招商银行fintech评分卡案例
招商银行fintech评分卡案例
- 数据简介
- 数据预处理
- 变量筛选
- 相关性分析
- 模型建立和评价
数据简介
此次分享的数据案例是我的同学参加的2020年招商银行fintech项目时碰到的案例,我就正好拿这个案例来进行了一下评分卡的建模练习,首先此次数据主要包括三个数据集,分别是行为数据、标签数据、交易数据。


训练集和测试集都已经分好,最终的目的如下所示。

数据预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib as mpl
import scipy
mpl.rcParams['figure.figsize'] = (8, 5)
train_beh = pd.read_csv('data/训练数据集_beh.csv')
train_trade = pd.read_csv('data/训练数据集_trd.csv')
train_tag = pd.read_csv('data/训练数据集_tag.csv')
test_beh = pd.read_csv('data/评分数据集_beh_a.csv')
test_trade = pd.read_csv('data/评分数据集_trd_a.csv')
test_tag = pd.read_csv('data/评分数据集_tag_a.csv')
首先观察beh数据集,该数据集中包含字段如下:

我们这里构造两个特征,每个用户的app浏览时长,以及浏览次数最多的页面。
#统计客户最爱浏览网页和网页浏览次数
def most_like_page(df):
dic = {}
dic['app_use_times'] = df['page_no'].count()
dic['most_like_page']= df['page_no'].value_counts().index[0]
s = pd.Series(dic, index = ['app_use_times','most_like_page'])
return s
train_beh_1 = train_beh.groupby('id').apply(most_like_page)
trade数据集字段主要有以下

我们统计每个用户总的交易金额,平均交易金额,最多的交易方向、最多的收支一级分类、最多的收支二级分类。
def trade_amt(df):
dic = {}
dic['trade_amt'] = df['cny_trx_amt'].sum()
dic['most_Dat_Flg3_Cd'] = df['Dat_Flg3_Cd'].value_counts().index[0]
dic['most_Trx_Cod1_Cd'] = df['Trx_Cod1_Cd'].value_counts().index[0]
dic['most_Trx_Cod2_Cd'] = df['Trx_Cod2_Cd'].value_counts().index[0]
dic['avg_trade_amt'] = df['cny_trx_amt'].sum() / len(df)
s = pd.Series(dic, index = ['trade_amt','most_Dat_Flg3_Cd','most_Trx_Cod1_Cd','most_Trx_Cod2_Cd','avg_trade_amt'])
return s
train_trade_1 = train_trade.groupby('id').apply(trade_amt)
最终我们可以得到合并后的train_data:
all_tag = train_tag.merge(train_beh_1, how = 'inner', on = 'id').merge(train_trade_1, how = 'inner', on = 'id')
观察整个数据,发现deg_cd这一列数据缺失较多,于是我们选择舍弃这一列,并将edu_deg_cd和atdd_type这两列数据缺失不多的特征将nan也作为一个特征

#删除deg_cd这一列特征
all_tag.drop('deg_cd', axis = 1, inplace = True)
all_tag.loc[all_tag['edu_deg_cd'].isnull(),'edu_deg_cd'] = 'nan'
all_tag.loc[all_tag['atdd_type'].isnull(), 'atdd_type'] = 'nan'
做好上述处理后,我们将对剩下来的特征分连续型和离散型进行处理。
#连续型变量
continues_variables = ['age','job_year','frs_agn_dt_cnt','l12mon_buy_fin_mng_whl_tms','l12_mon_fnd_buy_whl_tms',
'l12_mon_insu_buy_whl_tms','l12_mon_gld_buy_whl_tms','ovd_30d_loan_tot_cnt','his_lng_ovd_day',
'cur_debit_cnt','cur_credit_cnt','cur_debit_min_opn_dt_cnt','cur_credit_min_opn_dt_cnt','app_use_times'
,'trade_amt','avg_trade_amt' ]
#分类型变量
classified_variation = ['cur_debit_crd_lvl','hld_crd_card_grd_cd','crd_card_act_ind','l1y_crd_card_csm_amt_dlm_cd',
'atdd_type','perm_crd_lmt_cd','gdr_cd','mrg_situ_cd','ic_ind','fr_or_sh_ind','dnl_mbl_bnk_ind',
