FuzzFactory:Domain-Specific Fuzzing with Waypoints
论文 FuzzFactory: Domain-Specific Fuzzing with Waypoints
作者:R. Padhye, C. Lemieux, K. Sen, L. Simon, and H. Vijayakumar
发表:Proc. ACM Program. Lang., Vol. 3, No. OOPSLA, Article 174. Publication date: October 2019.
一、引言
覆盖导向的模糊测试作为一种高效的方法,在分析二进制数据的程序中发现安全漏洞,如缓冲区溢出,已经得到了重视。最近,研究人员针对不同的领域特定的测试目标,对覆盖引导的模糊算法进行了各种专门化,如寻找性能瓶颈、生成有效的输入、处理幻数字节比较等。每一种解决方案都需要非平凡的实现工作,并产生不同的变量一个模糊的工具。我们观察到许多领域特定的解决方案遵循一种通用的解决方案模式。在本文中,我们提出了FuzzFactory,一个开发领域特定的模糊应用程序的框架,而不需要改变变异和搜索启发式。FuzzFactory允许用户在测试执行期间指定特定于域的动态反馈的集合,以及如何聚合这些反馈。FuzzFactory使用这些信息选择性地保存中间输入,称为航路点(waypoints),以增强覆盖率引导的模糊。这些航路点总是朝着特定领域的多维目标前进。我们使用FuzzFactory实例化了六个领域特定的fuzzing应用程序:三个先前工作的重新实现和三个新的解决方案,并根据Google的fuzzer测试套件中的基准测试评估了它们的有效性。我们还展示了如何组合多个域以使其性能优于其部分的总和。
二、问题提出
糊测试除了发现程序崩溃之外还有其他应用。例如,模糊测试可以用于定向测、基于性能的测试、差异测试、侧信道分析、发现算法复杂性漏洞、发现性能热点等等。在每种情况下,研究人员都修改了最初的模糊算法,以产生一个专门的解决方案。对此问题,研究人员调整了最初的CGF算法,以利用来自程序的特定于域的信息来提高代码覆盖率。
但是,对于每一个新的领域,研究人员都必须找到一种方法来调整模糊算法并产生新的AFL变种或其他模糊工具。每个这样的解决方案都需要不同的实现。此外,这些变体是独立的,不易组合。
三、FuzzFactory框架
基于这个问题,论文中提出了FuzzFactory,这是一个统一的框架:实现特定领域fuzzing程序的框架。
框架是基于以下观察:许多领域特定的模糊化问题最终是为了获得更大的覆盖率,除了那些只提高代码覆盖率的问题外,还可以选择性地保存新生成的输入以备后续的变异。我们称这些中间输入航路点(waypoints)。简单来说,我们不仅要保留能够使得覆盖率增大的种子信息,还要保留更多有用的点的信息,这些点能使得变异更容易触发新的覆盖率。这些点叫做航路点。
文中举了两个例子进行说明应当保留怎样的点作为航路点。
第一个例子进行下图的算法,对于这个算法,函数测试将两个16位整数a和b作为输入,第2、3、4行的比较条件还比较容易触发,但是想第5行的条件则非常困难,将这种情况称为硬比较。但是如右图,我们起初输入i1, i2、i3、i4分别满足2-4行,i5则未触发新的路径。此时如果是常用的方法,则会直接抛弃i5,对i4进行进一步的变异得到i8。然而我们可以看到,i5向i7变异使得其满足第5行条件的可能性要比i8变异得到i7的可能性大得多,因为i5中a、b匹配的位数要比之前任何时候都大,因此我们不应该简单地抛弃i5。在这种情况下,匹配的位数也应当作为一个标准来判断是否应当保存用例。

