Python绘图总结(Matplotlib篇)
Matplotlib绘图知识点集锦
- 1.1基础知识篇
- 绘图背景网格设置
- 坐标轴颜色、标题大小的设置
- ax.tick_params(axis='both',labelcolor='r', labelsize='medium', width=3)
- X,Y轴标签名称、字体颜色、样式的设置
- 画图中图名、图例、轴标签、轴边界、轴刻度的设置
- matplotlib相关设置
- Seaborn 相关设置
- matplotlib下手动修改横坐标和纵坐标上的刻度(ticks)
- matplotlib画图,x轴标签旋转
- python画heatmap图,x轴标签旋转
- 按某一列聚合再排序,然后画条形图
- Matplotlib中指定图片大小和像素
- 绘制直方图(hist)
- 用Python为直方图绘制拟合曲线的两种方法
- python详解pandas.DataFrame.plot( )画图函数
- brewer2mpl的用法
- seaborn画核密度图
- 从np.random.normal()到正态分布的拟合
- matplot设置xy轴范围
- 相关性分析
官方教程:https://matplotlib.org/gallery/index.html
大鹏教程:https://www.kesci.com/home/project/5cf7a5a8e727f8002c1925c8
fig, axes = plt.subplots(23):即表示一次性在figure上创建成2*3的网格,使用plt.subplot()只能一个一个的添加.
官方帮助文档:https://matplotlib.org/api/_as_gen/matplotlib.pyplot.subplots.html
python使用matplotlib:subplot绘制多个子图https://blog.csdn.net/gatieme/article/details/61416645
1.1基础知识篇
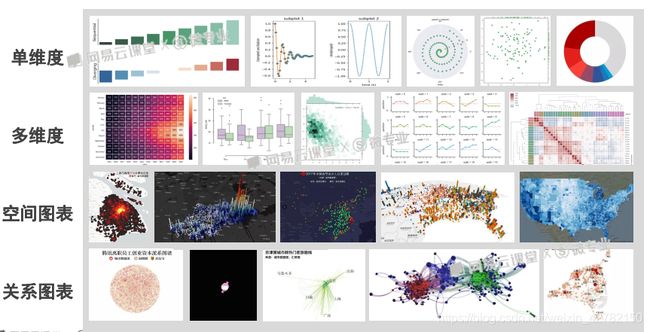
Python常见的可视化图表分类如下:

(1) 用于比较的图标类型:“基于类别”、“基于时间”;
基于类别:
不等宽的柱形图(两个变量:高度/宽度)
矩阵图表、条形图、柱状图(一个变量:高度)
基于时间:
雷达图、折线图、柱状图(多周期/少周期)
(2) 用于分布的图表类型:“单个变量”、“多个变量”
单个变量:
直方图、密度图、箱型图
多个变量:
散点图、多维密度图
(3) 用于构成的图表类型:“静态”、“基于时间”
静态:
饼图、瀑布图、堆积图
基于时间:
堆积图、面积图(相对差异/绝对差异)
(4) 用于关系的图表类型:“2个变量”,“多个变量”
2个变量:散点图
多个变量:气泡图
主类 次类 用途
折线图 折线图 用于反映和时间相关的数据变化(趋势)
面积图 用于反映主次之间的基于时间的对比
柱状图 柱状图 分类项目的数量比较,也可能反映趋势
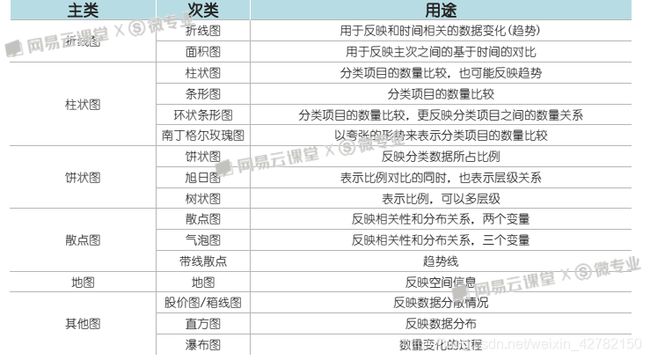 分类项目的数量比较
分类项目的数量比较
1.2代码篇
1.2.1 Matplotlib模块的导入和基本配置:
import matplotlib.pyplot as plt #导入matplotlib模块
from matplotlib.font_manager import * #解决中文显示问题
%matplotlib notebook #使用该魔法,不用写plt.show(),以及可以边写边运行
plt.rcParams['font.sans-serif']=['SimHei'] #用于正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用于正常显示负号
1.2.2 基本绘图命令:
常见的python绘图包括画布的设置、标题、颜色及样式
#一般字体统一用一个字典来控制
font={‘family’:‘Times New Roman’,
‘style’:‘italic’,
‘weight’:‘normal’,
‘size’: 30,
‘color’:‘White’
}
1.2.2.1绘制柱状图
ax=df.plot(kind=‘bar’) #绘制柱状图
图表格式的设置
绘图背景网格设置
ax.grid(True, linestyle=’-.’)