'dnl_bind_cmb_lif_ind','hav_car_grp_ind','hav_hou_grp_ind','l6mon_agn_ind','vld_rsk_ases_ind',
'fin_rsk_ases_grd_cd','confirm_rsk_ases_lvl_typ_cd','cust_inv_rsk_endu_lvl_cd','l6mon_daim_aum_cd',
'tot_ast_lvl_cd','pot_ast_lvl_cd','bk1_cur_year_mon_avg_agn_amt_cd','loan_act_ind','most_like_page',
'most_Dat_Flg3_Cd','most_Trx_Cod1_Cd','most_Trx_Cod2_Cd','pl_crd_lmt_cd','acdm_deg_cd', 'edu_deg_cd']
all_tag[classified_variation] = all_tag[classified_variation].astype(str)
变量筛选
我们对缺失值进行处理后,接下来就是进行变量的筛选,这里我们选用的woe值编码后通过IV值的筛选方法。
我们使用WoE值代替原始的分组值,WoE的计算公式如下:
W o E i = l n ( # G i / # G T # B i / # B T ) WoE_i = ln\left(\displaystyle \frac {^{\# G_i} / _{\# G_T}}{^{\# B_i} / _{\# B_T}}\right) WoEi=ln(#Bi/#BT#Gi/#GT)
# G i \# G_i #Gi代表某分组好样例个数, # B i \# B_i #Bi代表某分组坏样例个数, # G T \# G_T #GT, # B T \# B_T #BT则代表总的好样本和坏样本的个数。
WoE 值反应了某个特征类别对预测结果(违约率)的影响。
使用WoE对特征值进行编码的意义:
- 使用WoE编码值对特征进行合并,使得不同分类中的数据分布差异明显
- 使用WoE编码计算特征的IV值,根据IV值对特征进行筛选
- 用WoE编码值代替数据原始的分类标签,可以不需要引入哑变量,方便进行逻辑回归,计算出的系数可以直接进行比较
- WoE编码可以处理特征中的空值
IV(Information Value)值主要反应自变量对因变量的预测能力,经常用于建模前的特征筛选。
特征筛选的作用:
- 提高模型泛化能力,减少过拟合
- 减少训练时间
IV 计算公式:
I V i = ( # G i # G T − # B i # B T ) ∗ l n ( # G i / # G T # B i / # B T ) = ( # G i # G T − # B i # B T ) ∗ W o E i IV_i =\left(\displaystyle{\frac{\# G_i}{\# G_T}} - {\frac{\# B_i}{\# B_T}}\right) * ln\left(\displaystyle \frac {^{\# G_i} / _{\# G_T}}{^{\# B_i} / _{\# B_T}}\right) = \left(\displaystyle{\frac{\# G_i}{\# G_T}} - {\frac{\# B_i}{\# B_T}}\right) * WoE_i IVi=(#GT#Gi−#BT#Bi)∗ln(#Bi/#BT#Gi/#GT)=(#GT#Gi−#BT#Bi)∗WoEi
I V = ∑ i n I V i IV =\displaystyle \sum_i^n{IV_i} IV=i∑nIVi
IV值解读:
| IV | 预测能力 |
|---|---|
| < 0.02 | 不具备预测能力,应该放弃 |
| 0.02 - 0.1 | 弱预测能力 |
| 0.1 - 0.3 | 中等预测能力 |
| 0.3 - 0.5 | 强预测能力 |
| >0.5 | 结果可疑,需要重新检查 |
对于连续型变量,我们采用等频分箱,并在等频的基础上加上卡方检验,分箱函数如下
#连续型变量的分箱
def graphforbestbin(DF, X, Y, n=5,q=20,graph=True):
'''
自动最优分箱函数,基于卡方检验的分箱
参数:
DF: 需要输入的数据
X: 需要分箱的列名
Y: 分箱数据对应的标签 Y 列名
n: 保留分箱个数
q: 初始分箱的个数
graph: 是否要画出IV图像
区间为前开后闭 (]
'''
try:
DF = DF[[X,Y]].copy()
DF["qcut"],bins = pd.qcut(DF[X], retbins=True, q=q,duplicates="drop")
coount_y0 = DF.loc[DF[Y]==0].groupby(by="qcut").count()[Y]
coount_y1 = DF.loc[DF[Y]==1].groupby(by="qcut").count()[Y]
num_bins = [*zip(bins,bins[1:],coount_y0,coount_y1)]
for i in range(q):
if 0 in num_bins[0][2:]:
num_bins[0:2] = [(
num_bins[0][0],
num_bins[1][1],
num_bins[0][2]+num_bins[1][2],
num_bins[0][3]+num_bins[1][3])]
continue
for i in range(len(num_bins)):
if 0 in num_bins[i][2:]:
num_bins[i-1:i+1] = [(
num_bins[i-1][0],
num_bins[i][1],
num_bins[i-1][2]+num_bins[i][2],
num_bins[i-1][3]+num_bins[i][3])]
break
else:
break
def get_woe(num_bins):
columns = ["min","max","count_0","count_1"]
df = pd.DataFrame(num_bins,columns=columns)
df["total"] = df.count_0 + df.count_1
df["percentage"] = df.total / df.total.sum()
df["bad_rate"] = df.count_1 / df.total
df["good%"] = df.count_0/df.count_0.sum()
df["bad%"] = df.count_1/df.count_1.sum()
df["woe"] = np.log(df["good%"] / df["bad%"])
return df
def get_iv(df):
rate = df["good%"] - df["bad%"]
iv = np.sum(rate * df.woe)
return iv
IV = []
axisx = []
#卡方检验
while len(num_bins) > n:
pvs = []
for i in range(len(num_bins)-1):
x1 = num_bins[i][2:]
x2 = num_bins[i+1][2:]
pv = scipy.stats.chi2_contingency([x1,x2])[1]
pvs.append(pv)
i = pvs.index(max(pvs))
num_bins[i:i+2] = [(
num_bins[i][0],
num_bins[i+1][1],
num_bins[i][2]+num_bins[i+1][2],
num_bins[i][3]+num_bins[i+1][3])]
bins_df = pd.DataFrame(get_woe(num_bins))
axisx.append(len(num_bins))
IV.append(get_iv(bins_df))
if graph:
plt.figure()
plt.plot(axisx,IV)
plt.xticks(axisx)
plt.xlabel("number of box")
plt.ylabel("IV")
plt.show()
return bins_df
except:
return -1
我们对于每个连续型变量分箱,拿job_year这个变量为例,分箱函数会出现如下结果:
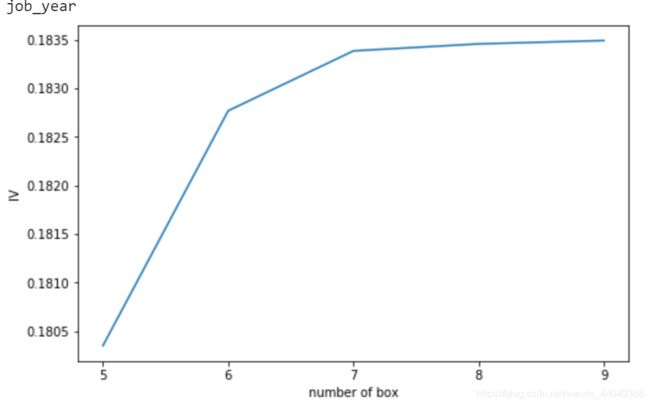
我们观察发现当分为6箱的情况下,变量对应的iv值较原来差不多,但小于6箱时,iv值急速下降,这说明分为6箱能较好的保存信息,因此选择6箱作为分箱数。其他变量也采用这种方法。
auto_col_bins = {'age': 7
,'job_year':6
,"frs_agn_dt_cnt":6
,'cur_credit_min_opn_dt_cnt':7
,'app_use_times':7
,'trade_amt': 7
,'avg_trade_amt':8}
hand_bins = {'l12mon_buy_fin_mng_whl_tms':[0,1,4,5]
,'l12_mon_fnd_buy_whl_tms':[0,1,2,5]
,'l12_mon_insu_buy_whl_tms': [0,1]
,'l12_mon_gld_buy_whl_tms': [0,1]
,'his_lng_ovd_day':[0,1,3]}
hand_bins = {k:[-np.inf,*v[:-1],np.inf] for k,v in hand_bins.items()}
#连续型变量的分箱结果
continue_bins_of_col = {}
for col in auto_col_bins:
bins_df = graphforbestbin(all_tag, col, 'flag',n = auto_col_bins[col], q =20,graph=False)
bins_list = sorted(set(bins_df["min"]).union(bins_df["max"]))
#保证区间覆盖使用 np.inf 替换最大值 -np.inf 替换最小值
bins_list[0],bins_list[-1] = -np.inf,np.inf
continue_bins_of_col[col] = bins_list
#合并手动分箱数据
continue_bins_of_col.update(hand_bins)
#单独定义计算woe值和相应的iv值
def get_woe(df,col,y,bins):
df = df[[col,y]].copy()
df["cut"] = pd.cut(df[col],bins)
bins_df = df.groupby("cut")[y].value_counts().unstack()
bins_df["woe"] = np.log((bins_df[0]/bins_df[0].sum())/(bins_df[1]/bins_df[1].sum()))
return bins_df
def get_iv(df):
rate = df[0] / sum(df[0]) - df[1] /sum(df[1])
iv = np.sum(rate * df.woe)
return iv
最后我们筛选出iv值满足条件的特征