第二个例子是针对malloc动态分配调用来生成最大的内存分配值,这可以用于压力测试。同样是上面这个算法,从i8到i9并没有触发新的覆盖范围,然而却是是使得malloc的范围更大了,因此也却是应当被保留。
总的来说,对于特定领域的fuzz,用户指定除了覆盖率信息外,还需要指定从被测程序的执行中收集哪些自定义的反馈信息。这主要需要指定两个函数,(1)从程序执行过程中收集的特定类型的反馈,以及(2)如何使用此反馈来确定输入是否应被视为有趣并被保存。
这个框架的主要贡献是:提出了模糊算法和被测程序反馈选择之间的关注分离。
四、waypoints航路点
这里论文中给出了元组表示以及各元素的一些性质公式,为了方便理解,这里不对公式进行说明,尽可能直接阐述结论。
(1)反馈值的计算:waypoints问题中,我们将用户指定的这个特定类型反馈的值称为聚合值,而reducer函数则是用于计算聚合值的,当reducer函数满足某一条件时我们这个输入保存下来作为waypoints。例如在malloc问题中,reducer函数就是计算申请内存值的大小,即max(old,(new+old))。关于reducer函数的性质有两个:
【性质一】幂等性 与同一个输入进行多次结合或一次结合的结果相同。即max(old,(new+old))=max(max(old,(new+old)),(new+old))
【性质二】交换性 即先与哪一个输入进行结合都不影响结果。即max(max(old,new1+old),(new2+old+new1))=max(max(old,new2+old),(old+new2+new1))
当满足这两个性质是,可以确保通过reducer函数选出的waypoints对加速fuzz有帮助。但是,FuzzFactory不会静态验证这些性质,用户需自行确保所选的reducer函数满足性质1和2。
(2)航路点waypoints的判断:如果对输入的执行导致某一个反馈值发生更改,我们将保存输入这个输入。
(3)反馈值变化的单调性:反馈值的变化总是指向一个方向,这个方向意味着某种领域特定的进展。例如malloc,返回的分配内存的最大大小一定是不断增大的。
根据单调性可推:输入i被认为是一个航路点,需要某个反馈值取得进展,而不牺牲任何其他反馈值的进展。
(4)组成域:用户可以为被测程序自然地组成多个域(即将测试用例分词多个组)。在整体域内的waypoints应当与所有小域内waypoints的集合相同。
五、实现

算法如上图,这基于覆盖率引导的模糊测试,灰色部分即此模块对fuzz的扩展。扩展主要分为两个部分:
(1)在程序p对输入i′执行的过程中,该算法不仅收集覆盖率,而且还收集特定域的反馈映射dsf i1…dsf
(2)然后使用调is_waypoint(i′,S,D)中的那些映射来确定是否应将新输入i′添加到保存的输入集S中。
六、应用
-----这部分我基本保留了文章中的内容,毕竟实验结果还是要完整些好*------
论文中将这个框架分别运用到了6个独立的领域特定的模糊应用程序。
(1) slow:一个用于最大化执行路径长度的应用程序,基于SlowFuzz。这是FuzzFactory中要实现的最简单的域。
(2) perf:基于PerfFuzz,通过最大化基本块执行计数来发现热点的应用程序。。在FuzzFactory中,这自然是慢的。
(3) mem:一种新的应用程序,用于生成最大化动态内存分配的输入。
(4) 有效性:有效性模糊算法的应用,它试图将输入生成偏向于满足程序特定有效性检查的输入。
(5) cmp:用于平滑硬比较的域。虽然之前的很多工作都是针对这个应用,但是我们的特定解决方案是新颖的。
(6) diff:一种用于测试程序中代码更改后增量模糊化的新应用程序。
在fuzzfactory框架下,上述六个域中的四个可以在30行C++代码中实现。当对输入执行测试程序时,需要检测收集特定于域的反馈值。此类检测在编译时执行。尽管我们的实现在LLVM IR级别执行检测。下表列出了这6个情况下使用的一些钩子、操作和实用程序函数,我们在特定于域的检测的抽象描述中使用这些函数。
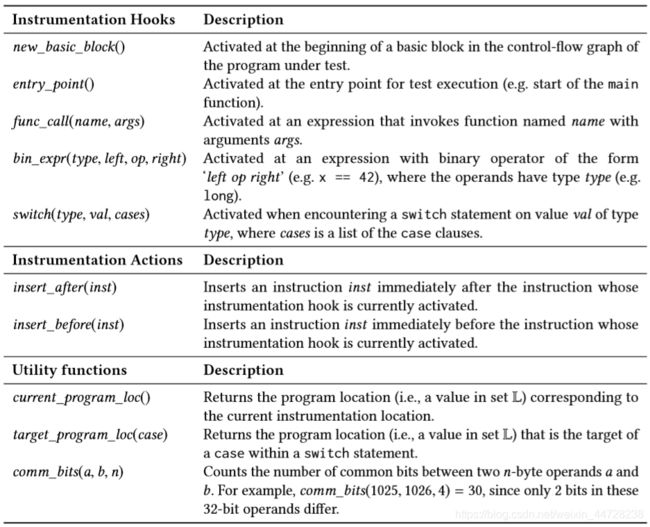
当通过测试程序时遇到程序中的相应元素时,检测框架(例如LLVM)在编译时激活钩子。
以下是六个例子的详细情况:
(一)slow:最大化执行路径
模糊测试可以用来生成使被测程序的算法复杂度恶化的输入。其方法为:搜索使用一个适应度函数,该函数计算在执行单个测试输入期间执行的基本块数,我们将此度量称为执行路径长度,我们的目标是使基本块尽量多。因此,is_waypoint实现的功能应该是:如果输入的执行块比其他输入都要多,则应保存这个输入。
表3为框架基于这一问题进行的修改。利用hook定义entry_point和new_basic_block。dsf(0)表示测试输入的执行长度。在被测程序的入口点,插入一个将dsf(0)设置为0的语句。然后,在程序中的每个基本块上,插入一个语句,该语句递增存储在dsf(0)中的值。因此,在测试执行期间,dsf(0)的值在每次访问基本块时递增一。在测试输入执行结束时,dsf(0)的值将包含执行路径长度。由于该域的reducer函数定义为max,初始值为0(见表3的第一行)。

