CS231n(Spring 2019)Assignment 1 - SVM
Preprocessing
# Load the raw CIFAR-10 data.
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'
# Cleaning up variables to prevent loading data multiple times (which may cause memory issue)
try:
del X_train, y_train
del X_test, y_test
print('Clear previously loaded data.')
except:
pass
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# As a sanity check, we print out the size of the training and test data.
print('Training data shape: ', X_train.shape)
print('Training labels shape: ', y_train.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape)
Clear previously loaded data.
Training data shape: (50000, 32, 32, 3)
Training labels shape: (50000,)
Test data shape: (10000, 32, 32, 3)
Test labels shape: (10000,)
# Visualize some examples from the dataset.
# We show a few examples of training images from each class.
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes = len(classes)
samples_per_class = 7
for y, cls in enumerate(classes):
idxs = np.flatnonzero(y_train == y)
idxs = np.random.choice(idxs, samples_per_class, replace=False)
for i, idx in enumerate(idxs):
plt_idx = i * num_classes + y + 1
plt.subplot(samples_per_class, num_classes, plt_idx)
plt.imshow(X_train[idx].astype('uint8'))
plt.axis('off')
if i == 0:
plt.title(cls)
plt.show()

# Split the data into train, val, and test sets. In addition we will
# create a small development set as a subset of the training data;
# we can use this for development so our code runs faster.
num_training = 49000
num_validation = 1000
num_test = 1000
num_dev = 500
# Our validation set will be num_validation points from the original
# training set.
mask = range(num_training, num_training + num_validation)
X_val = X_train[mask]
y_val = y_train[mask]
# Our training set will be the first num_train points from the original
# training set.
mask = range(num_training)
X_train = X_train[mask]
y_train = y_train[mask]
# We will also make a development set, which is a small subset of
# the training set.
mask = np.random.choice(num_training, num_dev, replace=False)
X_dev = X_train[mask]
y_dev = y_train[mask]
# We use the first num_test points of the original test set as our
# test set.
mask = range(num_test)
X_test = X_test[mask]
y_test = y_test[mask]
print('Train data shape: ', X_train.shape)
print('Train labels shape: ', y_train.shape)
print('Validation data shape: ', X_val.shape)
print('Validation labels shape: ', y_val.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape)
Train data shape: (49000, 32, 32, 3)
Train labels shape: (49000,)
Validation data shape: (1000, 32, 32, 3)
Validation labels shape: (1000,)
Test data shape: (1000, 32, 32, 3)
Test labels shape: (1000,)
# Preprocessing: reshape the image data into rows
X_train = np.reshape(X_train, (X_train.shape[0], -1))
X_val = np.reshape(X_val, (X_val.shape[0], -1))
X_test = np.reshape(X_test, (X_test.shape[0], -1))
X_dev = np.reshape(X_dev, (X_dev.shape[0], -1))
# As a sanity check, print out the shapes of the data
print('Training data shape: ', X_train.shape)
print('Validation data shape: ', X_val.shape)
print('Test data shape: ', X_test.shape)
print('dev data shape: ', X_dev.shape)
Training data shape: (49000, 3072)
Validation data shape: (1000, 3072)
Test data shape: (1000, 3072)
dev data shape: (500, 3072)
# Preprocessing: subtract the mean image
# first: compute the image mean based on the training data
mean_image = np.mean(X_train, axis=0)
print(mean_image[:10]) # print a few of the elements
plt.figure(figsize=(4,4))
plt.imshow(mean_image.reshape((32,32,3)).astype('uint8')) # visualize the mean image
plt.show()
# second: subtract the mean image from train and test data
X_train -= mean_image
X_val -= mean_image
X_test -= mean_image
X_dev -= mean_image
# third: append the bias dimension of ones (i.e. bias trick) so that our SVM
# only has to worry about optimizing a single weight matrix W.
X_train = np.hstack([X_train, np.ones((X_train.shape[0], 1))])
X_val = np.hstack([X_val, np.ones((X_val.shape[0], 1))])
X_test = np.hstack([X_test, np.ones((X_test.shape[0], 1))])
X_dev = np.hstack([X_dev, np.ones((X_dev.shape[0], 1))])
print(X_train.shape, X_val.shape, X_test.shape, X_dev.shape)
[130.64189796 135.98173469 132.47391837 130.05569388 135.34804082
131.75402041 130.96055102 136.14328571 132.47636735 131.48467347]

(49000, 3073) (1000, 3073) (1000, 3073) (500, 3073)
SVM Classifier
(in cs231n/classifiers/linear_svm.py)
def svm_loss_naive(W, X, y, reg):
"""
Structured SVM loss function, naive implementation (with loops).
Inputs have dimension D, there are C classes, and we operate on minibatches
of N examples.
Inputs:
- W: A numpy array of shape (D, C) containing weights.
- X: A numpy array of shape (N, D) containing a minibatch of data.
- y: A numpy array of shape (N,) containing training labels; y[i] = c means
that X[i] has label c, where 0 <= c < C.
- reg: (float) regularization strength
Returns a tuple of:
- loss as single float
- gradient with respect to weights W; an array of same shape as W
"""
dW = np.zeros(W.shape) # initialize the gradient as zero
# compute the loss and the gradient
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0
for i in range(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]]
for j in range(num_classes):
if j == y[i]:
continue
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0:
loss += margin
dW[:, y[i]] += -X[i,:].T
dW[:, j] += X[i,:].T
# Right now the loss is a sum over all training examples, but we want it
# to be an average instead so we divide by num_train.
loss /= num_train
dW /= num_train
# Add regularization to the loss.
loss += 0.5 * reg * np.sum(W * W)
#############################################################################
# TODO: #
# Compute the gradient of the loss function and store it dW. #
# Rather that first computing the loss and then computing the derivative, #
# it may be simpler to compute the derivative at the same time that the #
# loss is being computed. As a result you may need to modify some of the #
# code above to compute the gradient. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dW += reg * W
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW
# Evaluate the naive implementation of the loss we provided for you:
from cs231n.classifiers.linear_svm import svm_loss_naive
import time
# generate a random SVM weight matrix of small numbers
W = np.random.randn(3073, 10) * 0.0001
loss, grad = svm_loss_naive(W, X_dev, y_dev, 0.000005)
print('loss: %f' % (loss, ))
loss: 9.053956
# Once you've implemented the gradient, recompute it with the code below
# and gradient check it with the function we provided for you
# Compute the loss and its gradient at W.
loss, grad = svm_loss_naive(W, X_dev, y_dev, 0)
# Numerically compute the gradient along several randomly chosen dimensions, and
# compare them with your analytically computed gradient. The numbers should match
# almost exactly along all dimensions.
from cs231n.gradient_check import grad_check_sparse
f = lambda w: svm_loss_naive(w, X_dev, y_dev, 0.0)[0]
grad_numerical = grad_check_sparse(f, W, grad)
# do the gradient check once again with regularization turned on
# you didn't forget the regularization gradient did you?
loss, grad = svm_loss_naive(W, X_dev, y_dev, 5e1)
f = lambda w: svm_loss_naive(w, X_dev, y_dev, 5e1)[0]
grad_numerical = grad_check_sparse(f, W, grad)