坐标轴颜色、标题大小的设置
ax.tick_params(axis=‘both’,labelcolor=‘r’, labelsize=‘medium’, width=3)
ax.tick_params(axis=‘x’,labelcolor=‘gold’, labelsize=‘medium’, width=3)
ax.tick_params(axis=‘y’,labelcolor=‘r’, labelsize=‘medium’, width=2)
X,Y轴标签名称、字体颜色、样式的设置
plt.xlabel(‘Items’,font)
plt.ylabel(‘Price’,font)
plt.title(‘Most ordered Chipotle’s Items’,font)
#show the plot
plt.show()
画图中图名、图例、轴标签、轴边界、轴刻度的设置
matplotlib相关设置
df = pd.DataFrame(np.random.rand(10,2), columns = ['A','B'])
fig = df.plot(figsize = (10,6)) #创建图表对象,并复制给fig
plt.figure(figsize=(8, 4)) # 创建了一个绘图对象,图片尺寸长8英寸,宽4英寸,dpi可以指定每英寸多少像素,默认80.
plt.title('标题',fontproperties=myfont)
plt.xlabel('x轴坐标',fontproperties=myfont)
plt.ylabel('y轴坐标',fontproperties=myfont)
plt.legend(loc = 'upper right') #设置图例放置的位置(upper right:右上角,upper left:左上角,lower left:左下角,lower right:右下角,此外还包括:right、center left、center right、lower center、upper center、center)
plt.xlim([0,12]) # x轴边界
plt.ylim([0,1.5]) # y轴边界
plt.xticks(range(12)) # 设置x刻度
plt.yticks([0,0.2,0.4,0.6,0.8,1.0,1.2]) # 设置y刻度
fig.set_xticklabels("%.1f" %i for i in range(12)) # x轴刻度标签
fig.set_yticklabels("%.1f" %i for i in [0,0.2,0.4,0.6,0.8,1.0,1.2]) # y轴刻度标签
plt.grid(True,linestyle = "--",color = 'gray' ,linewidth = '0.5',axis='both') # 显示网格(linestyle : 线型,color:颜色,linewidth :线宽,axis = x,y,both,显示x/y/两者的格网)
plt.tick_params(bottom = 'on',top = 'off',left = 'on',right = 'off') # 刻度显示(刻度分为上下左右四个地方,on为显示刻度,off不显示刻度)
plt.axis('off') #关闭坐标轴
plt.savefig(name) 和 plt.show() # 保存、显示创建的所有绘图对象
Seaborn 相关设置
ax.set_xlabel("产品分类")
matplotlib下手动修改横坐标和纵坐标上的刻度(ticks)
在用matplotlib画二维图像时,如果默认的X轴、Y轴显示的刻度值达不到自己的需求,需要借助xticks()和yticks()分别对横坐标x-axis和纵坐标y-axis进行设置。
xticks()中有3个参数:
语法格式:
xticks(locs, [labels], **kwargs) # Set locations and labels
参数说明:
locs参数——数组参数(array_like, optional),表示x-axis的刻度线显示标注的地方,即ticks放置的地方,上述例子中,如果希望显示1到12所有的整数,就可以将locs参数设置为range(1,13,1);
[labels]参数——也是数组参数(array_like, optional),可以不添加该参数,表示在locs数组表示的位置添加的标签,labels不赋值,在这些位置添加的数值即为locs数组中的数。
应用实例:
plt.xticks(range(0,400,15),fontsize=20,rotation=45) # X轴范围0-400,刻度间隔为15,标签旋转45°
plt.xticks(np.linspace(-10,400,20),fontsize=15) # X轴范围-10-400,显示20项刻度,标签字体大小为15

参考链接:
https://blog.csdn.net/Poul_henry/article/details/82590392
https://www.cnblogs.com/xiaoliyustyle/p/9588715.html
matplotlib画图,x轴标签旋转
matplotlib画条形图的时候,x坐标轴标签默认是垂直的。
调整x轴标签,从垂直变成水平或者任何你想要的角度,只需要改变rotation的数值。