#得到连续型变量的iv字典
iv_all = {}
for col in continue_bins_of_col:
iv_all[col] = get_iv(get_woe(all_tag,col,"flag",continue_bins_of_col[col]))
iv_all
#连续型变量的iv转换成dataframe
continues_iv = pd.DataFrame(iv_all,index = ['iv']).T
continues_iv[continues_iv['iv'] >0.2]
| 特征 | iv |
|---|---|
| age | 2.883654 |
| frs_agn_dt_cnt | 0.328761 |
| cur_credit_min_opn_dt_cnt | 3.557844 |
| app_use_times | 0.625965 |
| trade_amt | 1.272628 |
| avg_trade_amt | 0.607133 |
| l12mon_buy_fin_mng_whl_tms | 1.419786 |
| l12_mon_fnd_buy_whl_tms | 0.425162 |
接下来我们处理的是分类型的变量,分类型变量先按照类别分箱,在通过卡方检验合并相似的箱体
#分类型变量的分箱
def classified_variable(DF, X, Y):
"""分类型变量的woe和iv值计算"""
DF = DF[[X,Y]].copy()
coount = DF.groupby(X).apply(lambda df: df.groupby(Y).count())[X].unstack().fillna(0)
coount_0 = coount[0]
coount_1 = coount[1]
num_bins = [*zip(coount.index, coount_0, coount_1)]
q = len(num_bins)
for i in range(q):
if 0 in num_bins[0][1:]:
num_bins[0:2] = [(str(num_bins[0][0]) + '/' +str(num_bins[1][0]),
num_bins[0][1] +num_bins[1][1],
num_bins[0][2]+ num_bins[1][2])]
continue
for i in range(len(num_bins)):
if 0 in num_bins[i][1:]:
num_bins[i-1: i+1] = [(str(num_bins[i-1][0]) + '/' +str(num_bins[i][0]),
num_bins[i-1][1] + num_bins[i][1],
num_bins[i-1][2] + num_bins[i][2])]
break
else:
break
def get_woe(num_bins):
columns = ["class","count_0","count_1"]
df = pd.DataFrame(num_bins,columns=columns)
df["total"] = df.count_0 + df.count_1
df["percentage"] = df.total / df.total.sum()
df["bad_rate"] = df.count_1 / df.total
df["good%"] = df.count_0/df.count_0.sum()
df["bad%"] = df.count_1/df.count_1.sum()
df["woe"] = np.log(df["good%"] / df["bad%"])
return df
def get_iv(df):
rate = df["good%"] - df["bad%"]
iv = np.sum(rate * df.woe)
return iv
bins_df = pd.DataFrame(get_woe(num_bins))
iv = get_iv(bins_df)
return bins_df, iv
#计算分类型变量的iv值
dic = {}
for i in classified_variation:
# print(i)
bins,iv = classified_variable(all_tag, i, 'flag')
dic[i] = iv
classified_iv = pd.DataFrame(dic,index = ['iv']).T
classified_iv[classified_iv['iv'] > 0.2]
通过IV值筛选过变量之后,我们建立一个映射,这个映射的输入是对应的特征值,输出的是对应特征值所在箱的woe编码。
#筛选出iv值大于0.2的变量,构建连续变量的woe的映射
continues_woe_map = {}
for col in list(continues_iv[continues_iv['iv'] >0.2].index):
continues_woe_map[col] = get_woe(all_tag, col, 'flag',continue_bins_of_col[col])['woe']
#构建分类型变量的woe映射
def process_obj_map(df):
result = []
for idx, (cls, woe) in df.iterrows():
label_list = str(cls).split('/')
for label in label_list:
result.append((label, woe))
return pd.DataFrame(result,columns = ['cut','woe']).set_index('cut')
