java面试——2021校招提前批次招商网络科技视频二面问题
1 你的什么专业?在你的专业方向做了什么工作?,主要是在研究生做了哪些工作?做了哪些课题?
2 大数据的相关组件你了解吗?
hadoop 的原理 Flume的原理 ……一些大数据相关的组件的原理。
3 sleep()和wait的区别?
这两个方法来自不同的类分别是Thread和Object 。
最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法(锁代码块和方法锁)。
wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用(使用范围) 。
sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常 。
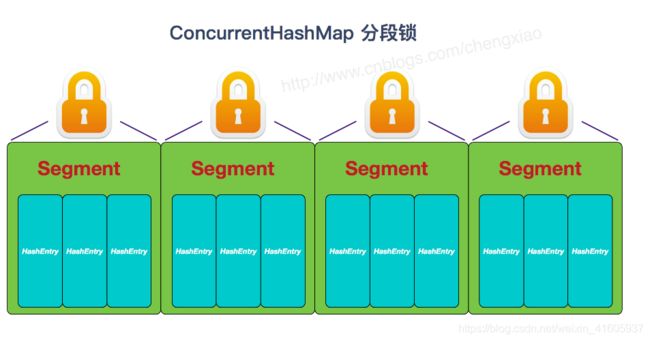
4 Currenthashmap的的原理和底层实现
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。整个 ConcurrentHashMap 由一个个 Segment 组成, Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了“槽”来代表一个segment。ConcurrentHashMap 是一个Segment数组Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。JDk1.7的时候
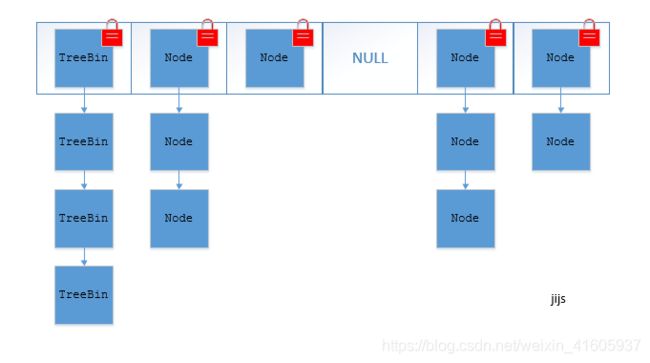
JDK1.8在JDK1.8中,放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
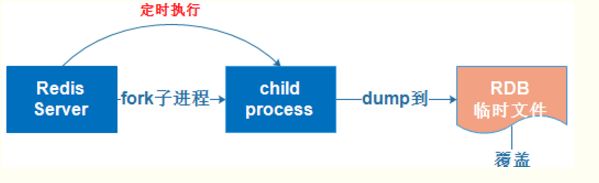
5 Redis的持久化操作和原理以及实现操作
redis提供两种方式进行持久化,一种是RDB持久化(原理是将Reids在内存中的数据库记录定时 dump到磁盘上的RDB持久化),另外一种是AOF(append only file)持久化(原理是将Reids的操作日志以追加的方式写入文件)
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。

|
|
AOF |
RDB |
| 优点 |
1AOF 可以更好的保护数据不丢失,一般 AOF 会每隔 1 秒,通过一个后台线程执行一次fsync操作,最多丢失 1 秒钟的数据 2AOF 日志文件以 append-only 模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。 3AOF 日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写. 4AOF 日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。 |
1RDB 会生成多个数据文件,每个数据文件都代表了某一个时刻中 redis 的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去 2RDB 对 redis 对外提供的读写服务,影响非常小,可以让 redis 保持高性能 3相对于 AOF 持久化机制来说,直接基于 RDB 数据文件来重启和恢复 redis 进程,更加快速。 |
| 缺点 |
1对于同一份数据来说,AOF 日志文件通常比 RDB 数据快照文件更大 2AOF 开启后,支持的写 QPS 会比 RDB 支持的写 QPS 低AOF 这种较为复杂的基于命令日志 / merge / 回放的方式,比基于 RDB 每次持久化一份完整的数据快照文件的方式 |
1如果想要在 redis 故障时,尽可能少的丢失数据,那么 RDB 没有 AOF 好 2RDB 每次在 fork 子进程来执行 RDB 快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。 |
6 对并发和并行的理解?