for tick in ax1.get_xticklabels():
tick.set_rotation(360)
或者
import pylab as pl
pl.xticks(rotation=360)
或者
通过调用plt.setp函数配置多个Line2D对象的颜色和属性。
cp_nj=sf_df_fahuo[['产品分类','年龄分级','订单编号']].groupby(['产品分类','年龄分级'],as_index=False).count()
f,ax=plt.subplots(1,1,figsize=(30,15)) #设置图幅的大小和数量
# for label in ax.xaxis.get_ticklabels(): #此种方法旋转后标签与刻度对不齐
# label.set_rotation(45)
# label.set_fontsize(30)
# ax.grid(True,linestyle='-')
sns.barplot(x='产品分类', y='订单编号', hue="年龄分级",data=cp_nj,ci=0) #绘制条形图
plt.legend(loc = 'upper right') #设置图例放置的位置为右上角
plt.setp(ax.get_xticklabels(), rotation=45, ha="right",
rotation_mode="anchor") # 旋转刻度标签并设置其对齐方式。
#或者
plt.setp([tick.label1 for tick in ax.xaxis.get_major_ticks()], rotation=45,
ha="right", va="center", rotation_mode="anchor") # 旋转刻度标签并设置其对齐方式
#ha有三个选择:right,center,left,va有四个选择:'top', 'bottom', 'center', 'baseline',ha有三个选择:right,center,left,va有四个选择:'top', 'bottom', 'center', 'baseline'
# tick.label1 表示第一个图的label设置,若改为tick.label2则会报错。
# [x.get_text() for x in axis.get_ticklabels()]# 获得主刻度的文本字符串
# axis刻度包括主刻度和副刻度,分别通过get_major_ticks()和get_minor_ticks()方法获得。每个刻度线都是一 个XTick或YTick对象,它包括实际的刻度线和刻度标签。
plt.setp函数的用法:通过调用plt.setp函数配置多个Line2D对象的颜色和属性。
语法:matplotlib.pyplot.setp(obj, *args, **kwargs)[source]
实用典例:
plt.setp(ax.get_xticklabels(), rotation=45) #X轴坐标旋转45°,标签与刻度不对齐
plt.setp([tick.label1 for tick in ax.xaxis.get_major_ticks()], rotation=45, ha="right", va="center", rotation_mode="anchor") #X轴坐标旋转45°,标签与刻度对齐
实例:
# 例1
import matplotlib.pyplot as plt
line,=plt.plot([1,2,3]) #
plt.setp(line,linestyle='--') # 设置线型为“虚线”
# plt.setp(line,"linestyle") #如果要了解有效的参数类型,可以提供要设置的属性的名称而不使用值:
>>>
linestyle: {'-', '--', '-.', ':', '', (offset, on-off-seq), ...}

setp()在单个实例或可迭代的实例上运行。 如果您处于查询模式内省可能的值,则仅使用序列中的第一个实例。 实际设置值时,将设置所有实例。 例如,假设您有两行的列表,以下将使两行变粗和变红:
# 例2
import matplotlib.pyplot as plt
import numpy as np
x=np.arange(0,1.0,0.01)
y1=np.sin(2*np.pi*x)
y2=np.sin(4*np.pi*x)
lines=plt.plot(x,y1,x,y2)
plt.setp(lines,linewidth=2,color='r') # setp函数,设置线型粗细和颜色

Matplotlib画图的参考链接:
https://blog.csdn.net/pipisorry/article/details/37742423
https://www.douban.com/note/567787081/
https://matplotlib.org/api/_as_gen/matplotlib.pyplot.setp.html
python画heatmap图,x轴标签旋转
利用matplo或seaborn绘制热力图 correlation heatmap X,Y 坐标轴字体重叠显示问题,将字体进行旋转,此时可以使用plt.xticks(rotation=45)进行X轴标签的旋转。