numerical: -34.753629 analytic: -34.753629, relative error: 2.742306e-12
numerical: -48.469713 analytic: -48.469713, relative error: 6.065376e-13
numerical: -1.603047 analytic: -1.603047, relative error: 9.472120e-11
numerical: 5.249776 analytic: 5.249776, relative error: 1.141679e-11
numerical: -4.809977 analytic: -4.809977, relative error: 2.608340e-11
numerical: -10.777707 analytic: -10.777707, relative error: 1.961092e-11
numerical: -3.271406 analytic: -3.237796, relative error: 5.163584e-03
numerical: -3.988728 analytic: -3.988728, relative error: 3.997376e-11
numerical: -22.090951 analytic: -22.090951, relative error: 8.991002e-12
numerical: -23.452841 analytic: -23.452841, relative error: 5.544743e-12
numerical: -1.728582 analytic: -1.716928, relative error: 3.382425e-03
numerical: -22.171377 analytic: -22.175782, relative error: 9.933796e-05
numerical: -8.501782 analytic: -8.509761, relative error: 4.690096e-04
numerical: -24.672617 analytic: -24.670656, relative error: 3.974417e-05
numerical: -0.118892 analytic: -0.120984, relative error: 8.721904e-03
numerical: 10.829417 analytic: 10.825013, relative error: 2.033897e-04
numerical: -12.508858 analytic: -12.504099, relative error: 1.902809e-04
numerical: -4.451844 analytic: -4.444428, relative error: 8.335108e-04
numerical: -5.860418 analytic: -5.864526, relative error: 3.503710e-04
numerical: 28.043494 analytic: 28.045330, relative error: 3.273877e-05
# Next implement the function svm_loss_vectorized; for now only compute the loss;
# we will implement the gradient in a moment.
tic = time.time()
loss_naive, grad_naive = svm_loss_naive(W, X_dev, y_dev, 0.000005)
toc = time.time()
print('Naive loss: %e computed in %fs' % (loss_naive, toc - tic))
from cs231n.classifiers.linear_svm import svm_loss_vectorized
tic = time.time()
loss_vectorized, _ = svm_loss_vectorized(W, X_dev, y_dev, 0.000005)
toc = time.time()
print('Vectorized loss: %e computed in %fs' % (loss_vectorized, toc - tic))
# The losses should match but your vectorized implementation should be much faster.
print('difference: %f' % (loss_naive - loss_vectorized))
Naive loss: 9.053956e+00 computed in 0.117306s
Vectorized loss: 9.053956e+00 computed in 0.063829s
difference: 0.000000
# Complete the implementation of svm_loss_vectorized, and compute the gradient
# of the loss function in a vectorized way.
# The naive implementation and the vectorized implementation should match, but
# the vectorized version should still be much faster.
tic = time.time()
_, grad_naive = svm_loss_naive(W, X_dev, y_dev, 0.000005)
toc = time.time()
print('Naive loss and gradient: computed in %fs' % (toc - tic))
tic = time.time()
_, grad_vectorized = svm_loss_vectorized(W, X_dev, y_dev, 0.000005)
toc = time.time()
print('Vectorized loss and gradient: computed in %fs' % (toc - tic))
# The loss is a single number, so it is easy to compare the values computed
# by the two implementations. The gradient on the other hand is a matrix, so
# we use the Frobenius norm to compare them.
difference = np.linalg.norm(grad_naive - grad_vectorized, ord='fro')
print('difference: %f' % difference)
Naive loss and gradient: computed in 0.125662s
Vectorized loss and gradient: computed in 0.003994s
difference: 0.000000
Stochastic Gradient Descent(SGD)
(in cs231n/classifiers/linear_classifier.py)
class LinearClassifier(object):
def __init__(self):
self.W = None
def train(self, X, y, learning_rate=1e-3, reg=1e-5, num_iters=100,
batch_size=200, verbose=False):
"""
Train this linear classifier using stochastic gradient descent.
Inputs:
- X: A numpy array of shape (N, D) containing training data; there are N
training samples each of dimension D.
- y: A numpy array of shape (N,) containing training labels; y[i] = c
means that X[i] has label 0 <= c < C for C classes.
- learning_rate: (float) learning rate for optimization.
- reg: (float) regularization strength.
- num_iters: (integer) number of steps to take when optimizing
- batch_size: (integer) number of training examples to use at each step.
- verbose: (boolean) If true, print progress during optimization.
Outputs:
A list containing the value of the loss function at each training iteration.
"""
num_train, dim = X.shape
num_classes = np.max(y) + 1 # assume y takes values 0...K-1 where K is number of classes
if self.W is None:
# lazily initialize W
self.W = 0.001 * np.random.randn(dim, num_classes)
# Run stochastic gradient descent to optimize W
loss_history = []
for it in range(num_iters):
X_batch = None
y_batch = None
#########################################################################
# TODO: #
# Sample batch_size elements from the training data and their #
# corresponding labels to use in this round of gradient descent. #
# Store the data in X_batch and their corresponding labels in #
# y_batch; after sampling X_batch should have shape (batch_size, dim) #
# and y_batch should have shape (batch_size,) #
# #
# Hint: Use np.random.choice to generate indices. Sampling with #
# replacement is faster than sampling without replacement. #
#########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
batch_inx = np.random.choice(num_train,batch_size)
X_batch = X[batch_inx,:]
y_batch = y[batch_inx]
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# evaluate loss and gradient
loss, grad = self.loss(X_batch, y_batch, reg)
loss_history.append(loss)
# perform parameter update
#########################################################################
# TODO: #
# Update the weights using the gradient and the learning rate. #
#########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
self.W -= learning_rate * grad
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
if verbose and it % 100 == 0:
print('iteration %d / %d: loss %f' % (it, num_iters, loss))
return loss_history
# In the file linear_classifier.py, implement SGD in the function
# LinearClassifier.train() and then run it with the code below.
from cs231n.classifiers import LinearSVM
svm = LinearSVM()
tic = time.time()
loss_hist = svm.train(X_train, y_train, learning_rate=1e-7, reg=2.5e4,
num_iters=1500, verbose=True)
toc = time.time()
print('That took %fs' % (toc - tic))
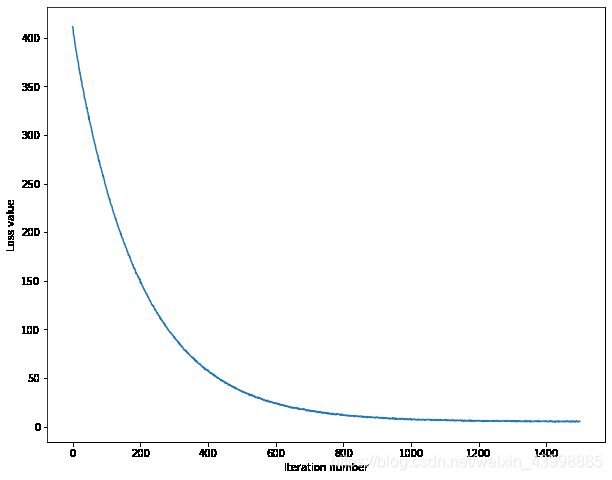
iteration 0 / 1500: loss 411.256562
iteration 100 / 1500: loss 244.689758
iteration 200 / 1500: loss 148.272938
iteration 300 / 1500: loss 92.533291
iteration 400 / 1500: loss 57.345825
iteration 500 / 1500: loss 36.810807
iteration 600 / 1500: loss 24.459797
iteration 700 / 1500: loss 16.620232
iteration 800 / 1500: loss 11.988697
iteration 900 / 1500: loss 9.749128
iteration 1000 / 1500: loss 7.778197
iteration 1100 / 1500: loss 6.811365
iteration 1200 / 1500: loss 6.014506
iteration 1300 / 1500: loss 5.870699
iteration 1400 / 1500: loss 5.501124
That took 7.865505s
# A useful debugging strategy is to plot the loss as a function of
# iteration number:
plt.plot(loss_hist)
plt.xlabel('Iteration number')
plt.ylabel('Loss value')
plt.show()
# Write the LinearSVM.predict function and evaluate the performance on both the
# training and validation set
y_train_pred = svm.predict(X_train)
print('training accuracy: %f' % (np.mean(y_train == y_train_pred), ))
y_val_pred = svm.predict(X_val)
print('validation accuracy: %f' % (np.mean(y_val == y_val_pred), ))
training accuracy: 0.379837
validation accuracy: 0.388000
# Use the validation set to tune hyperparameters (regularization strength and
# learning rate). You should experiment with different ranges for the learning
# rates and regularization strengths; if you are careful you should be able to
# get a classification accuracy of about 0.39 on the validation set.
#Note: you may see runtime/overflow warnings during hyper-parameter search.
# This may be caused by extreme values, and is not a bug.
learning_rates = [1e-7, 5e-5,1e-5]
regularization_strengths = [2.5e4, 5e4, 0.01]
# results is dictionary mapping tuples of the form
# (learning_rate, regularization_strength) to tuples of the form
# (training_accuracy, validation_accuracy). The accuracy is simply the fraction
# of data points that are correctly classified.
results = {}
best_val = -1 # The highest validation accuracy that we have seen so far.
best_svm = None # The LinearSVM object that achieved the highest validation rate.
################################################################################
# TODO: #
# Write code that chooses the best hyperparameters by tuning on the validation #
# set. For each combination of hyperparameters, train a linear SVM on the #
# training set, compute its accuracy on the training and validation sets, and #
# store these numbers in the results dictionary. In addition, store the best #
# validation accuracy in best_val and the LinearSVM object that achieves this #
# accuracy in best_svm. #
# #
# Hint: You should use a small value for num_iters as you develop your #
# validation code so that the SVMs don't take much time to train; once you are #
# confident that your validation code works, you should rerun the validation #
# code with a larger value for num_iters. #
################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
for learning_rate in learning_rates:
for regularization_strength in regularization_strengths:
svm = LinearSVM()
loss_hist = svm.train(X_train, y_train, learning_rate = learning_rate, reg = regularization_strength,
num_iters = 1500, verbose=False)
y_train_pred = svm.predict(X_train)
train_accuracy = np.mean(y_train_pred == y_train)
y_val_pred = svm.predict(X_val)
val_accuracy = np.mean(y_val == y_val_pred)
results[(learning_rate, regularization_strength)] = [train_accuracy, val_accuracy]
if val_accuracy > best_val:
best_val = val_accuracy
best_svm = svm
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# Print out results.
