《深入分布式缓存》之谈一谈SNS关系设计的演进
我们先从最简单的设计开始。
基于DB的最简方案
表达用户信息和相互关系,基于DB只需要两张表可实现,示意如图12-2:

图12-2 用户信息与用户关系表示意图
relation表主要有两个字段followerId和followeeId,一行relation记录表示用户关系拓扑的一条边,由followerId代表的用户指向followeeId代表的用户。
userInfo表关注每个用户的详细信息,比如用户名、注册时间等描述信息。它可以是多个字段,本示例为了简化描述,统一将这些描述信息简化成一个字段。
1. 场景实现
基于relation相关的展示和操作可以如下方式实现。
1)某用户(例如用户B)timeline/feed页面的relation摘要信息展示,可以通过两条SQL实现:
SELECT COUNT(*) FROM table_relation WHEREfollowerId=’userB’;
SELECT COUNT(*) FROM table_relation WHEREfolloweeId=’userB’;
上述两条语句分别展示出了userB的follower和followee数量。
2)某用户(例如用户B)relation页面详细信息展示,分成两个子页面:follower列表展示和followee列表展示:
SELECT followeeId FROM table_relation WHERE followerId=’userB’;
SELECT userId,userInfo FROM table_user_info
WHERE userId IN (#followeeId#...);
SELECT followerId FROM table_relation WHEREfolloweeId=’userB’;
SELECT userId,userInfo FROM table_user_info
WHERE userId IN (#followerId#...);
上述四条语句分别展示被用户B关注的用户和关注用户B的用户列表。
3)某用户(例如用户B)关注/取消关注某用户(例如用户C):
INSERT INTO table_relation (followerId,followeeId)
VALUES (‘userB’,’userC’) ;
DELETE FROM table_relation
WHERE followerId=’userB’ and followeeId=’userC’
2. 问题引入
随着用户数量的增加,table_relation/info表的行数膨胀。如前述小节描述的那样,亿级的用户,每个用户相关关系百级,那么table_relation的行数将膨胀到百亿级别,info表膨胀到亿级。由此,表的水平拆分(sharding)势在必行。
水平拆分需要根据表的某个字段做为拆分字段,例如info表的拆分以userId为拆分字段进行,如图12-3所示:

图12-3 info 表拆分示例
对于某个用户的信息查询,首先根据userId计算出它的数据在哪个分片,再在对应分片的info表里查询到相关数据。userId到分片的映射关系有多种方式,例如hash取模,userId字段的某几个特殊位,hash取模的一致性hash映射等,本章不展开。
对于info表,水平拆分字段的选取较为明确,选取userId即可。但是对relation的水平拆分,如何选取拆分字段显得不那么简单了,如图12-4所示。

图12-4 最简版本水平拆分后的问题
假设根据followerId进行拆分,查询某个用户关注的人显得容易,因为相同followerId的数据一定分布在相同分片上;但是一旦需要查询谁关注了某个用户,这样的查询需要路由到所有分片上进行,因为相同followeeId的数据分散在不同的分片上,查询效率低。由于对于某个用户,查询它的关注者和关注他的用户的访问量是相似的,所以无论根据followerId还是followeeId进行拆分,总会有一半的场景查询效率低下。
我们在此基础上优化DB的table_relation表方案,使之适应sharding。
DB的sharding方案
经过优化后的relation设计如图12-5 所示:

图12-5经过优化后的relation设计