Correlation=sf_df_last[['激活与否','性别','年龄分级','号码归属省','产品分类','交易周期']]
colormap = plt.cm.viridis
plt.figure(figsize=(20,20))
plt.title('Pearson Correlation of Features', y=1.05, size=20)
sns.heatmap(Correlation.astype(float).corr(),linewidths=0.1,vmax=1.0,
square=True, cmap=colormap, linecolor='white', annot=True)
plt.xticks(rotation=45) # 将字体进行旋转(seaborn和matplotlib模式下X轴旋转的方式不同)
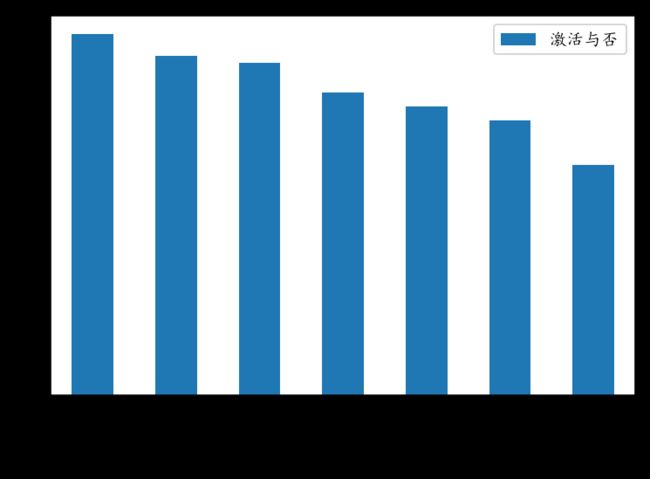
按某一列聚合再排序,然后画条形图
#按“年龄分级”聚合,之后排序,最后在画条形图
nj_jh=sf_df_fahuo[['年龄分级','激活与否']].groupby(['年龄分级'],as_index=False).mean()
nj_jh.set_index('年龄分级',inplace=True)
print(nj_jh) #查看数据
>>>
激活与否
年龄分级
不惑 0.76
少年 0.58
弱冠 0.69
知命 0.85
老年 0.84
而立 0.73
花甲 0.91
#绘制条形图
nj_jh.sort_values("激活与否",ascending=False).plot.bar()
import pylab as pl
pl.xticks(rotation=45) #matplotlib画图,x轴标签旋转45度
# nj_jh.label.set_rotation(45)
# nj_jh.set_title("年龄分级与激活与否的分布关系")
Matplotlib中指定图片大小和像素
plt.rcParams['figure.figsize'] = (8.0, 4.0) # 设置figure_size尺寸
plt.rcParams['image.interpolation'] = 'nearest' # 设置 interpolation style
plt.rcParams['image.cmap'] = 'gray' # 设置 颜色 style
#figsize(12.5, 4) # 设置 figsize
plt.rcParams['savefig.dpi'] = 300 #图片像素
plt.rcParams['figure.dpi'] = 300 #分辨率
# 默认的像素:[6.0,4.0],分辨率为100,图片尺寸为 600&400
# 指定dpi=200,图片尺寸为 1200*800
# 指定dpi=300,图片尺寸为 1800*1200
# 设置figsize可以在不改变分辨率情况下改变比例
绘制直方图(hist)
首先要理清楚一个概念,直方图与条形图。
直方图与条形图的区别:
条形图是用条形的长度表示各类别频数的多少,其宽度(表示类别)则是固定的;
直方图是用面积表示各组频数的多少,矩形的高度表示每一组的频数或频率,宽度则表示各组的组距,因此其高度与宽度均有意义。
由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
条形图主要用于展示分类数据,而直方图则主要用于展示数据型数据。
函数:
matplotlib.pyplot.hist(x,bins=None,range=None, density=None, bottom=None, histtype='bar', align='mid', log=False, color=None, label=None, stacked=False, normed=None)
关键参数
x: 数据集,最终的直方图将对数据集进行统计
bins: 统计的区间分布
range: tuple, 显示的区间,测试发现添加range并没有达到想要的效果,即显示指定区间统计结果,如果有小伙伴知道,欢迎评论,谢谢
density: bool,默认为false,显示的是频数统计结果,为True则显示频率统计结果,这里需要注意,频率统计结果=区间数目/(总数*区间宽度),和normed效果一致,官方推荐使用density
histtype: 可选{‘bar’, ‘barstacked’, ‘step’, ‘stepfilled’}之一,默认为bar,推荐使用默认配置,step使用的是梯状,stepfilled则会对梯状内部进行填充,效果与bar类似
align: 可选{‘left’, ‘mid’, ‘right’}之一,默认为’mid’,控制柱状图的水平分布,left或者right,会有部分空白区域,推荐使用默认
log: bool,默认False,即y坐标轴是否选择指数刻度
stacked: bool,默认为False,是否为堆积状图
import matplotlib.pyplot as plt
import numpy as np
x=np.random.randint(0,100,100)#生成【0-100】之间的100个数据,即 数据集
bins=np.arange(0,101,10)#设置连续的边界值,即直方图的分布区间[0,10],[10,20]...