实验结果:上图显示了我们在基准程序上使用这个应用程序的实验结果。在24小时的模糊化之后,我们评估了基准(afl)和slow的最大执行路径长度(跨越生成的测试语料库)。该图绘制了12次重复中该指标的平均值和标准误差。对于libpng,域特定反馈允许生成路径长度大于基线长度2.5倍的输入。对于boringssl和libxml来说,增长并没有那么显著。但是,slow的最大执行路径长度实际上低于afl在其余三个基准上发现的最大执行路径长度。对这个结果的一个可能的解释是,从第一个输入开始,缓慢地尝试积极地最大化执行路径长度。另一方面,afl将时间花在最大化代码覆盖率上,并发现测试程序组件中不由种子输入执行的较长执行路径。这种差异在libarchive中最为明显。在我们考虑的所有基准中,libarchive是唯一一个在Google测试套件中提供的初始种子输入无效的基准。也就是说,libarchive的初始种子输入会导致测试程序在错误状态下提前退出。由于AFL 24小时只增加代码覆盖率,因此它能够最终生成有效存档(例如ZIP文件)的输入,其处理导致更长的执行路径。在libpng等基准测试中,提供的种子输入是有效的,并且已经覆盖了测试程序中有趣的代码路径;因此,slow能够有效地最大化路径长度。当初始种子输入已经提供了良好的代码覆盖率时,这种受SlowFuzz启发的方法似乎最有效。
(二) perf: 发现热点
perf是一个使用模糊测试生成具有病态性能的输入的工具,目的是生成能够多次执行同一个基本块的输入。reducer函数为max。

我们用值0初始化整个DSF映射。每次访问一个新的基本块k时,我们都会增加存储在dsf(k)中的值。这是在instrumentation hook函数new_basic_block中完成的,使用current_program_loc()函数静态获取要检测的基本块的程序位置(请参阅表2)。在测试执行结束时,dsf(k)将包含执行基本块k的次数。由于reducer函数是max,如果新生成的输入增加了测试程序中任何基本块k的执行计数,则该输入将被视为航路点。