for lr, reg in sorted(results):
train_accuracy, val_accuracy = results[(lr, reg)]
print('lr %e reg %e train accuracy: %f val accuracy: %f' % (
lr, reg, train_accuracy, val_accuracy))
print('best validation accuracy achieved during cross-validation: %f' % best_val)
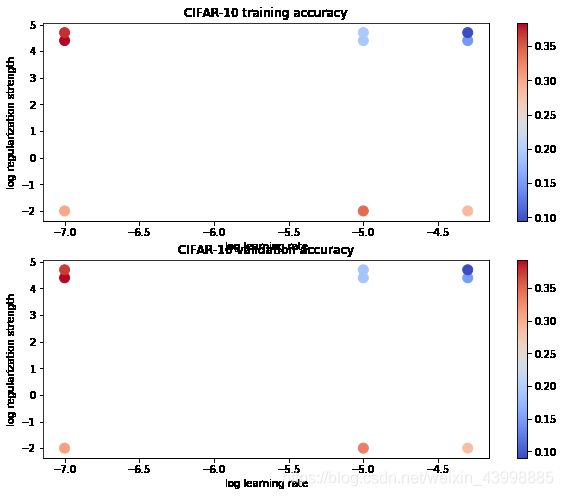
lr 1.000000e-07 reg 1.000000e-02 train accuracy: 0.300816 val accuracy: 0.312000
lr 1.000000e-07 reg 2.500000e+04 train accuracy: 0.383796 val accuracy: 0.393000
lr 1.000000e-07 reg 5.000000e+04 train accuracy: 0.370816 val accuracy: 0.375000
lr 1.000000e-05 reg 1.000000e-02 train accuracy: 0.341224 val accuracy: 0.336000
lr 1.000000e-05 reg 2.500000e+04 train accuracy: 0.193041 val accuracy: 0.188000
lr 1.000000e-05 reg 5.000000e+04 train accuracy: 0.195224 val accuracy: 0.187000
lr 5.000000e-05 reg 1.000000e-02 train accuracy: 0.284980 val accuracy: 0.286000
lr 5.000000e-05 reg 2.500000e+04 train accuracy: 0.149224 val accuracy: 0.148000
lr 5.000000e-05 reg 5.000000e+04 train accuracy: 0.095102 val accuracy: 0.090000
best validation accuracy achieved during cross-validation: 0.393000
# Visualize the cross-validation results
import math
x_scatter = [math.log10(x[0]) for x in results]
y_scatter = [math.log10(x[1]) for x in results]
# plot training accuracy
marker_size = 100
colors = [results[x][0] for x in results]
plt.subplot(2, 1, 1)
plt.scatter(x_scatter, y_scatter, marker_size, c=colors, cmap=plt.cm.coolwarm)
plt.colorbar()
plt.xlabel('log learning rate')
plt.ylabel('log regularization strength')
plt.title('CIFAR-10 training accuracy')
# plot validation accuracy
colors = [results[x][1] for x in results] # default size of markers is 20
plt.subplot(2, 1, 2)
plt.scatter(x_scatter, y_scatter, marker_size, c=colors, cmap=plt.cm.coolwarm)
plt.colorbar()
plt.xlabel('log learning rate')
plt.ylabel('log regularization strength')
plt.title('CIFAR-10 validation accuracy')
plt.show()
# Evaluate the best svm on test set
y_test_pred = best_svm.predict(X_test)
test_accuracy = np.mean(y_test == y_test_pred)
print('linear SVM on raw pixels final test set accuracy: %f' % test_accuracy)
linear SVM on raw pixels final test set accuracy: 0.370000
# Visualize the learned weights for each class.
# Depending on your choice of learning rate and regularization strength, these may
# or may not be nice to look at.
w = best_svm.W[:-1,:] # strip out the bias
w = w.reshape(32, 32, 3, 10)
w_min, w_max = np.min(w), np.max(w)
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
for i in range(10):
plt.subplot(2, 5, i + 1)
# Rescale the weights to be between 0 and 255
wimg = 255.0 * (w[:, :, :, i].squeeze() - w_min) / (w_max - w_min)
plt.imshow(wimg.astype('uint8'))
plt.axis('off')
plt.title(classes[i])