#直方图会进行统计各个区间的数值
plt.hist(x,bins,color='fuchsia',alpha=0.5)#alpha设置透明度,0为完全透明
plt.xlabel('scores')
plt.ylabel('count')
plt.xlim(0,100)#设置x轴分布范围
plt.show()
用Python为直方图绘制拟合曲线的两种方法
直方图是用于展示数据的分组分布状态的一种图形,用矩形的宽度和高度表示频数分布,通过直方图,用户可以很直观的看出数据分布的形状、中心位置以及数据的离散程度等。
在python中一般采用matplotlib库的hist来绘制直方图,至于如何给直方图添加拟合曲线(密度函数曲线),一般来说有以下两种方法。
方法一:采用matplotlib中的mlab模块
mlab模块是Python中强大的3D作图工具,立体感效果极佳。在这里使用mlab可以跳出直方图二维平面图形的限制,在此基础上再添加一条曲线。在这里,我们以鸢尾花iris中的数据为例,来举例说明。
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
import pandas
# Load dataset
url =
"https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
names = ['sepal-length', 'sepal-width','petal-length', 'petal-width', 'class']
dataset = pandas.read_csv(url, names=names)
print(dataset.head(10))
# descriptions
print(dataset.describe())
x = dataset.iloc[:,0] #提取第一列的sepal-length变量
mu =np.mean(x) #计算均值
sigma =np.std(x)
mu,sigma
以上为通过python导入鸢尾花iris数据,然后提取第一列的sepal-length变量为研究对象,计算出其均值、标准差,接下来就绘制带拟合曲线的直方图
num_bins = 30 #直方图柱子的数量
n, bins, patches = plt.hist(x, num_bins,normed=1, facecolor='blue', alpha=0.5)
#直方图函数,x为x轴的值,normed=1表示为概率密度,即和为一,绿色方块,色深参数0.5.返回n个概率,直方块左边线的x值,及各个方块对象
y = mlab.normpdf(bins, mu, sigma)#拟合一条最佳正态分布曲线y
plt.plot(bins, y, 'r--') #绘制y的曲线
plt.xlabel('sepal-length') #绘制x轴
plt.ylabel('Probability') #绘制y轴
plt.title(r'Histogram : $\mu=5.8433$,$\sigma=0.8253$')#中文标题 u'xxx'
plt.subplots_adjust(left=0.15)#左边距
plt.show()
以上命令主要采用mlab.normpdf基于直方图的柱子数量、均值、方差来拟合曲线,然后再用plot画出来,这种方法的一个缺点就是画出的正态分布拟合曲线(红色虚线)并不一定能很好反映数据的分布情况。
方法二:采用seaborn库中的distplot绘制
Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充,而不是替代物。
import seaborn as sns
sns.set_palette("hls") #设置所有图的颜色,使用hls色彩空间
sns.distplot(x,color="r",bins=30,kde=True)
plt.show()
在这里主要使用sns.distplot(增强版dist),柱子数量bins也设置为30,kde=True表示是否显示拟合曲线,如果为False则只出现直方图。
在这里注意一下它与前边mlab.normpdf方法不同的是,拟合曲线不是正态的,而是更好地拟合了数据的分布情况,如上图,因此比mlab.normpdf更为准确。
进一步设置sns.distplot,可以采用kde_kws(拟合曲线的设置)、hist_kws(直方柱子的设置),可以得到:
import seaborn as sns
import matplotlib as mpl
sns.set_palette("hls")
mpl.rc("figure", figsize=(6,4))
sns.distplot(x,bins=30,kde_kws={"color":"seagreen", "lw":3 }, hist_kws={ "color": "b" }) #其中,lw为曲线粗细程度。
plt.show()
sns.set_palette("hls") #设置所有图的颜色,使用hls色彩空间
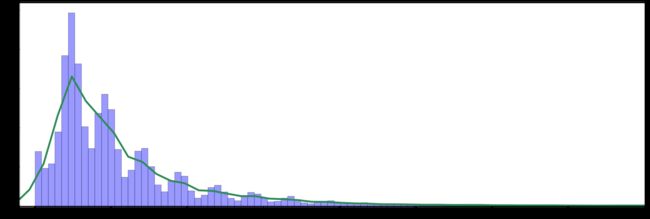
mpl.rc("figure", figsize=(30,10))
sns.distplot(jy_jh['交易周期'],color="r",bins=200,kde_kws={"color":"seagreen", "lw":5 },
hist_kws=dict(edgecolor='k',color='b')) #edgecolor设置柱子边界线,color设置柱子颜色