实验结果同样以AFL作为基准,另外还与perf进行比较。对于libpng和libjpeg-turbo,perf发现的热点比基线afl发现的热点执行2×和1.7×以上。对于libarchive,perf应用程序的性能要差得多。与前一节中报告的实验类似,这里的主要问题是libarchive提供的初始种子输入导致退出。AFL花费更多的时间来增加codecoverage而不是基本的块执行计数,它最终生成有效的存档文件(例如ZIP)。考虑到libarchive是一个执行解压的程序,生成有效的归档文件就足以发现执行解压的代码组件中的一个巨大热点。另一方面,perf只发现libarchive解析文件元数据的热点。我们的评估表明PerfFuzz算法也依赖于覆盖有趣代码路径的初始种子输入。在所有的基准测试中,perf的结果与专业的PerfFuzz工具相似或稍好一些。
(三)mem:加速内存分配
mem时候用于生成动态分配的最大内存量,可用于压力测试。
 每当测试程序在程序位置k处使用malloc或calloc分配新内存时,我们将dsf (k)的值增加所分配的字节数。在测试执行结束时,dsf (k)的值包含在程序位置k处为所有这样的位置k分配的总字节数。reducer函数仍然是使用max
每当测试程序在程序位置k处使用malloc或calloc分配新内存时,我们将dsf (k)的值增加所分配的字节数。在测试执行结束时,dsf (k)的值包含在程序位置k处为所有这样的位置k分配的总字节数。reducer函数仍然是使用max

实验数据:基准libxml似乎没有执行任何与输入相关的动态内存分配。基准vorbis, libpng, libjpeg-turbo和boringssl,特定于域的模糊应用程序生成的输入分配1.5ל120×更多的内存。对于libpng,我们的应用程序生成了输入PNG图像,其元数据根据测试驱动程序中硬编码的200万像素的验证规则指定了最大允许图像尺寸。尽管这些PNG文件本身的大小只有1KB左右,但它们的处理需要超过24MB的动态分配内存。
(四)valid:有效性模糊测试
大多数随机生成的输入都是无效的;也就是说,它们导致测试程序以错误状态提前退出。例如libpng上的传统CGF不太可能生成许多有效的PNG图像,即使一开始就使用有效的输入进行fuzzing。
在有效性问题中,我们有两种情况需要保存输入:第一、覆盖率增加,有效性不管;第二、新生成的输入有效

首先,我们修改了基准套件附带的测试驱动程序,以添加特定于程序的assume(expr)语句。assume的语义类似于我们更熟悉的断言:如果参数expr在运行时的计算结果为true,那么该语句就是一个no-op;否则,测试执行就会停止。图5演示了我们对libpng测试驱动程序所做的三种单行更改之一。我们没有因为PNG报头无效而提前退出,而是简单地用一个assume语句包装有效性检查。除了boringssl之外,我们能够在所有基准测试的测试驱动程序中进行如此小的更改。整个五基准的司机我们修改,我们添加了1ś3假设语句包装现有的有效性检查在测试驱动程序,改变1ś11行代码。其次,我们对测试程序进行测试,以在测试执行期间用有关代码覆盖率的信息填充DSF映射,这与传统的覆盖引导的fuzzing类似。在运行时,如果要假设的任何参数的计算结果为false,则整个DSF映射将重置为退出前的初始状态。因此,当且仅当测试输入有效时,DSF映射映射传统的代码覆盖率信息。无效的输入不会产生领域特定的反馈。此方案导致算法2的以下行为:如果新生成的输入导致新的累积代码覆盖率,或者如果输入有效并实现了更多的代码覆盖率(即,更改聚合的特定于域的反馈)比迄今为止看到的任何其他有效输入(即,在产生特定领域反馈的输入之间)。

实验结果表明,validityfuzzingenablesenhance在libpng(3%)和libjpeg-turbo(39%)的有效输入中。对于vorbis,有效性反馈似乎没有任何影响。对于libxml,有效性模糊算法在有效输入之间产生的分支覆盖率减少了30%。与其他处理二进制输入数据的基准测试不同,libxml期望有效的输入符合上下文无关的语法。对于这样一个领域,有效性模糊本身似乎是不够的。直观地说,使用字节级的变化来修改有效的XML文件并不一定有助于生成具有不同代码覆盖率的更有效的XML文件。在libarchive上,与往常一样,领域特有的模糊应用不是很有效。由于libarchive被播种了一个无效的输入,在最初几个小时的模糊处理过程中生成的大部分输入都会导致假设失败。当然,有效性模糊算法首先依赖于一些有效的输入,以使特定于域的反馈有用。
(五)cmp:平滑硬比较