首先将原有的relation表垂直拆分为followee表和follower表,分表记录某个用户的关注者和被关注者,接下来再对followee和follower两张表分别基于userId进行水平拆分。
1. 场景实现
相对于上节的实现方案,sharding后的relation相关操作中,变化的部分如下。
1)某用户(例如用户B)timeline/feed页面的relation摘要信息展示,可以通过两条SQL实现:
calculate sharding slide index by userB
SELECT COUNT(*) FROM table_followee_xx WHERE userId=’userB’;
SELECT COUNT(*) FROM table_follower_xx WHERE userId=’userB’;
针对用户B的关系数量查询可以落在相同分片上进行,所以一次展示只需要查询两次DB。
2)某用户(例如用户B)relation页面详细信息展示,分成两个子页面:follower列表展示和followee列表展示:
calculate sharding slide index by userB
SELECT followeeId FROM table_followee WHEREfollowerId=’userB’;
SELECT followerId FROM table_follower WHEREfolloweeId=’userB’;
calculate sharding slide index by follower/followeeIds
SELECT userId,userInfo FROM table_user_info
WHERE userId IN (#followerId#...,#followerId#);
上述三条语句分别展示被用户B关注的用户和关注用户B的用户列表,其中前两条可以基于落在相同分片上,DB操作次数为两次,但最后一条仍需查询多次DB,我们下文继续讨论如何优化它。
3)某用户(例如用户B)关注某用户(例如用户C):
calculate sharding slide index by userB
START TRANSACTION;
INSERT INTO table_follower (userId,followerId)
VALUES (‘userB’,’userC’) ;
INSERT INTO table_followee (userId,followeeId)
VALUES (‘userB’,’userC’) ;
COMMIT
上述关注用户的操作由上节所述方案的一条变成了两条,并且包装在一个事务中。写入量增加了一倍,但由于水平拆分带来的DB能力的提升远远超过一倍,所以实际吞吐量的提升仍然能够做到随着分片数量线性增加。
2. 问题引入
上述对relation表的查询操作仍然需要进行count,即使在userId上建了索引仍然存在风险:
q 对于某些用户,他们被很多人关注(例如大V类用户),他们在对follower表进行count查询时,需要在userId上扫描的行数仍然很多,我们称这些用户为热点用户。每一次展示热点用户的关注者数量的操作都是低效的。另一方面,热点用户由于被很多用户关注,它的timeline页面会被更频繁的访问,使得原本低效的展示操作总是被高频的访问,性能风险进一步放大。
q 当某个用户的follower较多时,通常在relation页面里无法一页展示完,因此需要进行分页显示,每一页显示固定数量的用户。然而DB实现分页时,扫描效率随着offset增加而增加,使得这些热点用户的relation页展示到最后几页时,变的低效。
q 用户详细信息的展示,每次展示relation页面时,需要对每个follower或者followee分别查询info表,使得info的查询服务能力无法随着info分片线性增加。
引入缓存
针对上节所述三个问题,我们首先引入缓存,数据划分如图12-6所示:
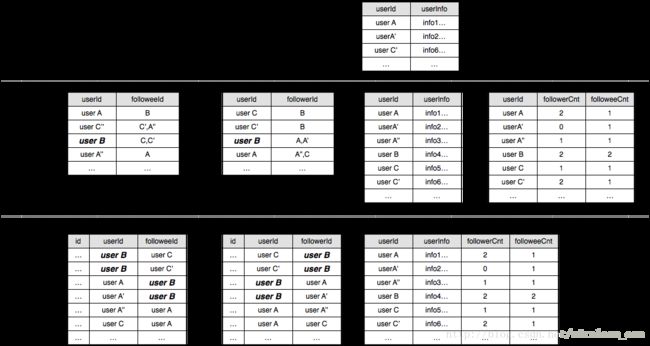
图12-6 数据划分
在DB层,增加userInfo表的冗余信息,将每个用户的关注者和被关注者的数量存入DB。这样一来,对于timeline和feed页的relation摘要展示仅仅通过查询userInfo表即可完成。