plt.xlabel('交易周期')
plt.ylabel('订单量')
plt.xlim(-10,400)#设置x轴分布范围
python详解pandas.DataFrame.plot( )画图函数
DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False,
sharex=None, sharey=False, layout=None,figsize=None,
use_index=True, title=None, grid=None, legend=True,
style=None, logx=False, logy=False, loglog=False,
xticks=None, yticks=None, xlim=None, ylim=None, rot=None,
xerr=None,secondary_y=False, sort_columns=False, **kwds)
参数详解如下:
Parameters:
x : label or position, default None#指数据框列的标签或位置参数
y : label or position, default None
kind : str
‘line’ : line plot (default)#折线图
‘bar’ : vertical bar plot#条形图
‘barh’ : horizontal bar plot#横向条形图
‘hist’ : histogram#柱状图
‘box’ : boxplot#箱线图
‘kde’ : Kernel Density Estimation plot#Kernel 的密度估计图,主要对柱状图添加Kernel 概率密度线
‘density’ : same as ‘kde’
‘area’ : area plot#不了解此图
‘pie’ : pie plot#饼图
‘scatter’ : scatter plot#散点图
‘hexbin’ : hexbin plot#不了解此图
ax : matplotlib axes object, default None#一个图片切成不同片段,子图对象
subplots : boolean, default False#判断图片中是否有子图
sharex : boolean, default True if ax is None else False#如果有子图,子图共x轴刻度,标签
sharey : boolean, default False#如果有子图,子图共y轴刻度,标签
layout : tuple (optional)#子图的行列布局
layout : tuple (optional)#子图的行列布局
(rows, columns) for the layout of subplots
figsize : a tuple (width, height) in inches#图片尺寸大小
use_index : boolean, default True#默认用索引做x轴
Use index as ticks for x axis
title : string#图片的标题用字符串
Title to use for the plot
grid : boolean, default None (matlab style default)#图片是否有网格
Axis grid lines
legend : False/True/’reverse’#子图的图例,添加一个subplot图例(默认为True)
Place legend on axis subplots
style : list or dict#对每列折线图设置线的类型
matplotlib line style per column
logx : boolean, default False #设置x轴刻度是否取对数
Use log scaling on x axis
logy : boolean, default False #设置x轴刻度是否取对数
Use log scaling on y axis
loglog : boolean, default False#同时设置x,y轴刻度是否取对数
Use log scaling on both x and y axes
xticks : sequence#设置x轴刻度值,序列形式(比如列表)
Values to use for the xticks
yticks : sequence#设置y轴刻度,序列形式(比如列表)
Values to use for the yticks
xlim : 2-tuple/list#设置坐标轴的范围,列表或元组形式
ylim : 2-tuple/list
rot : int, default None#设置轴标签(轴刻度)的显示旋转度数
Rotation for ticks (xticks for vertical, yticks for horizontal plots)
fontsize : int, default None#设置轴刻度的字体大小
Font size for xticks and yticks
colormap : str or matplotlib colormap object, default None#设置图的区域颜色
Colormap to select colors from. If string, load colormap with that name from matplotlib.