其中反馈表示正在比较的两个操作数之间共有的位数V = N。使用max reduce函数;因此,如果新生成的输入最大化了被测程序中任何硬比较操作匹配的比特数,那么它将被保存为一个waypoint。cmp使用了bin_expr、switch、target_program_loc和comm_bits的定义。检测策略如下:首先,在入口点将DSF映射初始化为0,然后,执行诸如整数相等、字符串比较和switch情况语句等操作。插入的代码填充与它们的程序位置对应的DSF映射条目,并在它们的操作数之间观察到公共位的最大计数。

(六) diff: 增量模糊测试
代码更改后的增量fuzzing。为了在复杂软件的稳定版本中发现缺陷,让fuzzing工具运行数小时或数天是一种常见的做法。但是,如果开发人员对这样的软件进行了更改,目前还没有一种简单的方法可以让他们快速模糊地测试更改。一种方法是他们可以使用由软件前一版本上的长期fuzzing会话生成的测试集作为回归测试套件,但是这些输入可能不会执行受软件更改影响的代码路径。另一种方法是也可以用之前生成的输入语料库作为初始种子,然而,他们没有办法与模糊测试器沟通,让它关注影响软件变更的代码路径。为此,论文提出并实现了一个用于增量模糊的领域专用模糊应用程序。这个应用程序的目标是引导fuzzing快速发现访问刚刚修改的代码行的有趣的代码路径。我们将这组修改后的代码行称为diff。为了度量输入执行的路径的多样性,我们将关注基本块转换(BBTs),而不是单独关注基本块。

以此为例,这个程序在第7行执行除法。在原始程序中,除数d总是输入a的倍数,因此第7行上的除法总是安全的。然而对程序的新更改(在第4行将2 * a切换为2 - a)使得除法可以为0。b显示了一些输入和它们通过这个程序的执行路径。执行路径表示为输入执行的BBTs序列。我们使用⟨x, y⟩代表过渡从基本块从行x的基本块的起始行y。我们用符号(闪电图标)表示一个受扩散影响的基本块的执行。
考虑b中的三个输入。Inputi1 (a=3,b=4)执行diff,但不执行第7行上的除法。Inputi2 (a=4,b=4)在第7行执行除法,但在第4行不执行diff。与输入i1和i2相比,输入i3 (a=4,b=3)并没有执行新的bbt,因此常规的覆盖引导fuzzing不会保存它。然而,输入i3是第一个在命中diff后执行到第7行的真正分支,之前的i2压根没执行到第4行,因此i3应当被增量模糊设置有趣,因为它会执行一个受差异变化影响的新代码路径。

表8正式定义了增量模糊域,并描述了工具。我们跟踪基本的块转换,而不是简单的基本块。为了更好地近似路径,DSF映射收集BBT执行块的集合。为了确保我们只跟踪差异后的bbt,该工具还在测试程序中定义了一个新的全局变量hits_diff。这个变量在测试入口点被设置为false。在每个基本块上,工具添加一个检查,以查看基本块是否在within_diff中(即在interest的代码更改中添加或修改了基本块),并将hits_diff设置为true(如果是这样的话)。然后,该BBT的DSF⟨p c⟩只在hits_diff是真的时保存。
对于libpng和libjpeg-turbo,我们的过程产生的diff被起始语料库中的所有输入击中,而对于vorbis,种子语料库中的任何输入最初都没有击中diff,这导致了非常大的diff。正如对如此巨大差异的预期,diff和afl同样成功地在这些基准上发现了各种差异后行为。对于libarchive和boringssl,只有少数输入达到初始diff,diff不是很大。这些更紧密地反映了由我们的技术驱动的增量变化。对于这些基准,FuzzFactory领域特定的fuzzing应用程序diff在diff下游的覆盖率比afl高2.5-3倍。
七、bugs发现
由于在我们的实验中使用的基准测试套件包含了大量模糊化软件的旧的历史版本,所以我们希望在模糊化时只发现以前已知的错误(如果有的话)。令我们惊讶的是,在模糊libarchive 2017年1月快照时,我们发现cmp mem保存的输入在最新版本(2019年3月)中显示了两个先前未知的错误:内存泄漏和导致巨大内存分配的意外整数符号转换。