同时引入缓存层,需要注意的是,与关系相关的两张表,在缓存层对应的value变成了列表,这样做有两个原因:
q 列表的存储使得查询可以一次IO完成,无需像数据库那样经过二级索引依次扫描相同key对应的所有行。然而数据库很难做到以list做为value的类型并且很好地支撑list相关的增删操作
q 缓存是key-value结构,相同的userId难以分为多个key存储并且还能保证它们高效扫描(缓存的没有DB中的基于key前缀的range扫描)
同时userInfo和userCnt相关信息也分别放入了不同的缓存表中,将DB的一张表分为两张缓存表,原因是info信息和cnt信息的展示场景不同,不同key的频度也不同。
在最上层,对访问量极高的用户的info信息进行服务器端的本地缓存。
1. 场景实现
引入缓存之后的业务操作实现方式也响应做了调整:
1)某用户(例如用户B)timeline/feed页面的relation摘要信息展示:展示方式变成了首先根据用户B做为key查询缓存,未命中时,再查询DB
2)某用户(例如用户B)relation页面详细信息展示,分成两个子页面:follower列表展示和followee列表展示:
q 同样首先查询follower和followee的缓存,对于频繁被查询的热点用户,它的数据一定在缓存中,由此将DB数据量最多、访问频度最高的用户挡在缓存外
q 对于每个用户的info信息,热点用户由于被更多的用户关注,他更有可能在详情页面被查询到,所以这类用户总是在本地缓存中能够查询到。同时,本地缓存设置一个不长的过期时间,使得它和分布式缓存层或者数据库层的数据不会长时间不同步。过期时间的设置和存放本地缓存的服务器数量相关。
3)某用户(例如用户B)关注/取消关注某用户(例如用户C):
q 每一次插入/删除DB的记录时,同时需要对对应缓存的list进行变更。我们可以利用Redis的list/set类型value的原子操作,在一次Redis交互内实现list/set的增删。同时在DB的一个事务中,同时更新userInfo表的cnt字段。
q DB和缓存无法共处于同一个ACID的事务,所以当DB更新之后的缓存更新,通过在DB和缓存中引入两张变更表即可保证更新事件不丢失:DB每次变更时,在DB的事务中向变更表插入一条记录,同时有一个唯一的变更ID或者叫版本号,随后再在缓存中进行修改时,同时也设置这个版本号,再回过来删除DB的这条变更记录。如果缓存更新失败,通过引入定时任务补偿的方式保证变更一定会同步到缓存。
2. 问题引入
relation的相关操作通过缓存和DB冗余的方式基本解决了,但仍然遗留了两个问题:
1)热点用户的follower详情页查询数据量问题。热点用户由于有过长的缓存list,它们每次被查询到的时候有着极高的网络传输量,同时因为热点,它的查询频度也更高,加重了网络传输的负担。
2)info查询的multi-key问题仍然没有完全解决,虽然对热点用户本地缓存的方式避免了distributed缓存的查询,但是每个用户的follower/followee中,大部分用户是非热点用户,它们无法利用本地缓存。由于这些非热点用户的占比更大,info的接收的服务吞吐量需求仍然没有显著减少。
3) info查询中一个重要的信息是被查询实体的followee和follower的数量,尤其是followee数量上限很高(部分热点用户存在百万甚至千万级的量),这两个cnt数量随时变化着,为了使得查询的数值实时,系统需要在尽量间隔短的时间重新进行count,对于热点用户,如果期望实现秒级数据延迟,那么意味着每秒需要对百万甚至千万级别的数据进行count。如何解决这些动态变化着的数据的大访问量、实时性成为挑战。
下一小节叙述如何利用二级缓存和冗余解决这三个问题。
12.2.4 缓存的优化方案
对于上述两个遗留问题,可以通过引入增量化来解决。它对解决上述3个问题提供了基础,其思路是将增量数据做为一等公民(first-class),通过对增量数据的流式处理,支撑relation的各种查询场景,尤其是热点场景。
对于本章中的示例系统,在引入缓存后仍存在的热点场景如下:
1)热点用户(follower很多的用户)的关系详情查询:他/她的关注者列表。