classified_woe_map = {}
classified_bins_of_col = {}
for col in list(classified_iv[classified_iv['iv'] >0.2].index):
bins_df ,_ = classified_variable(all_tag, col, 'flag')
classified_woe_map[col] = process_obj_map(bins_df[['class','woe']])['woe']
classified_bins_of_col[col] = list(process_obj_map(bins_df[['class','woe']]).index)
model_data = all_tag[selected_variables].copy()
for col in selected_variables:
if col in continues_woe_map.keys():
model_data[col] = pd.cut(model_data[col],continue_bins_of_col[col]).map(continues_woe_map[col])
elif col in classified_bins_of_col.keys():
model_data[col] = model_data[col].map(classified_woe_map[col])
相关性分析
将所有特征转换成woe值后,这样所有的特征就有了一个统一的尺度,接下来就可以进行相关性分析。
#观察映射后的数据的相关性
plt.figure(figsize = (25,20))
sns.heatmap(model_data.corr(),annot=True, cmap='Blues')
我们通过此次相关性角度可以选择相关性较强的特征进行删除。
model_data.drop(['age','acdm_deg_cd','l6mon_daim_aum_cd','trade_amt','pl_crd_lmt_cd','l12mon_buy_fin_mng_whl_tms'
,'cur_credit_min_opn_dt_cnt','pot_ast_lvl_cd','edu_deg_cd','most_Trx_Cod2_Cd','l12mon_buy_fin_mng_whl_tms'
,'confirm_rsk_ases_lvl_typ_cd','perm_crd_lmt_cd','bk1_cur_year_mon_avg_agn_amt_cd','cust_inv_rsk_endu_lvl_cd'
,'atdd_type','fin_rsk_ases_grd_cd'
],axis = 1, inplace = True)
模型建立和评价
接下来我们进行建模,我们选择逻辑回归作为我们的模型,这个模型比较简单,但鲁棒性较强,同时可以比较好的拟合数据。
X = model_data[list(set(model_data.columns)-set(['flag']))]
y = model_data['flag']
from sklearn.model_selection import train_test_split
X_train, X_test,y_train,y_test = train_test_split(X, y, test_size =0.2, shuffle =True)
from sklearn.linear_model import LogisticRegression as LR
lr = LR().fit(X_train,y_train)
lr.score(X_test,y_test)

计算相关AUC值得到0.94
import scikitplot as skplt
#%%cmd
#pip install scikit-plot
test_proba_df = pd.DataFrame(lr.predict_proba(X_test))
skplt.metrics.plot_roc(y_test, test_proba_df,
plot_micro=False,figsize=(6,6),
plot_macro=False)

KS曲线与KS值:
- KS曲线是tpr与fpr差值为纵坐标,以分类阈值(threshold)为横坐标形成的曲线
- tpr与fpr差值绝对值的最大值即为KS值,KS值对应的threshold就是模型的最优分类阈值
- KS值可以作为模型效果的判断标准,一般KS值更大的模型有更好的分类效果
下面再计算ks值,计算模型判定阈值。
fpr, tpr, threshold = roc_curve(y_test, lr.predict_proba(X_test)[:,1], pos_label=1)
# 计算 tpr 与 fpr 差值绝对值的最大值
ks = max(abs(tpr - fpr))
ks
# 找到 KS 值对应的threshold
best_threshold = threshold[np.argmax(abs(tpr - fpr))]
best_threshold
# 生成KS曲线
plt.plot(1 - threshold, tpr)
plt.plot(1 - threshold, fpr)
plt.plot(1 - threshold, tpr - fpr)
plt.xlim(0,(1-threshold).max())
plt.axvline(1 - best_threshold, color='y', linewidth=1)
plt.legend(['tpr', 'fpr', 'ks_cure'])

模型最大ks值为0.72,对应阈值为0.145