colorbar : boolean, optional #图片柱子
If True, plot colorbar (only relevant for ‘scatter’ and ‘hexbin’ plots)
position : float
Specify relative alignments for bar plot layout. From 0 (left/bottom-end) to 1 (right/top-end). Default is 0.5 (center)
layout : tuple (optional) #布局
(rows, columns) for the layout of the plot
table : boolean, Series or DataFrame, default False #如果为正,则选择DataFrame类型的数据并且转换匹配matplotlib的布局。
If True, draw a table using the data in the DataFrame and the data will be transposed to meet matplotlib’s default layout. If a Series or DataFrame is passed, use passed data to draw a table.
yerr : DataFrame, Series, array-like, dict and str
See Plotting with Error Bars for detail.
xerr : same types as yerr.
stacked : boolean, default False in line and
bar plots, and True in area plot. If True, create stacked plot.
sort_columns : boolean, default False # 以字母表顺序绘制各列,默认使用前列顺序
secondary_y : boolean or sequence, default False ##设置第二个y轴(右y轴)
原文链接:
https://blog.csdn.net/sinat_24395003/article/details/60364345
https://blog.csdn.net/brucewong0516/article/details/80524442
参考链接:
https://www.jianshu.com/p/65395b00adbc
brewer2mpl的用法
set1 = brewer2mpl.get_map('PuBu', 'sequential', 9, reverse=True).mpl_colors
turnstile_day.plot(ax=ax,kind='bar',color=set1)
set1 = brewer2mpl.get_map('PuBu', 'sequential', 9, reverse=True).mpl_colors 中的参数仅表示图片的配色效果,无任何其他含义,常见的配色效果参数如下:
set1 = brewer2mpl.get_map('Set1', 'qualitative',3).mpl_colors
set1 = brewer2mpl.get_map('Set1', 'Qualitative', 9).mpl_colors
set2 = brewer2mpl.get_map('Set2', 'Qualitative', 8).mpl_colors
set2 = brewer2mpl.get_map('Set2', 'Qualitative', 8).mpl_colors
bmap = brewer2mpl.get_map('Paired', 'Qualitative', 5, reverse=True)
"set3 = brewer2mpl.get_map('Set3', 'qualitative', 6).mpl_colors
par['axes.color_cycle'] = brewer2mpl.get_map('Pastel2', 'Qualitative', 7).mpl_colors
bmap2 = brewer2mpl.get_map('Oranges','Sequential',5)
bmap_r = brewer2mpl.get_map('Greens', 'Sequential', 8, reverse=True)
cmap = brewer2mpl.get_map('RdPu', 'Sequential', 9,reverse=True).mpl_colormap
cmap = brewer2mpl.get_map('OrRd', 'Sequential', 9,reverse=True).mpl_colormap
gmap = brewer2mpl.get_map('Greys', 'Sequential',6)
bmap = brewer2mpl.get_map('PiYG', 'Diverging',11)
'brewer_qual_1': brewer2mpl.get_map('Set1', 'qualitative', 9).mpl_colors + brewer2mpl.get_map('Dark2', 'qualitative', 8).mpl_colors
参考链接:https://github.com/search?p=8&q=brewer2mpl.get_map&type=Code
seaborn画核密度图
seaborn中的kdeplot可用于对单变量和双变量进行核密度估计并可视化
https://www.cnblogs.com/feffery/p/11128113.html
Seaborn绘制核密度曲线实例详解
https://www.bobobk.com/263.html
seaborn中文帮助文档
https://www.cntofu.com/book/172/docs/25.md
从np.random.normal()到正态分布的拟合
np.random.normal(size,loc,scale)
参数的意义为:
loc:float
此概率分布的均值(对应着整个分布的中心centre)
scale:float
此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
size:int or tuple of ints
输出的shape(控制样本量的大小/规模,size越大,结果越接近正态分布),默认为None,只输出一个值
np.random.seed(42)
data = pd.Series(np.random.normal(loc=180, scale=40, size=600))
data.hist()
pass

【数据可视化】Pandas画直方图
https://blog.csdn.net/ChenVast/article/details/81563561
matplot设置xy轴范围
plt.xlim(x1,x2)
plt.ylim(y1,y2)
相关性分析
2.data.corr()给出了任意两个变量之间的相关系数
data.corr() #相关系数矩阵,即给出了任意两个变量之间的相关系数
data.corr()[u'好'] #只显示“好”与其他感情色彩的相关系数
data[u'好'].corr(data[u'哭']) #两个感情色彩的相关系数