并发(concurrency)
指宏观上看起来两个程序在同时运行,比如说在单核cpu上的多任务。但是从微观上看两个程序的指令是交织着运行的,你的指令之间穿插着我的指令,我的指令之间穿插着你的,在单个周期内只运行了一个指令。这种并发并不能提高计算机的性能,只能提高效率
并行(parallelism)
指严格物理意义上的同时运行,比如多核cpu,两个程序分别运行在两个核上,两者之间互不影响,单个周期内每个程序都运行了自己的指令,也就是运行了两条指令。这样说来并行的确提高了计算机的效率。所以现在的cpu都是往多核方面发展。
简单理解
并发:一个处理器可以同时处理多个任务。这是逻辑上的同时发生。
并行:多个处理器同时处理多个不同的任务。这是物理上的同时发生。
7 数据库的表的相关的连接操作?
内连接:两个表格的的交集
外连接:两个表格数据的并集
左连接:左边表格的全部数据的连接右边的相匹配的数据
右连接:右边表格的全部数据的连接左边的相匹配的数据
8 Union 和union All的相关的区别?
UNION 并集,表中的所有数据,并且去除重复数据(工作中主要用到的是这个);
UNION ALL,表中的数据都罗列出来;
9 java里面cylicbarrier和countdownlunch,区别?是如何使用的?实现代码?
DK 的并发包中提供了几个非常有用的并发控制工具类。CountDownLatch\CyclicBarrier 和Semaphore 提供了一种并发流程控制的手段,Exchanger 工具类提供了线程间交换数据的一种手段。
1.CountDownLatch:CountDownLatch 允许一个或多个线程等待其他线程完成操作。
CountDownLatch 是通过“共享锁” 实现的。 在创建 CountDownLatch 时,会传递一个 int 类型参数, 该参数是“锁计数器” 的初始状态, 表示该“共享锁”最 多 能 被 count 个 线 程 同 时 获 取 , 这 个 值 只 能 被 设 置 一 次 , 而 且CountDownLatch 没有提供任何机制去重新设置这个计数值。 主线程必须在启动其他线程后立即调用 await()方法。 这样主线程的操作就会在这个方法上阻塞, 直到其他线程完成各自的任务。 当某线程调用该 CountDownLatch 对象的await()方法时, 该线程会等待“共享锁” 可用时, 才能获取“共享锁” 进而继续运行。 而“共享锁” 可用的条件, 就是“锁计数器” 的值为 0! 而“锁计数器”的初始值为 count, 每当一个线程调用该 CountDownLatch 对象的 countDown()方法时, 才将“锁计数器” -1; 通过这种方式, 必须有 count 个线程调用countDown()之后, “锁计数器” 才为 0, 而前面提到的等待线程才能继续运行!
场景:解析一个Excel里的多个sheet数据,使用多个线程,每个线程解析一个sheet,等到所有线程解析完,主线程完成解析
解决方案一:
在主线程中调用启动每一个线程,然后调用个线程的.join()方法。
解析:join()用于让当前线程等待join线程执行结束,就是不停检查join线程是否存活,如果存活则让当前线程永远等待。直到join线程执行结束后 this.notifyAll().
public class Test {
public static void main(String[] args) {
final CountDownLatch latch = new CountDownLatch(2);
new Thread(){
public void run() {
try {
System.out.println("子线程"+Thread.currentThread().getName()+"正在执行");
Thread.sleep(3000);
System.out.println("子线程"+Thread.currentThread().getName()+"执行完毕");
latch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
};
}.start();
new Thread(){
public void run() {
try {
System.out.println("子线程"+Thread.currentThread().getName()+"正在执行");
Thread.sleep(3000);
System.out.println("子线程"+Thread.currentThread().getName()+"执行完毕");
latch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
};
}.start();
try {
System.out.println("等待2个子线程执行完毕...");
latch.await();
System.out.println("2个子线程已经执行完毕");
System.out.println("继续执行主线程");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}CountDownLatch 的构造函数接受一个int类型的参数作为计数器,如果想等待N个线程完成,这里传入N。
public void countDown() { }; //将count值减1
public void await() throws InterruptedException { }; //调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行
同步屏障 CyclicBarrier
让一组线程达到一个同步点时被阻塞,知道最后一个线程达到同步点时候,屏障才会开们,所有被拦截的线程才会继续执行。await()函数每被调用一次,计数便会减少 1(CyclicBarrier 设置了初始值),并阻塞住当前线程。 当计数减至 0 时, 阻塞解除, 所有在此 CyclicBarrier 上面阻塞的线程开始运行。
场景:假若有若干个线程都要进行写数据操作,并且只有所有线程都完成写数据操作之后,这些线程才能继续做后面的事情。
public class Test {
public static void main(String[] args) {
int N = 4;
CyclicBarrier barrier = new CyclicBarrier(N);
for(int i=0;i解析:当调用await()方法之后,线程就处于barrier了,知道所有线程达到同步点以后可以继续处理别的事情。
3.CountDownLatch 和 CyclicBarrier 的区别
(1) CountDownLatch 的作用是允许 1 个线程等待其他线程执行完成之后,它才执行; 而 CyclicBarrier 则是允许 N 个线程相互等待到某个公共屏障点, 然后这一组线程再同时执行。
(2) CountDownLatch 的计数器的值无法被重置, 这个初始值只能被设置一次, 是不能够重用的; CyclicBarrier 是可以重用的。
Semaphore
可以控制某个资源可被同时访问的个数, 通过构造函数设定一定数量的许可, 通过 acquire() 获取一个许可, 如果没有就等待, 而 release() 释放一个许可。
场景:要读取几万个文件的数据,可以启动几十个线程并发读取,同时需要连接数据库完成存储,而数据库连接数只有是个,这时候我们只有控制十个线程获取数据库的链接保存数据,否则报错无法获取链接。
public class SemaphoreTest{
private static final int THREAD_COUNT = 30;
private static ExecutorServicethreadPool = Executors.new FixedThreadPool(THREAD_COUNT);
private static Semaphore s =new Semaphore(10);
public static void main(String[] args){
for(int i=0;i虽然有三十个线程在执行,但是只允许10个并发执行。acquire()获取一个许可证,release()方法归还一个许可证。
10 利用java来实现的阻塞队列的代码
public class MyBlockQueue {
//push锁
private final static Object pushLock = new Object();
//pop锁
private final static Object popLock = new Object();
//数据存储
private Stack stack;
//队列最大长度
private int maxSize = 0;
//队列最小长度
private int minSize = 0;
public MyBlockQueue(int size) {
this.maxSize = size;
stack = new Stack();
}
public synchronized void push(T t) {
if(stack.size() >= maxSize) {
pushLock();
}
stack.push(t);
popUnLock();
}
public synchronized T pop() {
if(stack.size() == minSize) {
popLock();
}
T t = stack.pop();
pushUnLock();
return t;
}
private void pushLock() {
synchronized (pushLock) {
try {
pushLock.wait();
} catch (Exception e) {
e.printStackTrace();
}
}
}
private void pushUnLock() {
synchronized (pushLock) {
pushLock.notify();
}
}
private void popLock() {
synchronized (popLock) {
try {
popLock.wait();
} catch (Exception e) {
e.printStackTrace();
}
}
}
private void popUnLock() {
synchronized (popLock) {
popLock.notify();
}
}
} 11实现二叉树的翻转的实现
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode invertTree(TreeNode root) {
//递归终止的条件
if(root==null){
return null;
}
//递归的过程是
invertTree(root.left);
invertTree(root.right);
//翻转实现
TreeNode temp=root.right;
root.right=root.left;
root.left=temp;
return root;
}
}12 并发的相关的问题的原理?
……
13 java 中的IO 和NIO 和AIO的原理和区别?
简答
- BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
- NIO:Non IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
- AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
详细回答
- **BIO (Blocking I/O): **同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
- **NIO (New I/O): **NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发
- **AIO (Asynchronous I/O): **AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
14 拦截器 过滤器的原理 有什么区别?怎么配置?
过滤器是基于函数的回调的实现的可以所有的请求进行拦截,过滤器的实例化是能在容器初始化的时候执行 通常用于是的修改字符编码的,过滤请求中的敏感字符。在web.xml文件中配置
拦截器是基于的web框架的 原理是基于的java的反射的原理,是在一个方法的调用前后执行另外的一个方法。拦截器只能对controller请求进行拦截 jsp是不拦截的 在springmvc的配置文件中
监听器 实现了javax.servlet.ServletContextListener 接口的服务器端程序,它也是随web应用的启动而启动,只初始化一次,随web应用的停止而销毁。主要作用是:感知到包括request(请求域),session(会话域)和applicaiton(应用程序)的初始化和属性的变化;
15 反问环节:
我问他对我的面试评价,他是叫我猜。然后笑笑说,这个东西我不做评价了。后面的结果会通知到你的。那个时候就知道你的评价了。
面试总结:
1java的基础中的那几个关键字和一些词语的区别和理解
类 多态 抽象类 接口 并发问题的关键字的理解和原理…………
2并发编程的中的原理和简单实现
3 手写代码一般都是leetcode的简单的一定要手写一次成功。不能在IDEA中的写,难度是简单的就行。