,默认是横向制表符
-s, --serial:一次粘贴一个文件而非并行粘贴举例: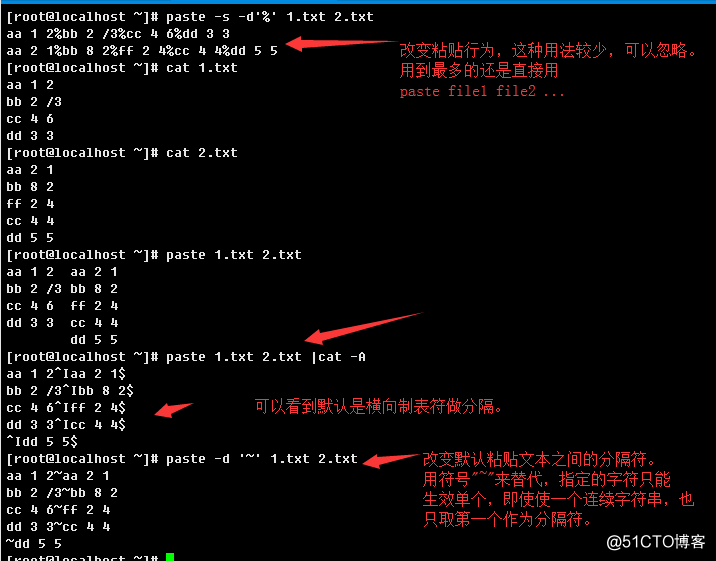
1.2.7、rev
语法结构:
rev [options] [file ...]
rev复制指定文本到标准输出,翻转每一行的字符的顺序。
无常用实际选项。与tac是有区别的,这个rev是针对行的字符的顺序。
例如: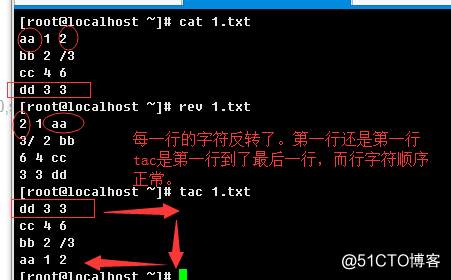
1.2.8、nl
语法结构:
nl [OPTION]... [FILE]...
给指定文件或标准输入(如果没有FILE或者FILE为-)的内容输出到标准输出(默认为屏幕),然后给每一行加上行号。
nl与cat -n相比,可以理解为nl专为页面行号设计的工具组件,包括行号相关的其他属性。cat -n只是有输出行号的功能。
选项:
-b, --body-numbering=STYLE 使用指定样式编号文件的正文行目
-d, --section-delimiter=CC 使用指定的CC 分割逻辑页数
-f, --footer-numbering=STYLE 使用指定样式编号文件的页脚行目
-h, --header-numbering=STYLE 使用指定样式编号文件的页眉行目
-i, --page-increment=NUMBER 设置每一行遍历后的自动递增值
-l, --join-blank-lines=NUMBER 设置数值为多少的若干空行被视作一行
-n, --number-format=FORMAT 根据指定的格式插入行号
-p, --no-renumber 在逻辑页数切换时不将行号值复位
-s, --number-separator=STRING 可能的话在行号后添加字符串
-v, --starting-line-number=NUMBER 每个逻辑页上的第一行的行号
-w, --number-width=NUMBER 为行号使用指定的栏数
默认情况下,选项设置为: -v1 -i1 -l1 -sTAB -w6 -nrn -hn -bt -fn.
CC是用来分隔逻辑页数时候的两个分隔字符,省略的第二个字符包含了“:”,表示"\"要转移"\\"
CC这两个字符可用值为:
a number all lines 对所有行编号(包括空行);
t number only nonempty lines 只对非空行编号;
n number no lines
pBRE number only lines that contain a match for the basic regular expression, BRE,只对
符合正则表达式BRE的行进行编号。
FORMAT可用格式:
ln left justified, no leading zeros,左对齐,左边没有前导"0"填充;
rn right justified, no leading zeros,右对齐,左边没有前导"0"填充;
rz right justified, leading zeros,右对齐,左边有前导"0"填充;
举例说明:
a.> 默认选项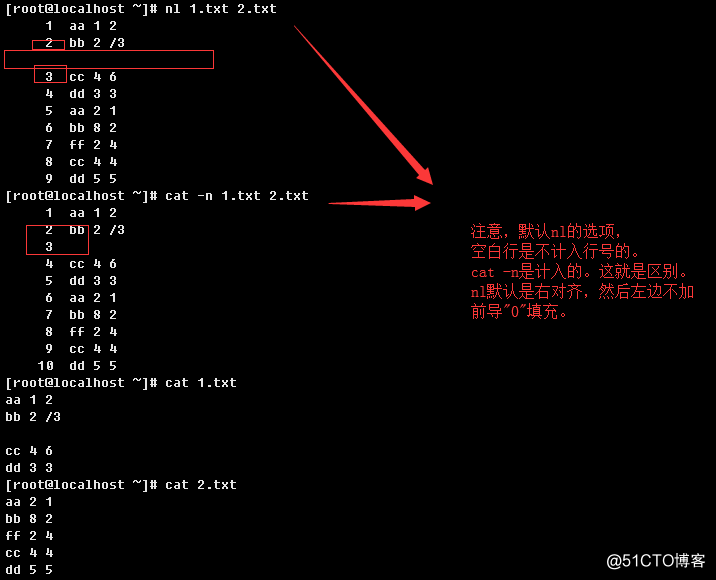
b.> 空行也计入行号
c.> 改变对齐方式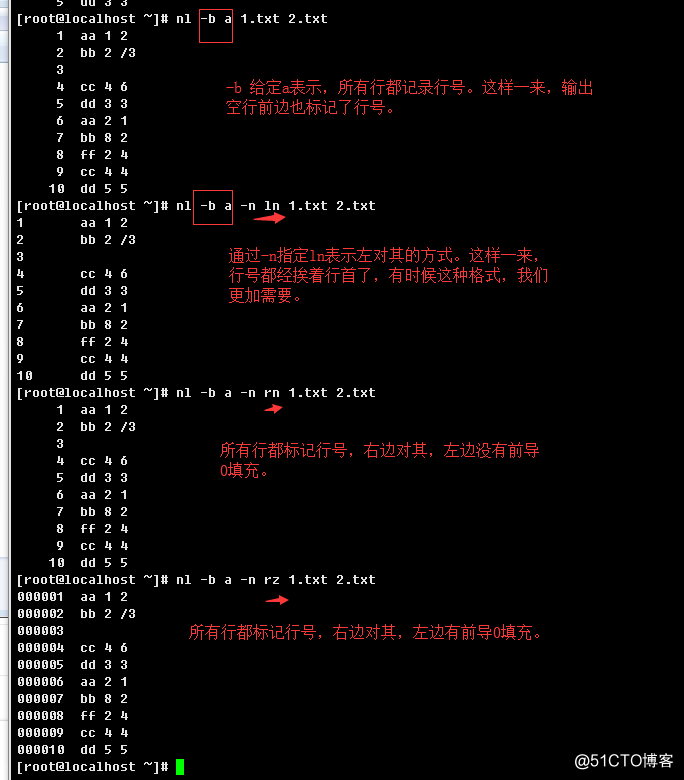
d.> 满足指定正则匹配的行进行行号标记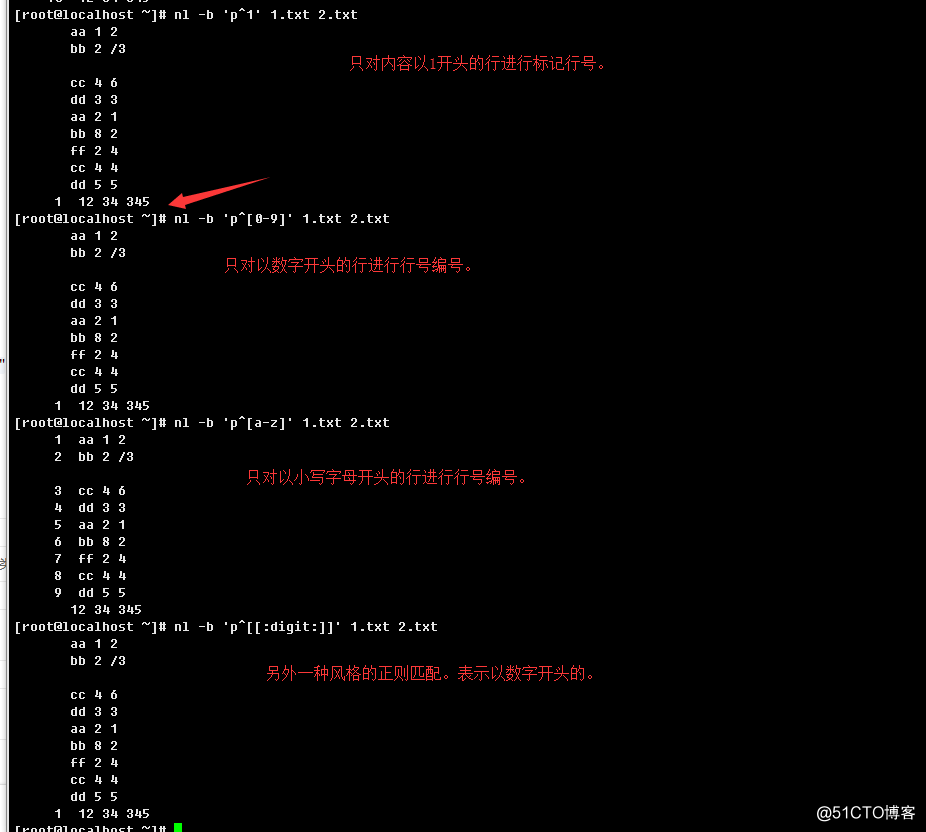
1.2.9、wc
语法结构:
wc [OPTION]... [FILE]...
wc [OPTION]... --files0-from=F
常用选项:
-c, --bytes:打印字节数量;
-m, --chars:打印字符数量;
-l, --lines:打印行数;
-w, --words:打印单词数量;
-L, --max-line-length:打印最长的行的字符长度;
--files0-from=F:从F指定的文件中读取FILE参数,F中指定的FILE后面要以符号NULL结尾,这个输入可以通过
在vim编辑模式Ctrl+k,然后输入NU即可(实际测试失败,具体原因不详)
举例子:
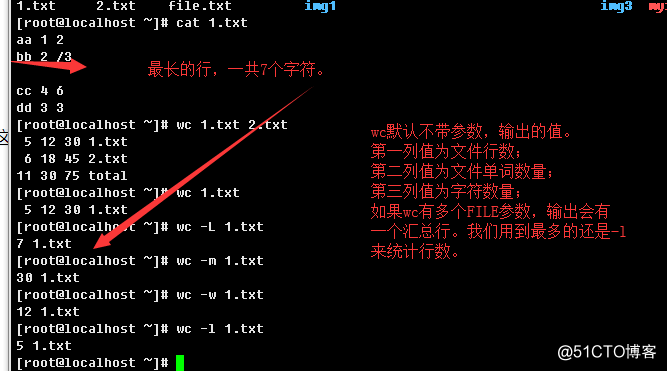
1.2.10、more
分屏不可逆文本查看器(对于大文本建议用more或less替代cat来查看文本内容)
语法结构:
more [options] file [...]
常用选项:
+number 从笫number行开始显示,例如+20表示从文本第20行开始显示;
-n 定义屏幕大小为n行,即每一屏幕显示n行;
+/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行开始显示。
-d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能
-s 把连续的多个空行显示为一行
在more查看交互式模式下可以允许执行的命令:
h :显示帮助信息;
SPACE:空格键表示向后滚动一屏;
Ctrl+F:向下滚动一屏;
Ctrl+B:往上滚动一屏;
回车键:每次一行往下走;
=:显示当前行号信息;
/PATTERN:查找匹配的行;
!command or :!command:执行shell命令;
q:退出;
1.2.11、less
分屏可逆文本查看器(对于大文本建议用more或less替代cat来查看文本内容)
大部分选项与more差不多,比more更加好用智能,不仅支持组合键,还支持方向键,上下一行一行切换。
选项:
-e:文件内容显示完毕后,自动退出;
-f:强制显示文件;
-g:不加亮显示搜索到的所有关键词,仅显示当前显示的关键字,以提高显示速度;
-l:搜索时忽略大小写的差异;
-N:每一行行首显示行号;
-s:将连续多个空行压缩成一行显示;
-S:在单行显示较长的内容,而不换行显示;
-x<数字>:将TAB字符显示为指定个数的空格字符。
/pattern:向下搜索“字符串”的功能
?pattern:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)
Ctrl+F:向前翻一页;
Ctrl+b:向后翻一页;
1.2.12、pr
给文本输出加上标题并按照指定行数或者默认行数分割多个页面输出
语法结构:
pr [OPTION]... [FILE]...
选项说明:
-h, --header=HEADER:为页指定一个标题;
-l, --length=PAGE_LENGTH:指定每页的行数;举例子:
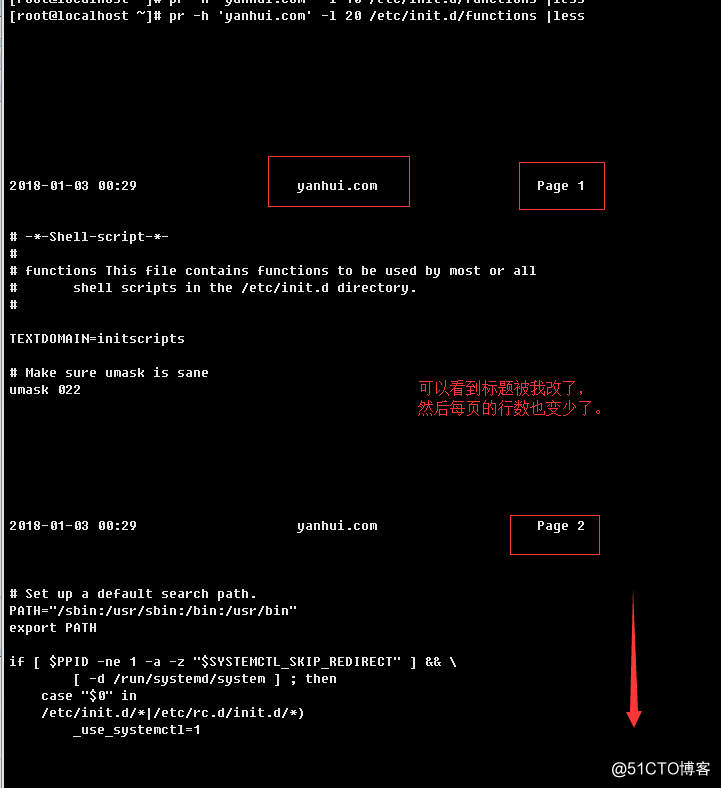
a.> 查看默认行为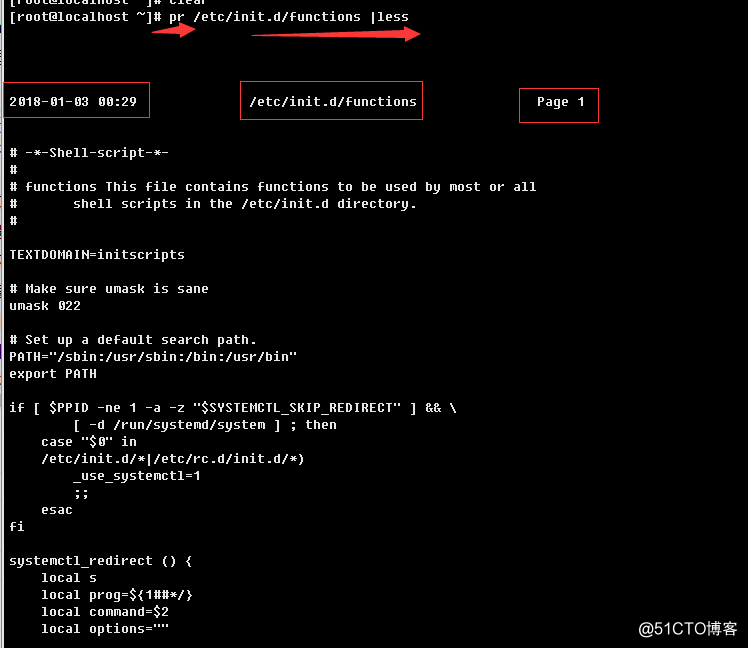
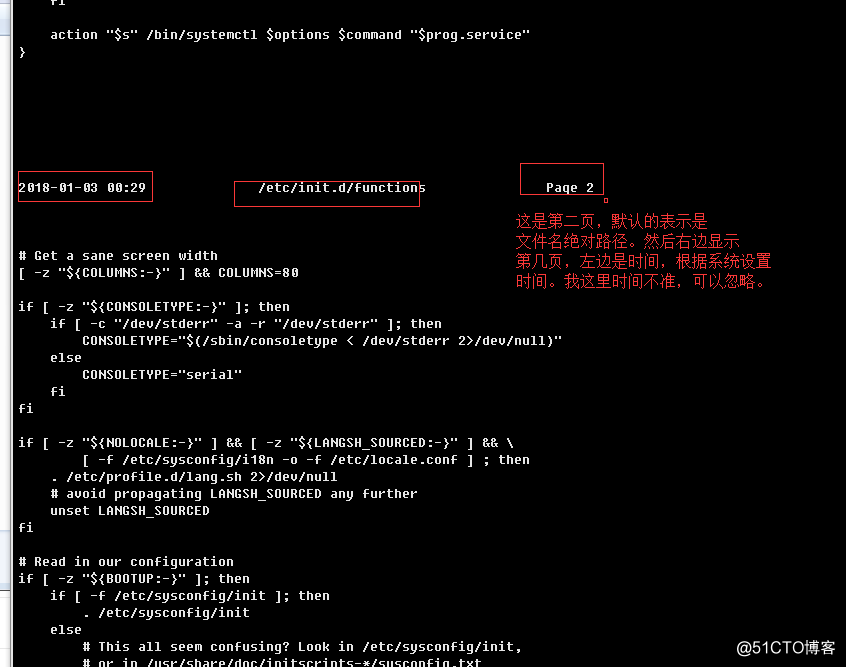
b.>显式指明标题和每页的行数
1.2.13、locate
摘抄:https://www.cnblogs.com/xqzt/p/5426666.html
locate(locate) 命令用来查找文件或目录。 locate命令要比find -name快得多,原因在于它不搜索具体目录,而是搜索一个数据库/var/lib/mlocate/mlocate.db 。这个数据库中含有本地所有文件信息。Linux系统自动创建这个数据库,并且每天自动更新一次,因此,我们在用whereis和locate 查找文件时,有时会找到已经被删除的数据,或者刚刚建立文件,却无法查找到,原因就是因为数据库文件没有被更新。为了避免这种情况,可以在使用locate之前,先使用updatedb命令,手动更新数据库。整个locate工作其实是由四部分组成的:
/usr/bin/updatedb 主要用来更新数据库,通过crontab自动完成的
/usr/bin/locate 查询文件位置
/etc/updatedb.conf updatedb的配置文件
/var/lib/mlocate/mlocate.db 存放文件信息的文件,数据库文件。需要通过命令updatedb来生成或者更新mlocate.db(/var/lib/mlocate/mlocate.db)这个数据库,否则会提示一下报错:
[root@localhost ~]# locate ~/1
locate: can not stat () `/var/lib/mlocate/mlocate.db': No such file or directory
常用选项:
-c, --count:输出匹配到的数量而非文件名;
-d, --database DBPATH:指定locate使用数据库的路径,替换默认的/var/lib/mlocate/mlocate.db;
-S, --statistics:统计信息,列出一些统计。
-q, --quiet:静默模式查找;
-i, --ignore-case:查找的时候忽略字母大小写;
-r, --regexp REGEXP:通过指定基本正则表达式模式匹配查找;
--regex:通过指定扩展正则表达式模式匹配查找;
举例子:
a.> 基本查找,查找root默认家目录下以数字1开头的文件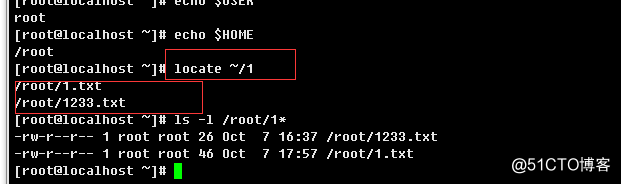
b.> 手动添加一个文件,立即查找该文件是否可以通过locate查找到,验证?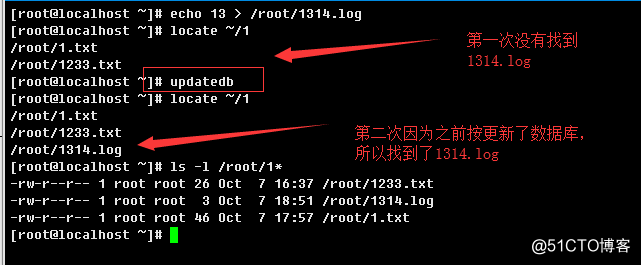
c.> 忽略大小写和不忽略大小写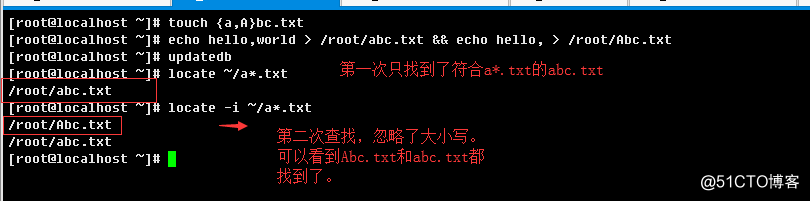
d.> 查看统计信息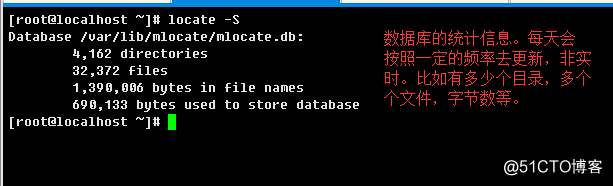
e.> 使用正则表达式(不允许指定文件查找路径参数,直接在根下查找,谨慎使用)
1.2.14、head
输出文本的起始部分内容
语法结构:
head [OPTION]... [FILE]...
常用选项:
-n, --lines=[-]K:指定显示文件开头的多少行内容,默认是10行;
-number:指定显示文件开头的多少行内容,是-n Number的简写;
-q, --quiet, --silent:如果head有读入多个文本,抑制文件标签部分的输出(默认会输出,分隔文件内容)。举例: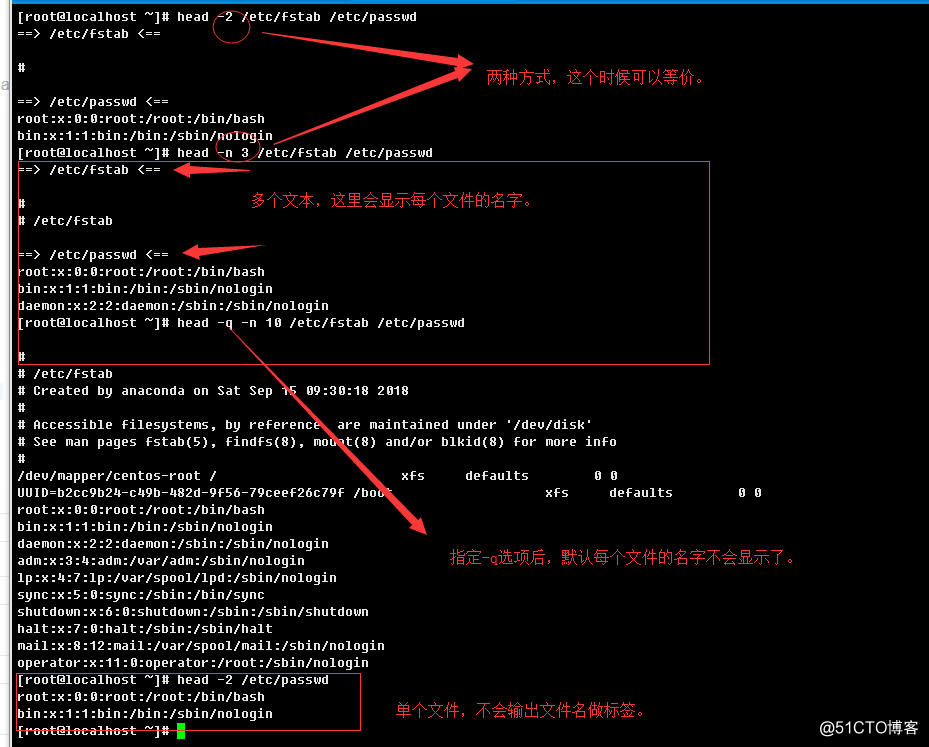
1.2.15、tail
输出文本的尾部部分的内容
语法结构:
tail [OPTION]... [FILE]...
常用选项:
-n, --lines=K:显示文本尾部指定多少行;
-Number:显示文本尾部指定多少行;
-f, --follow[={name|descriptor}]:当文件增长的时候,输出后边的内容.
常用组合:
tail -f FILE.log,显示10行内容,然后等待后续文件内容输出;
tail -n0 -f FILE.log,不再显示指定文件的10行,而是一行都不显示,后续如果文件有新增,会显示出来;
--pid=PID:常与-f一起调试使用。指定进程死掉后结束tail 这个进程。
-q, --quiet, --silent:如果tail有读入多个文本,抑制文件标签部分的输出(默认会输出,分隔文件内容)。
举例: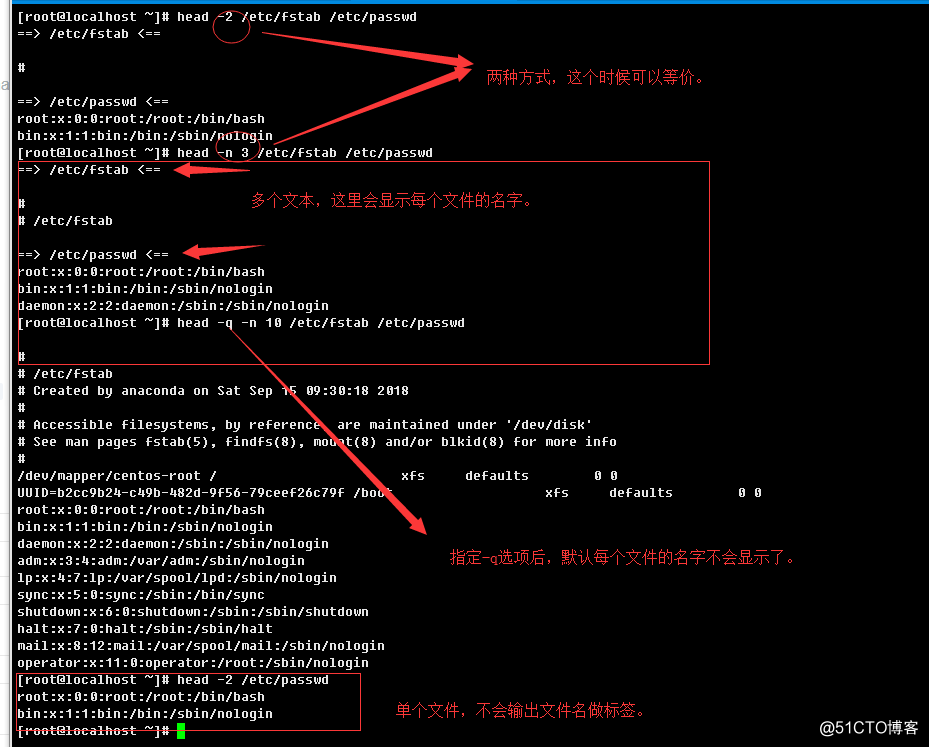
1.2.16、tailf
跟踪日志文件内容(调试工具之一)
语法结构:
tailf [OPTION] file
选项:
-n, --lines=N, -N:指定输出尾部的多少后并输出监视模式下;
tailf FILE.log
tailf -0 FILE.log
类似于tail -f的工具,不过要比tail -f性能要高,调试可以用这个工具。
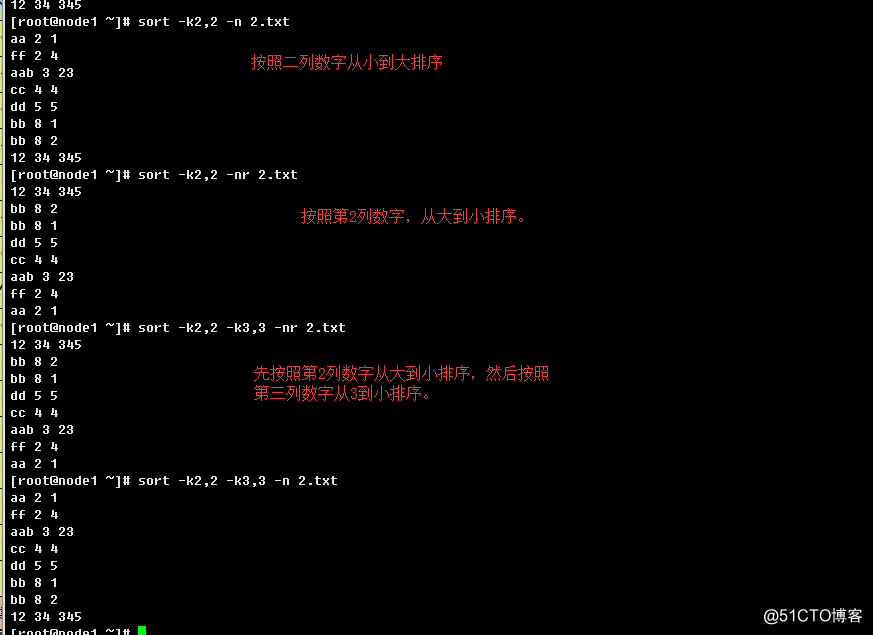
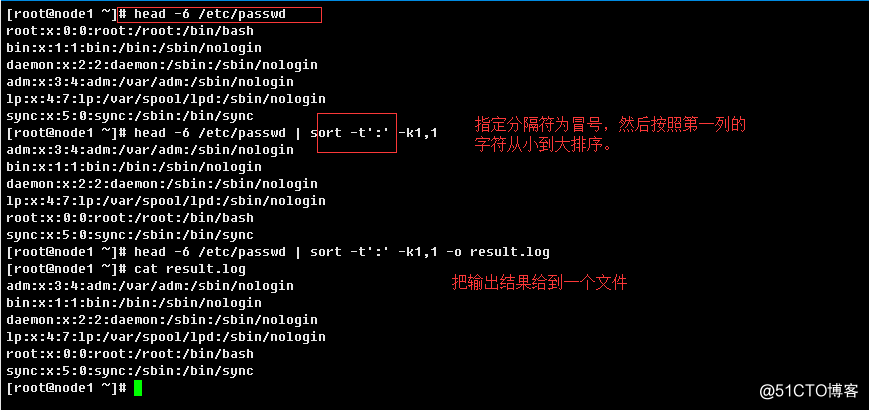
1.2.17、sort
排序文本文件行内容
语法结构:
sort [OPTION]... [FILE]...
sort [OPTION]... --files0-from=F
常用选项:
-t, --field-separator=SEP:指定单个分隔符(默认是空白)
-n, --numeric-sort:按照数字大小排序;
-r, --reverse:反转排序;
-o, --output=FILE:把排序后结果输出到指定文件中;
-k, --key=KEYDEF:排序的键起始位置
KEYDEF is F[.C][OPTS][,F[.C][OPTS]] for start and stop position, where F is a field number and C a character position in the field; both are origin 1, and the stop position defaults to the line's end. If neither -t nor -b is i
effect, characters in a field are counted from the beginning of the preceding whitespace. OPTS is one or more sin
gle-letter ordering options [bdfgiMhnRrV], which override global ordering options for that key. If no key i
given, use the entire line as the key.
SIZE may be followed by the following multiplicative suffixes: % 1% of memory, b 1, K 1024 (default), and so on for
M, G, T, P, E, Z, Y.举例: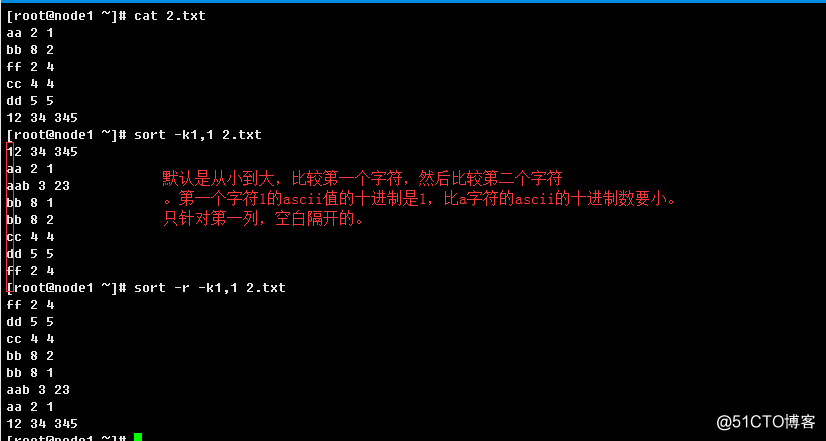
1.2.18、uniq
报告或删除重复的行
语法结构:
uniq [OPTION]... [INPUT [OUTPUT]]
常用选项:
-c, --count:在每列旁边显示该行重复出现的次数(要紧挨着的重复行才会计算次数);
-u, --unique:显示非重复行,连续的相同的都被忽略;
-d, --repeated:只输出有重复的行(既连续两个以及以上向同行),满足条件的行只输出一次;
-D, --all-repeated[=METHOD]:输出所有重复的行(只有连续两的行才算重复的行);
-i, --ignore-case:
举例: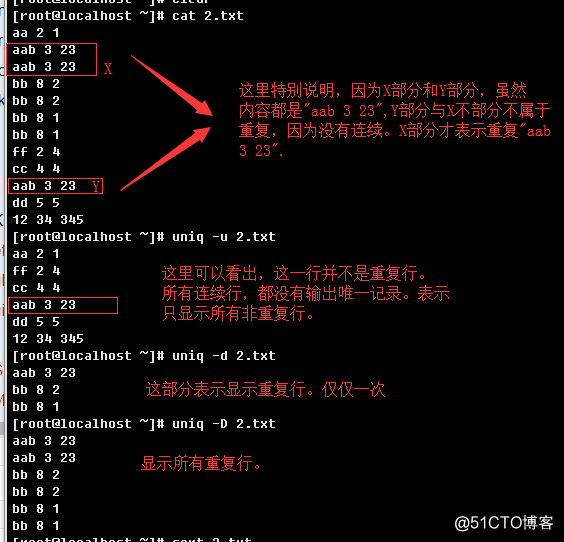
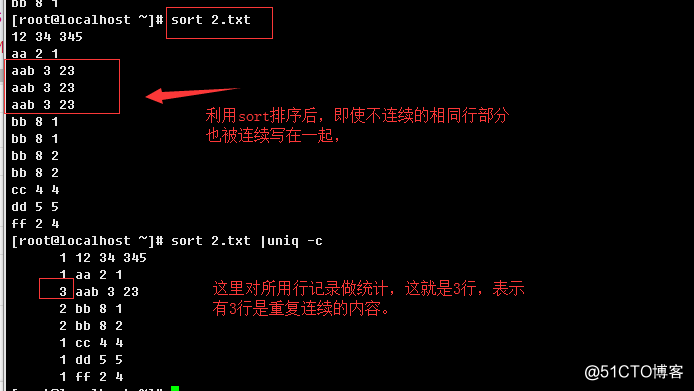
1.2.19、printf
格式化输出文本内容
语法结构:
printf FORMAT [ARGUMENT]...
printf OPTION
引用:http://man.linuxde.net/printf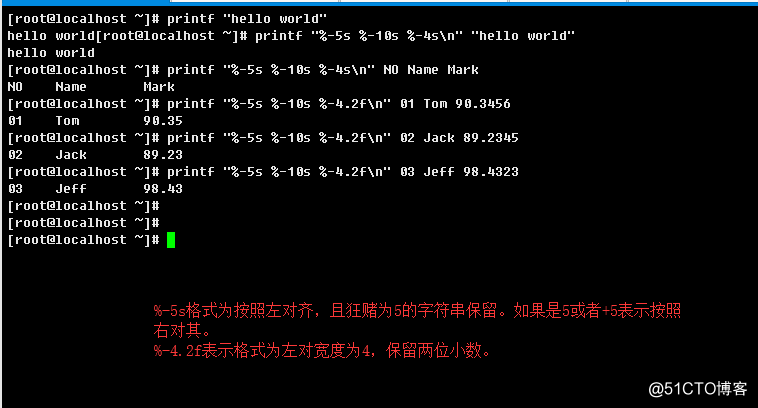
1.2.20、column
格式化输出文本,按照指定字符控制输出多列(有点和awk某些用法类似)
语法结构:
column [options] file...
常用参数:
-t, --table:
-s, --separator separators:指定表输入分隔符,要配合-t一起使用。
可以指定多个分隔符,类似于awk处理一样,按照指定的分隔符切割后,
然后配置-t输出,可以通过-o输出分隔符。
-o, --output-separator separators:指定表输出分隔符举例: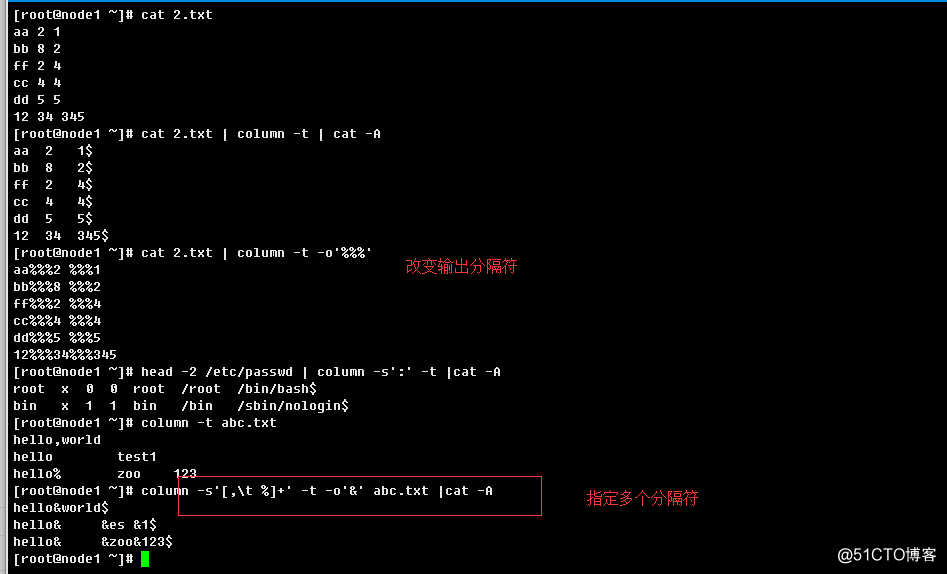
1.2.21、colrm
列删除工具
语法结构:
colrm [first [last]]
colrm工具从指定文件中移除选择的列。其输入来自于标准输入,可以通过管道形式给定文件。
默认输出是标准输出。如果指定参数只有一个,表示从指定列开始到最后一列的内容全部删除,
如果指定参数有两个表示从第一个参数指定的列开始到第二个参数指定的列结束之间的列的内容
全部删除。两个参数都省略,不会删除,默认输出所有文件内容。
举例子: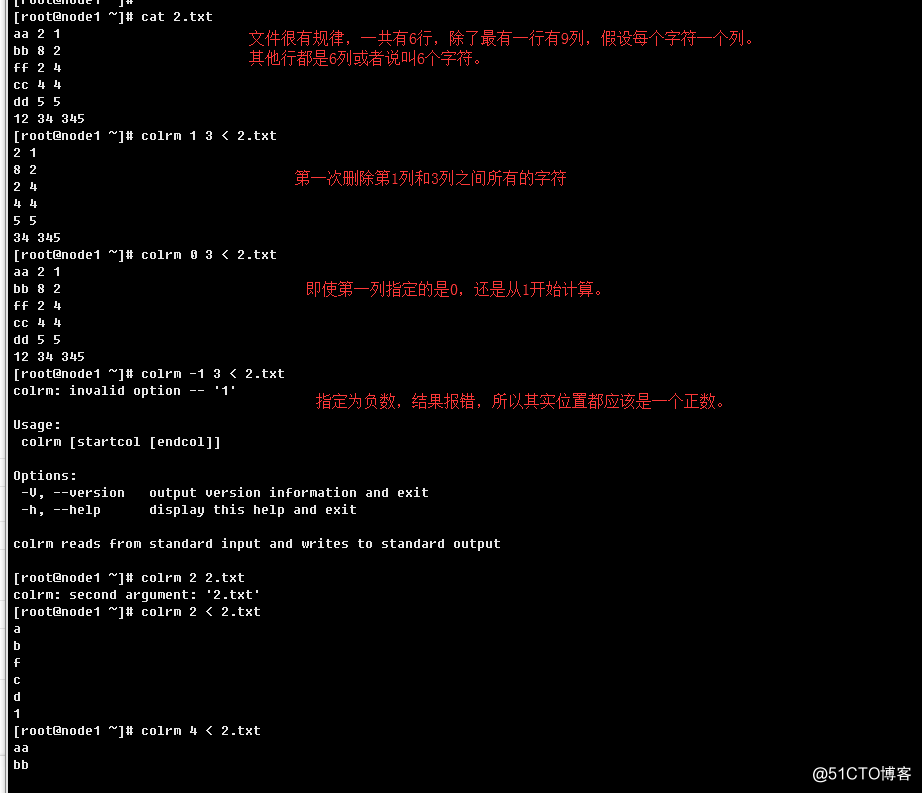
1.2.22、od
以八进制或者其他格式转储文件内容(常用于查看二进制文件)
语法结构:
od [OPTION]... [FILE]...
od [-abcdfilosx]... [FILE] [[+]OFFSET[.][b]]
od --traditional [OPTION]... [FILE] [[+]OFFSET[.][b] [+][LABEL][.][b]]
用的并不是很多,有时候用来分析特殊二进制文件或者特殊格式数据文件(普通文本文件无法参看)。
1.2.23、cp
复制文件或目录(文件)
1.2.24、mv
移动或重命名文件
1.2.25、touch
改变文件时间戳属性(可以创建普通文本文件)
1.2.26、stat
1.2.27、mkdir
创建目录(文件)
1.2.28、rmdir
删除空目录(文件)
1.2.29、rm
删除文件或目录(危险基础指令top10之一)
1.2.30、tr
转换或删除字符
以上这部分的内容,请参见上一部分:(这部分是非常常用的,上次做了总结,这里时间关系,先引用一下)
http://blog.51cto.com/9657273/2171648
1.2.31、mkfifo
建命名管道(有名管道)文件
语法结构:
mkfifo [OPTION]... NAME...
常用选项:
-m, --mode=MODE:
-Z, --context[=CTX]:举例: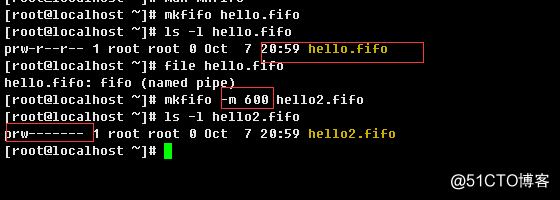
关于有名管道和匿名管道,可以参考:(引用博文)
https://blog.csdn.net/qq_33951180/article/details/68959819
1.2.32、ln 在文件之间做链接关系
语法结构:
ln [OPTION]... [-T] TARGET LINK_NAME (1st form)
ln [OPTION]... TARGET (2nd form)
ln [OPTION]... TARGET... DIRECTORY (3rd form)
ln [OPTION]... -t DIRECTORY TARGET... (4th form)
常用选项:
-f, --force:
-i, --interactive:
-P, --physical:
-s, --symbolic:举例: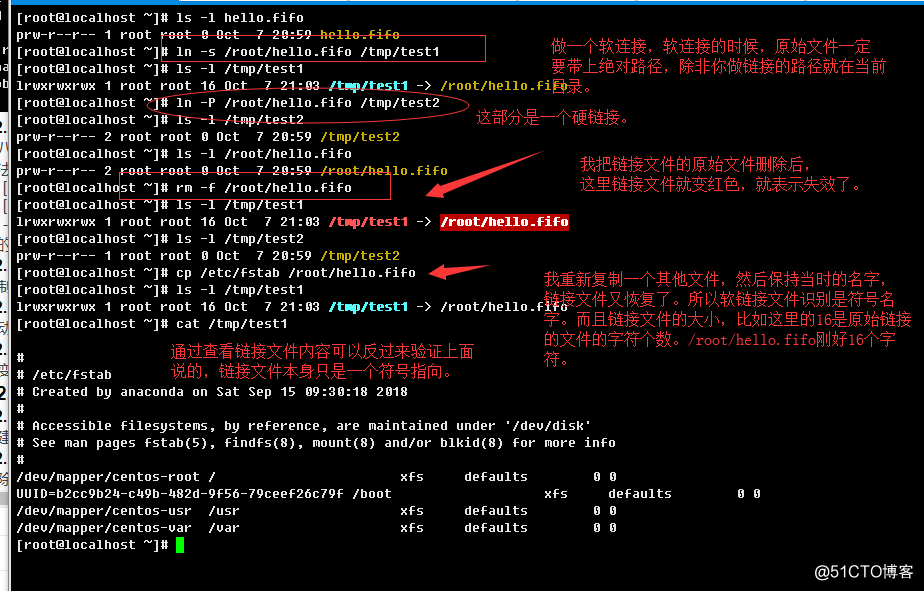
这里只是简单的举例说明了,如果要弄清原理,下次磁盘分区知识哪一块,我会重新说明。
1.2.33、du
评估文件实际空间使用情况
语法结构:
du [OPTION]... [FILE]...
常用选项:
-h, --human-readable:易于读的方式显示大小;
--inodes:统计inode使用情况
-k like --block-size=1K:kb
-s, --summarize:统计
用的最多的也就是一个du -sh file...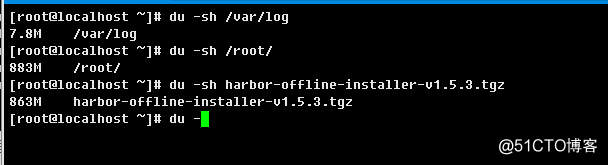
二、bash展开特性
2.1、花括号展开(brace expansion,{})
在{} (大括号,花括号)内,可以是以逗号(,)分隔的字符串,也可以是一个序列的表达式。
大括号前后可以跟前缀和后缀。
1.逗号分隔
[root@zabbix-server ~]# echo a{b,c,d}e
abe ace ade2.序列表达式
'{X..Y[..INCR]}'
X,Y是数字或单个字符,INCR是步长。
当X和Y是数字时,展开为X和Y的所有数字。数字可加前缀0,例如:01,001等
当X和Y以0开头时,shell尝试将生成的结果保持相同的广度,必要的时候会用0填充。
常见形式:{0..10},{a..z},{0..100..2},{a..z..2}等等,请看下面的示例:
[root@zabbix-server ~]# echo {0..10}
0 1 2 3 4 5 6 7 8 9 10
[root@zabbix-server ~]# echo {0..10..2}
0 2 4 6 8 10
[root@zabbix-server ~]# echo {0..10..3}
0 3 6 9
[root@zabbix-server ~]# echo {0..20..5}
0 5 10 15 20
[root@zabbix-server ~]# echo {a..z..3}
a d g j m p s v y2.2、波浪线展开(tilde expansion,~)
~可以表示当前登录用户家目录,及$HOME的值(echo $HOME)
这里还有两种特殊情况,一种是~+,一种是~-。在说这两种特殊情况前,我们先来介绍两个变量,
一个是PWD,一个是OLDPWD。
PWD表示当前所在shell的工作目录;
OLDPWD表示上一次切换目shell的工作目录,我们的cd -做目录来回对切的时候,就引用了这两个环境变量。
当遇到~+的时候,例如~+/lib,就会把~+替换成$PWD,即${PWD}/lib;
当遇到~-的时候,例如~-/lib,就会把~-替换成$OLDPWD,即${OLDPWD}/lib;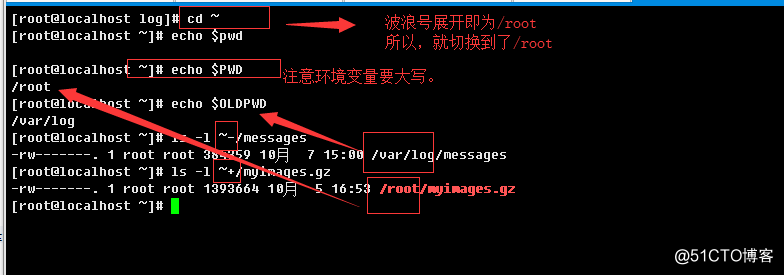
2.3、参数和变量展开(parameter and variable expansion )
参数和变量替换有很多高级用法,我这边就简单引入一些概念,具体详细用法,还是要查看手册。
以符号$引起来的字符串,例如${a},$a,${a_b}等,都表示一个变量;${STRINGS}中间STRINGS部分表示的是
参数,这部分可能会做替换的。常见形式有:
${parameter}
${parameter:-word}
${parameter:=word}
${parameter:?word}
${parameter:+word}
${parameter:offset}
${parameter:offset:length}
${!prefix*}
${!prefix@}
${!name[@]}
${!name[*]}
${#parameter}
${parameter#word}
${parameter##word}
${parameter%word}
${parameter%%word}
${parameter/pattern/string}
${parameter^pattern}
${parameter^^pattern}
${parameter,pattern}
${parameter,,pattern}
2.4、命令替换(command substitution)
命令替换常见的两种形式:
$(命令)命令
示例:
2.5、算数运算展开(arithmetic expansion)
形式:
$((算数表达式))
示例: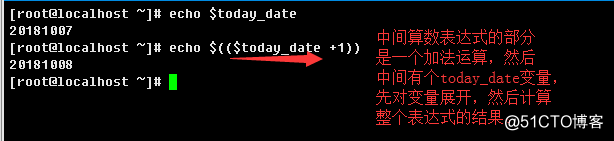
2.6、单词分割(word splitting)
bash手册中翻译的部分:
在单词拆分时,shell会扫描参数扩展、命令替换和算术运算的结果,如果它们不是在双引号之间进行
的。
shell会把$IFS 中的每个字符都当成分隔符,并按照这些字符把其它扩展的结果拆分成单词。如果
$IFS 没有设置,或者它的值和默认的
结尾出现的由
列如果不是出现在头部或尾部就成为单词的分隔符。如果$IFS 的值不是默认的并且含有由空格和制表符这
两个空白符(称为$IFS 分隔符)构成的空白符,则如果在单词的头部或尾部出现就会被删除。$IFS 中除了
空白符以外的任何字符,包括与其毗邻的空白符,就成为字段的分隔符;由$IFS 空白符组成的序列也是分
隔符。如果$IFS 的值为空,则不拆分单词。
明确表示的空参数("" 或'')会被保留下来。由没有设置值的参数扩展后得到的未被引用的隐含空参
数会被删除。如果没有设置值的参数在双引号之间扩展,则结果的空值会被保留。
注意,如果没有进行扩展,则也不会进行单词拆分。
PS:涉及循环流程语句部分,这里不举例不说明。(后面补充)
2.7、路径展开(pathname expansion)
有些bash内建特性以及set值,这里不做说明,我们主要来说说模式匹配。(比如nullglob,nocaseglo等)
bash浏览的时候会把以下几个字符当作特殊字符处理,一般处理,关键字会被作为一个pattern来处理。
特别的pattern字符以及含义如下:
* 匹配任意长度的任意字符,包括空;
? 匹配任意单个字符
[...] 匹配指定范围内的单个字符,以下几种形式:
[a-z],[A-Z],[0-9],[a-z0-9],[a-zA-Z0-9]等等。
[[:upper:]] 表示所有大写字母;
[[:lower:]] 表示所有小写字母;
[[:alpha:]] 表示所有字母;
[[:digit:]] 表示所有数字;
[[:alnum:]] 表示所有字母和数字;
[[:space:]] 表示所有空白字符;
[[:punct:]] 表示所有标点符号;
[^...] 匹配指定范围内的单个字符;
三、特性应用举例
3.1、文件的元数据查看以及修改说明
文件元数据可以通过stat命令来查看:
[root@ACA86E6E ~]# stat anaconda-ks.cfg
File: ‘anaconda-ks.cfg’
Size: 1422 Blocks: 8 IO Block: 4096 regular file
Device: 803h/2051d Inode: 67157059 Links: 1
Access: (0600/-rw-------) Uid: ( 0/ root) Gid: ( 0/ root)
Context: system_u:object_r:admin_home_t:s0
Access: 2018-08-07 21:41:15.525992412 +0800
Modify: 2018-08-07 21:41:15.530992412 +0800
Change: 2018-08-07 21:41:15.530992412 +0800
Birth: -
[root@ACA86E6E ~]# stat -t anaconda-ks.cfg
anaconda-ks.cfg 1422 8 8180 0 0 803 67157059 1 0 0 1533649275 1533649275 1533649275 0 4096 system_u:object_r:admin_home_t:s0
[root@ACA86E6E ~]# stat -f anaconda-ks.cfg
File: "anaconda-ks.cfg"
ID: 80300000000 Namelen: 255 Type: xfs
Block size: 4096 Fundamental block size: 4096
Blocks: Total: 12314752 Free: 12058672 Available: 12058672
Inodes: Total: 24641536 Free: 24615302
选项:
-f,--file-system display file system status instead of file status,显示文件系统的状态信息
-t,--terse print the information in terse form,以精简的格式显示打印的信息
-L, --dereference follow links,表示查看的是符号链接文件的原始文件
-c --format=FORMAT 自定义输出格式,几位有换行
文件输出格式有以下:(以下自定义输出,在我们写脚本的时候非常有用)
%a access rights in octal,八进制访问权限,比如600
%A access rights in human readable form,十位格式权限位,4段(文件类型,属主,属组,其他者)
%b number of blocks allocated (see %B),已经分配的块的数量
%B the size in bytes of each block reported by %b , 以字节为单位输出%b所报告的每个块的大小
%C SELinux security context string,SElinux 安全上下文字符串
%d device number in decimal , 10进制设备编号
%D device number in hex , 16进制设备编号
%f raw mode in hex,16进制原始模式
%F file type,文件类型
%g group ID of owner ,文件所属组的组id
%G group name of owner,文件所属组的组名字
%h number of hard links,文件硬链接的个数
%i inode number,文件的索引编号(inode)
%m mount point,挂载点(有时候识别不了)
%n file name,文件名
%N quoted file name with dereference if symbolic link,如果是符号链接文件,会以符号链接文件指向原始文件,例如:‘test1233’ -> ‘anaconda-ks.cfg’
%o optimal I/O transfer size hint,IO块大小
%s total size, in bytes,文件总字节大小
%t major device type in hex, for character/block device special files,如果是特殊字符或者块设备,显示主设备号,如果不是,显示为0;
%T minor device type in hex, for character/block device special files,如果是特殊字符或者块设备,显示辅设备号,如果不是,显示为0;
%u user ID of owner,文件属主id
%U user name of owner,文件属主名
%w time of file birth, human-readable; - if unknown,文件创建时间,若未知则显示"-",CentOS 7添加的,CentOS 6系列没有这个属性
%W time of file birth, seconds since Epoch; 0 if unknown,从UNIX 元年起以秒计的文件创建时间,若未知则显示"0"
%x time of last access, human-readable,文件上一次的访问时间
%X time of last access, seconds since Epoch,从UNIX 元年起以秒计的上次访问时间
%y time of last modification, human-readable,文件上一次的修改时间
%Y time of last modification, seconds since Epoch,从UNIX 元年起以秒计的上次修改时间
%z time of last change, human-readable,文件上一次的改变时间
%Z time of last change, seconds since Epoch, 从UNIX 元年起以秒计的上次改变时间
有效的文件系统输出格式:(以下自定义输出,在我们写脚本的时候非常有用)
%a free blocks available to non-superuser,非管理员用户剩余可用的块数量;
%b total data blocks in file system,文件系统总数据块数量;
%c total file nodes in file system,文件系统总节点数量;
%d free file nodes in file system,文件系统空闲节点数量;
%f free blocks in file system,文件系统空闲的块数量;
%i file system ID in hex,十六进制文件系统ID;
%l maximum length of filenames,允许文件名的最大长度;
%n file name,文件名
%s block size (for faster transfers),用于传输的传输的块大小
%S fundamental block size (for block counts),用于块计数的基本块大小;
%t file system type in hex,以16进制描述文件系统类型;
%T file system type in human readable form,以名字(很好理解的方式)描述文件系统类型,例如xfs,ext2/ext3等
正常的文件查看信息说明:
File:表示stat查看的文件名;
Size:表示stat查看的文件的大小;
Blocks:表示已经分配的块的数量,如果每个块512字节,那么一共4096字节;
IO Block:IO块大小;
regular file:表示查看的文件为常规文件
Device:16进制设备号/10进制设备号
Inode:stat查看的文件的inode编号;
Links:stat查看的文件的硬链接数;
Access:八进制权限/字符权限位(10位)
Uid:文件属主id编号/ 文件属主名
Gid:文件属组id编号/ 文件属组名
Context:SElinux 安全属性
Access:文件最近一次的访问时间(年-月 -日 时:分:秒.毫秒 时区)
Modify:文件最近一次的修改时间(年-月 -日 时:分:秒.毫秒 时区)
Change:文件最近一次的改变时间(年-月 -日 时:分:秒.毫秒 时区)
Birth:文件的创建时间,为"-"表示不识别;
正常的文件系统查看信息说明:
File:stat查看的文件名;
ID:十六进制文件系统ID;
Namelen:文件系统允许最大的文件名长度;
Type:文件系统类型;
Block size:用于传输的块大小;
Fundamental block size:基本块大小(用于块计算的)
Blocks:文件系统块统计信息,下面是说明
Total:文件系统总数据块数量;
Free:文件系统空余的块数量;
Available:文件系统非管理员用户可用的块数量;
Inodes:文件系统的索引编号信息,下面是说明
Total:文件系统总索引编号数量;
Free:文件系统空余索引编号数量;不是所有的元数据都可以修改,我们举一个参见的touch,可以用来修该部分元数据信息。
touch:
语法结构:
touch [OPTION]... FILE...
选项:
-a change only the access time,只改变时间戳的访问时间;
-c, --no-create ,不创建文件;
-d, --date=STRING:使用STRING指定的时间,而不是当前系统时间;
-m change only the modification time,只改变时间戳的修改时间;
-t STAMP
use [[CC]YY]MMDDhhmm[.ss] instead of current time,使用指定格式时间,而不是当前系统时间。
--time=WORD
WORD可以为access或atime表示修改访问时间属性,可以为modify或mtime表示修改 修改时间属性;
示例:
a.>根据系统时间创建一个新的文件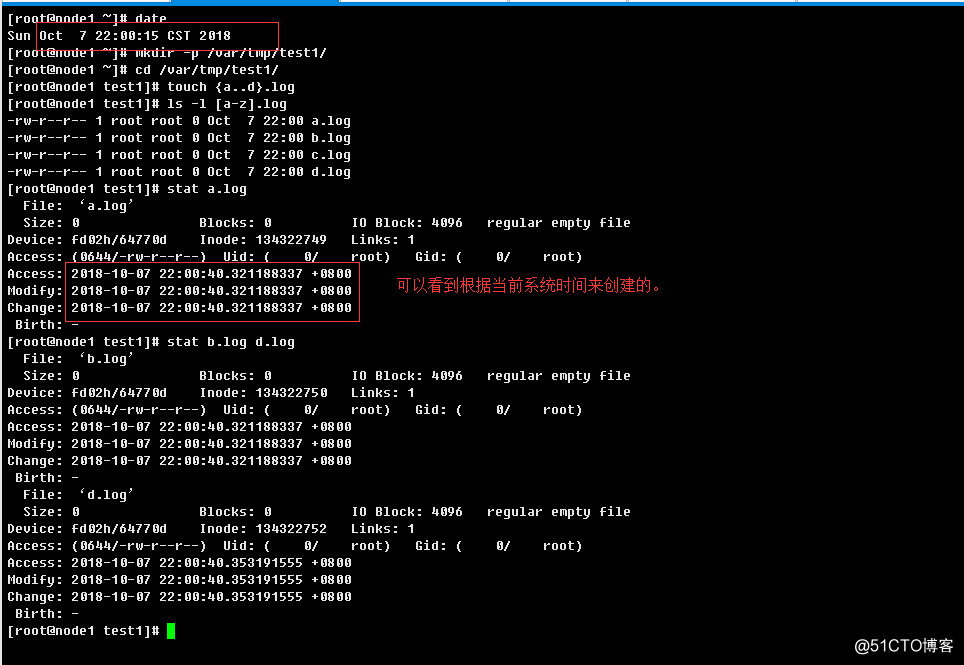
b.> 根据指定时间创建一个新的文件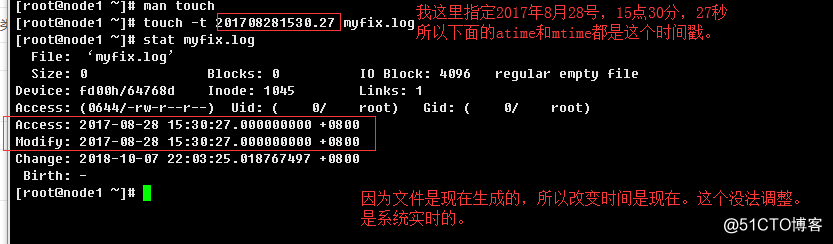
c.> 修改文件访问时间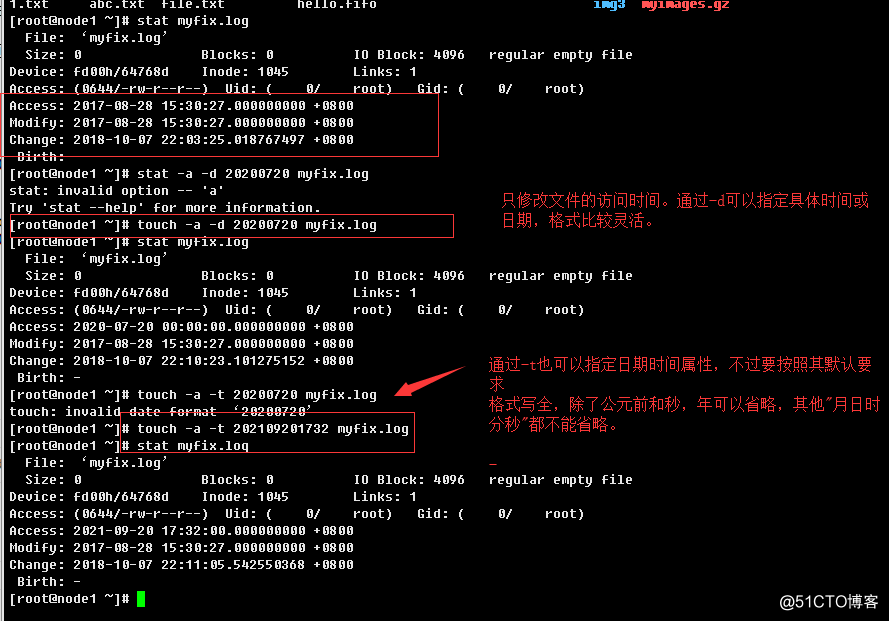
d.> 修改文件 修改时间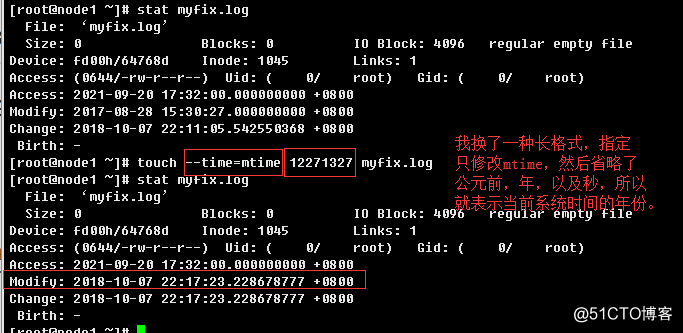
3.3、bash 模式匹配特性以及应用
练习1:利用展开,来创建目录
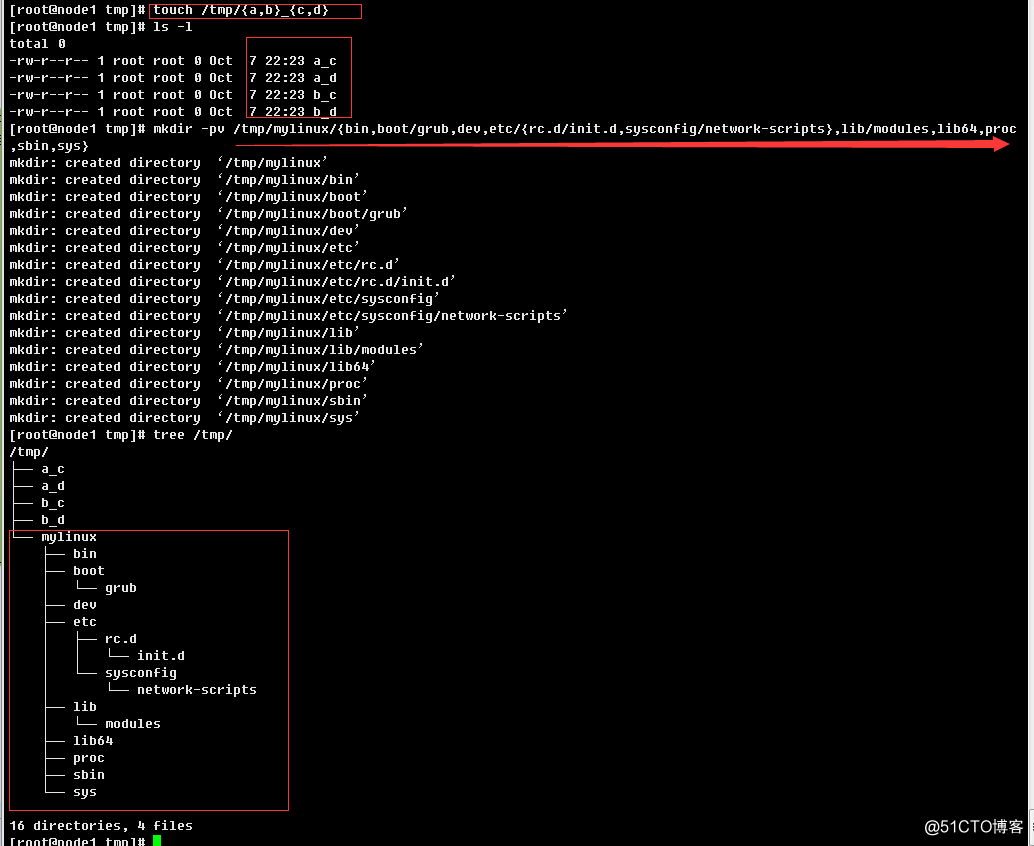
练习2:显示/var目录下所有以l开头,以一个小写字母结尾,且中间至少出现一位数字(可以有其他字符)的文件或目录
ls /var/l*[0-9]*[[:lower:]]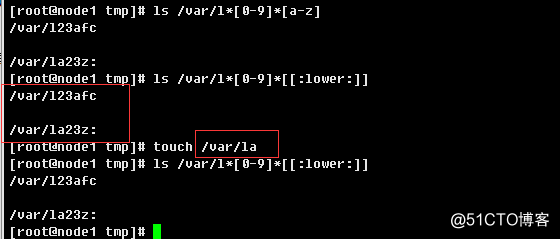
练习3:显示/etc目录下,以任意一个数字开头,且以非数字结尾的文件或目录
ls -d /etc/[0-9]*[^0-9]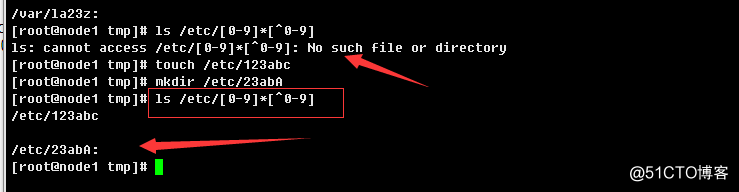
练习4:显示/etc目录下,以非字母开头,后面跟一个字母以及其他任意长度任意字符的文件或目录
ls /etc/[^a-zA-Z][[:alpha:]]* 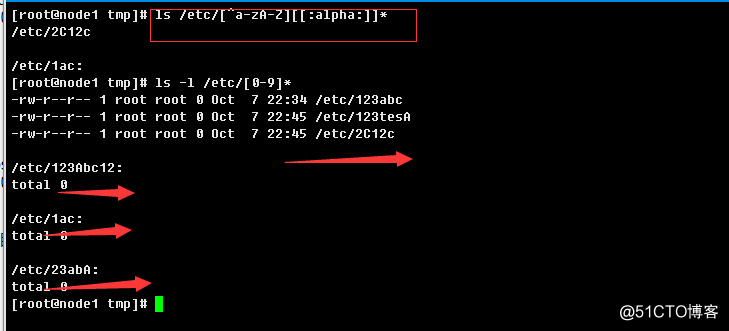
练习5:在/tmp目录下创建以tfile开头,后面跟当前日期和时间的文件,文件名形如:tfile-2016-05-27-09-32-22
touch /tmp/tfile-$(date +%Y-%m-%d-%H-%M-%S)
练习6:复制/etc目录下所有以p开头,以非数字结尾的文件或目录到/tmp/mytest1目录中
cp -r /etc/p*[^0-9] /tmp/mytest1/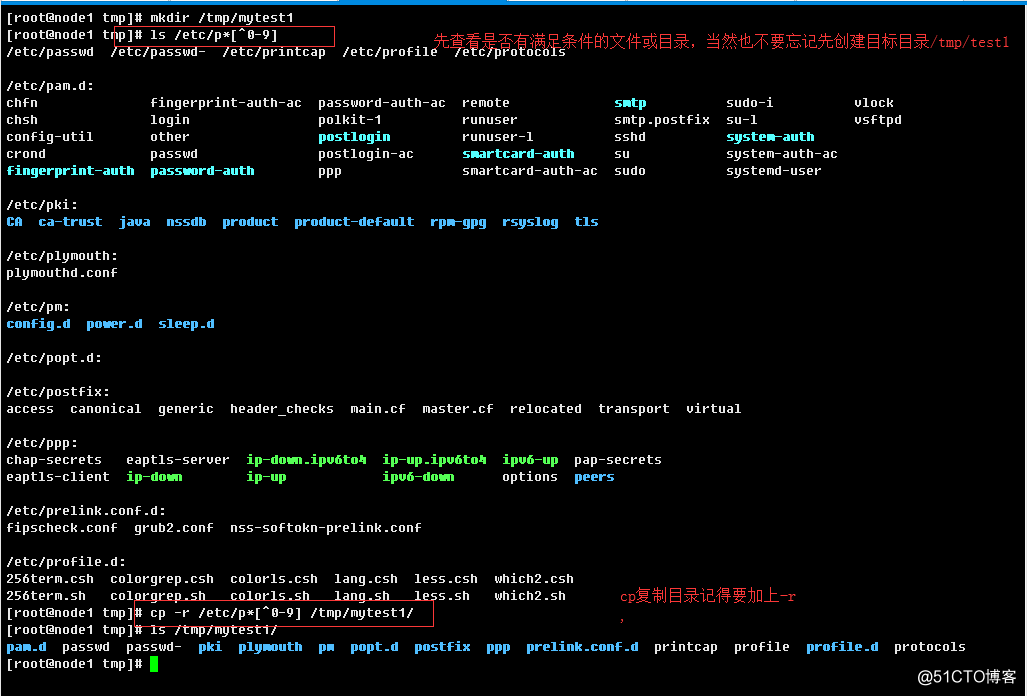
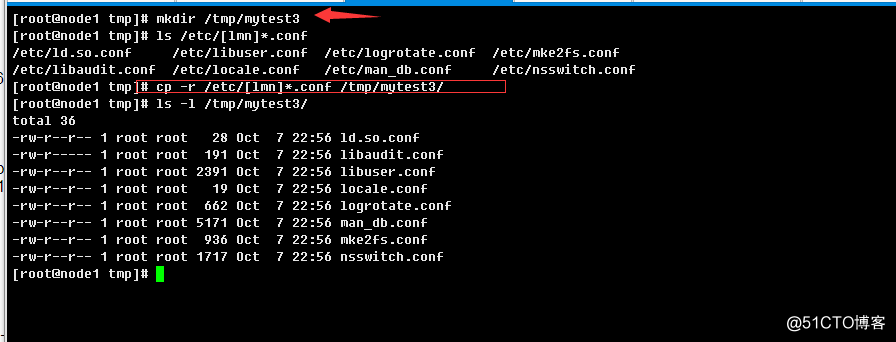
练习7:复制/etc目录下所有以l或m或n开头,以.conf结尾的文件至/tmp/mytest3目录中
cp -r /etc/[lmn]*.conf /tmp/mytest3/