2)所有用户的计数相关摘要,包括热点用户的计数摘要、热点用户的follower/followee的摘要。
首先来看一下增量数据的流转,如图12-7所示:
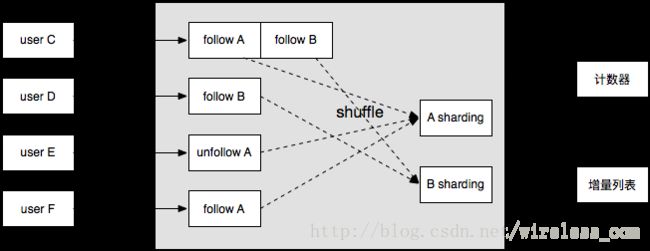
图12-7增量数据的流转
最左侧为增量事件的发起者,例如用户C关注了B和A,则产生两个follow数据,它们将会分别shuffle到A和B所在的数据分片,使得A、B所在的分片中存放者它们各自的变更数据。这些变更以某种方式按照变更产生时间排序,例如唯一主键以createTime时间戳的某种保序压缩(例如将timemillis做36-base编码保证字母序关系不变)做为前缀让DB的查询实现顺序扫描,使得变更数据的订阅方,如计数器或者近期增量列表能够根据变更事件的时间进行获取。
1. 独立的计数服务
对于实时变更着的follower/followee数量的频繁查询,采用数据库的count函数来实现无法保证性能和吞吐量,即便引入缓存,为了保证缓存的时效性,也会因较短间隔的DB count查询引发性能问题。这些问题通过引入单独的计数服务使得count计算做到O(1)的查询复杂度可以得到缓解。
计数服务可以设计成key-value结构,持久化到分布式缓存,key为用户id,value为该用户的follower/followee数量。于是查询服务转化为对缓存的某个key的简单get操作。
对于value的写入,可以利用上述增量化模块,订阅用户收到的变更事件。对于follow事件,直接对key对应的value做自增操作;对于unfollow事件,则做自减操作。例如,对于user C follow了A这个事件,对key为A的value做自增操作。
同时通过对增量化模块中的每个事件记录产生的版本(也可根据时间本身自增来实现),和对计数器每个key进行版本记录,可以实现去重放丢失等需求。
每个key的更新频率取决于单位时间内针对该key的事件数量。例如对于有1亿follower的热点用户,假设每个follower每十天变更一次对某个followee的关注与否(实际上变更频率不会这么频繁),那么改key的变更频率峰值为500次每秒(自然情况下的峰值约等于当天的所有访问平均分布到5~8小时之后的每秒访问量),小于数据库单key的写入吞度量上限(约等于800 tps)。如果考虑批量获取变更事件,则单key峰值写入会更低。
2. 根据事件时间排列的relation详情
当需要查看某个用户的relation详情页时,涉及对follower/followee列表的分页查询。通常单个用户关注的人数量有限,绝大多数用户在1000以内,且每次对第一页的查询频度远高于后续分页,那么无论直接将列表存入DB或是分布式缓存,都能做到较高的吞吐量:DB数据以用户为二级索引,采用默认的排序时大多数情况第一页一个block可以承载;分布式缓存时单个value可以涵盖这些followee列表。
但是,对于热点用户的follower,情况更加复杂一些:follower的数量不可控,使得:
q 即便是小概率的翻页操作,对于follower很多的热点用户,仍然是高访问量的操作;且每次翻页的扫描成本很高
q 单个分布式缓存的value列表无法承载过长的follower列表
针对热点用户的follower列表查询问题,采用基于增量化的实现辅助解决。
首先,同一个用户follower列表的前N页(假设为前5页)的访问概率占到总访问量的绝大部分(假设超过99%),而前N页的follower个数是常数个(假设每页展示20个follower,前5页只有100个follower需要展示);其次,follower列表的展示以follow时间进行排序,最近加入的follower通常排在最前,即增量化模块的最新数据最有可能放在首N页。
基于上述两个假设,针对这99%访问量的前N页,可以直接查询增量数据:做为增量化的消费者每次拉取的最近N页条变更事件直接存入热点用户的follower缓存中,对外提供查询服务。由于变更事件既有follow也有unfollow,无法直接确定拉取多少条,此时可根据历史的follow和unfollow数量比例对“N页条数”进行放大再拉取,之后只取其中的follow事件部分存入缓存。
欲了解更多有关分布式缓存方面的内容,请阅读《深入分布式缓存:从原理到实践》一书。

京东购书,扫描二维码:
