MySQL基础语法(习惯关键字大写,表名库名小写)
创建数据库并显示
create database 数据库名字 show databases; 显示数据库
SHOW CREATE DATABASES db_name; 显示指定数据库的详细信息
select databases();得到当前打开的数据库
创建数据库、表和行或者后面的增删改查都不要使用Mysql的保留关键字,如果必须使用,则用反引号(esc键)括起来
使用这个数据库
use 数据库名
创建表
创建表的时候一般在需要自动增加 的列名后面加上个AUTO_INCREMENT(自增),例如id、order_num等,每次插入数据的时候需要增加一位的列名。另外,每个表都只能有一个列是自增的,并且这个列是主键。
CREATE TABLE 表名(表的内容
名称 类型 ,
名称 类型,
主键(名称)
)默认字符类型
数据基本类型可以参考 anxpp博主整理的MySQL 中的数据类型介绍
CREATE TABLE hero (
id int(11) AUTO_INCREMENT,
name varchar(30) ,
hp float ,
damage int(11) ,
PRIMARY KEY (id)
) DEFAULT CHARSET=utf8;
显示数据库中的表
show tables;
show create table tb_name;显示指定数据表的详细信息(建表语句)
desc tb_name;显示表结构
表结构相关操作
增:
1.增加字段:
2.增加约束:
删:
1.删除字段:
2.删除约束:
单纯删除主键:ALTER TABLE tb_name DROP PRIMERY KEY
删除自增主键(要先把自增删除掉):
1. 用change把自增删除掉(就是相当于重新设置一个主键名称):ALTER TABLE tb_name CHANGE 主键名称 数据类型
2. 第一步过后主键列就会变成一个单纯的主键了,然后进行常规删除就可以了。
改:
1.修改字段类型和属性
2.修改字段类型、名称和属性:
3.
插入数据:
数据类型:
1.数值型(整数型和浮点型)
首先介绍整数型:
整数型的数值类型有如下几种,在Oracle中一般使用(INTEGER)
插入数据的两种方法:
1.insert into 表名 values (第一个,第二个,……第n个)values的值要与相应的列对应
2.INSERT INTO 表名(列名a,列名b,列名c,……,列名n)VALUES(与列名对应的值)
INSERT INTO employee(id,name,phone) VALUES(01,'Tom',110110110);
INSERT INTO employee VALUES(02,'Jack',119119119);
INSERT INTO employee(id,name) VALUES(03,'Rose');
查询数据:
1.查询所有数据
select * from hero
2.统计表中有多少条数
select count(*) from her
3.分页查询,limit添加查询的范围限制,从0开始到第几条
select * from hero limit 0,5
4.去除重复的值,在SELECT语句内给要查询的值前面添加DISTINCT限制
SELECT DISTINCT owner FROM pet;
修改数据
update 表名 set 列名= 修改值 where 第几行
update hero set hp = 818 where id = 1
删除数据
1. 删除数据库:drop database 数据库名称DROP DATABASE book;
2. 删除某一行的数据:
delete from 表名 where 哪一行
delete from hero where id = 5
SQL的约束
约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性。本节实验将在实践操作中熟悉 MySQL 中的几种约束。
| 约束类型: | 主键 | 默认值 | 唯一 | 外键 | 非空 |
|---|---|---|---|---|---|
| 关键字: | PRIMARY KEY | DEFAULT | UNIQUE | FOREIGN KEY | NOT NULL |
- 主键
主键 (PRIMARY KEY)是用于约束表中的一行,作为这一行的唯一标识符,在一张表中通过主键就能准确定位到一行,因此主键十分重要,主键不能有重复记录且不能为空。
还有一种特殊的主键——复合主键。主键不仅可以是表中的一列,也可以由表中的两列或多列来共同标识,在建表语句的最末尾使用
PRIMARY KEY(id,courseId) 创建复合主键id和courseid
-
默认值约束
默认值约束规定,在没有给这一行插入数据时显示默认值DEFAULT(默认值) -
唯一约束
唯一约束规定,这一列的所有值都是唯一的,不能够出现重复。UNIQUE(约束的值) -
外键约束
外键主要用来保证数据的完整性和一致性
外键约束表示的是表与表之间的关系,一个表可以有多个外键,每个外键必须要REFERANCES(参考)有关系那个表的主键。被约束的列,取值必须是他参考的对应表中存在的值,如果不存在则出错。
mysql> CREATE TABLE mark(
-> mid int NOT NULL AUTO_INCREMENT,
-> sid int NOT NULL,
-> cid int NOT NULL,
-> score int NOT NULL,
-> PRIMARY KEY(mid),
-> FOREIGN KEY(sid) REFERENCES student(sid),
-> FOREIGN KEY(cid) REFERENCES course(cid)
-> );
- 非空约束
顾名思义,有非空约束的列不能为空 ,一般搭配默认值约束使用NOT NULL;
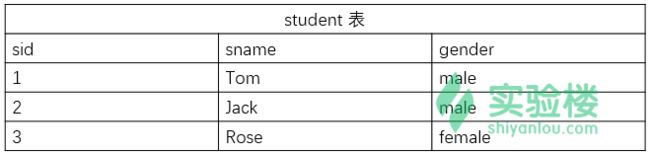
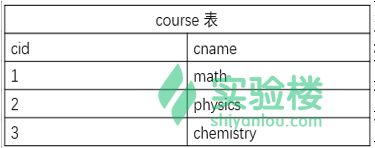
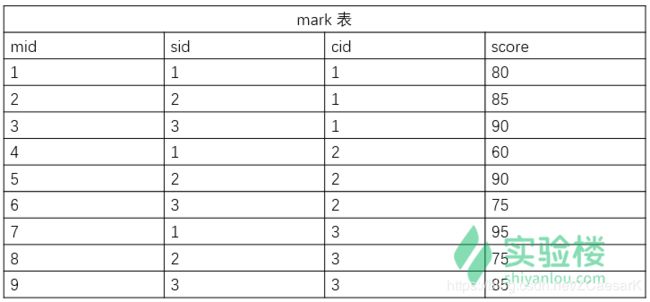
搭建一个简易的成绩管理系统的数据库
 ```
```
$ sudo service mysql start
$ mysql -u root
mysql> CREATE DATABASE gradesystem;
mysql> use gradesystem
mysql> CREATE TABLE student(
-> sid int NOT NULL AUTO_INCREMENT,
-> sname varchar(20) NOT NULL,
-> gender varchar(10) NOT NULL,
-> PRIMARY KEY(sid)
-> );
mysql> CREATE TABLE course(
-> cid int NOT NULL AUTO_INCREMENT,
-> cname varchar(20) NOT NULL,
-> PRIMARY KEY(cid)
-> );
mysql> CREATE TABLE mark(
-> mid int NOT NULL AUTO_INCREMENT,
-> sid int NOT NULL,
-> cid int NOT NULL,
-> score int NOT NULL,
-> PRIMARY KEY(mid),
-> FOREIGN KEY(sid) REFERENCES student(sid),
-> FOREIGN KEY(cid) REFERENCES course(cid)
-> );
mysql> INSERT INTO student VALUES(1,'Tom','male'),(2,'Jack','male'),(3,'Rose','female');
mysql> INSERT INTO course VALUES(1,'math'),(2,'physics'),(3,'chemistry');
mysql> INSERT INTO mark VALUES(1,1,1,80),(2,2,1,85),(3,3,1,90),(4,1,2,60),(5,2,2,90),(6,3,2,75),(7,1,3,95),(8,2,3,75),(9,3,3,85);
SELECT 语句的各种用法
基本格式: SELECT 列a,列b,……,列n FROM 表名 WHERE 限制条件;
WHERE的限制条件可以是“=、<、>、>=、<=”。
WHERE的限制条件利用逻辑关系,“AND”和“OR”还可以表示一定范围内的查询内容,如果要包含边界的话则是“BETWEEN 范围1AND 范围2”
筛选出 age 小于 25,或 age 大于 30
SELECT name,age FROM employee WHERE age<25 OR age>30;
关键字 IN 和NOT IN: 用于穿选出在或不在这个范围内的值
例如:选出在dpt3和dpt4的员工
SELECT name,age,phone,in_dpt FROM employee WHERE in_dpt IN ('dpt3','dpt4');
关键字LIKE+通配符"_“和”%": 关键字LIKE 与通配符搭配使用 进行模糊查询,通配符“”表示某个地方模糊 例如“852377 _” 表示查询前面几位都相同的内容
通配符“%” 则是当不知道模糊多少位时使用,前面的或者后面的模糊位都可以用%代替。
SELEC语句还可以用ORDER BY 排序:
可以对多个列进行排序,每个列用逗号隔开,排序的关键字只作用于在它前面的第一个列名,不相互影响,并且从左到右排序。
SELECT name,age ,salary ,phone FROM employee ORDER BY salary DESC;
DESC为降序排序,ASC是升序排序,默认是升序排序。
SQL内置函数进行计算
| 函数名: | COUNT | SUM | AUG | MAX | MIN |
|---|---|---|---|---|---|
| 作用: | 计数 | 求和 | 求平均值 | 最大值 | 最小值 |
其中COUNT可用于任何类型(因为它只是计数),而SUM 和 AUG 则只能用于数字型类型计算,MAX和MIN可用于数值、字符串或者是日期时间数据类型。
SELECT MAX(salary) AS max_salary,MIN(salary) FROM employee;
用法为:SELECT 计算方法(列名)AS (重命名),方法2,……,FROM 表名;
子查询
有时候查询需要多个表联系在一起才能够查到需要的数据,这时候就需要使用子查询了。子查询是嵌套查询,有多个SELECT语句,由内向外查询。
GRUOUP BY 和 HAVING
GRUOP BY +列名表示对这个列进行分组表示,把名字相同的组合在一起,GUOUP BY 语句一般要与聚合函数搭配使用并且在WHERE语句之后,ORDER BY 语句之前,虽然有时候GROUP BY 子句会自动排序,但并不总是,最好写上ORDER BY 子句。
GROUP BY 还可以进行嵌套使用,可以作用于任意数目的列,然后所有的列一块计算分组。如果有null值,则把null值放在一组。
GROUP BY 子句中的所有列都必须是检索列或者有效的表达式,如果在SELECT中使用表达式,则必须在GROUP BY 中使用相同的表达式。
HAVING语句与WHERE 类似都是表示条件筛选,但是HAVING一般用于分组后的条件筛选,而WHERE只能作用于行
连接查询
需要显示多个表的内容时使用,连接查询有两种方式,一种是用WHERE将多个表相关的内容连接起来WHERE 表1.列 = 表2.列,另一种是用JOIN ON,表1JOIN 表2 ON 表1.列名 = 表2.列名
格式是:SELECT 列1(表1),列2(表1),列3(表2)FROM 表1,表2 WHERE 表1.列名 = 表2.列名
或者是:
SELECT 列1(表1),列2(表1),列3(表2)FROM 表1JOIN表2 ON 表1.列名 = 表2.列名
数据库及表的修改和删除
数据库的删除
DROP DATABASE 数据库名;
表的修改
重命名一张表有三种形式:
RENAME TABLE 旧表名 TO 新表名;
ALTER TABLE 旧表名 RENAME 新表名;
ALTER TABLE 旧表名 RENAME TO 新表名;
增加一列有两种方法:
ALTER TABLE 表名 ADD COLUMN 列名 数据类型 约束;
ALTER TABLE 表名 ADD 列名 数据类型 约束;
如果要增加在某一列的后面可以用AFTER关键字,用FIRST 关键字则加在第一列
删除列也是有两种形式:
ALTER TABLE 表名字 DROP COLUMN 列名字
ALTER TABLE 表名字 DROP 列名字
改列名
如要改数据类型或者约束,则原列名与新列名相同即可。
ALTER TABLE 表名 CHANGE 原列名 新列名 数据类型 约束
修改数据类型还可以(修改:
ALTER TABLE 表名 MODIFY 列名 新数据类型;
删除表
DROP TABLE 表名;
修改表中的某个值
UPDATE 表名 SET 列1 = 值1 ,列2 = 值2 WHERE 条件;
删除一行记录
DELETE FROM 表名 WHERE 条件;
其他基本操作,1.索引 2.视图 3.导入和导出 4.备份和恢复
1.索引
索引类似于书本的目录能够加快我们对数据的查找,索引一般创建在具有唯一性的列中,以达到快速查询的目的,若是建立再值大量重复或格式复杂的列则达不到快速查询的效果甚至会造成数据冗余和额外的CPU开销
索引的创建方法:
ALTER TABLE 表名 ADD INDEX 索引名(列名);
CREATE INDEX 索引名 ON 表名(列名
2.视图
视图是一张由一个表或者多找表中导出的数据组成的一张虚拟的表,也可以是一段SQL语句查询后的数据形成的虚拟的表。
视图方便我们对SQL语句的重用,并且简化了SQL语句。能够保护数据,使用视图时我们只需要操作特定需要的数据内容而不是整个表的访问权限。
更改数据格式和表示,视图可以返回与底层表的表示和格式不同的数据,但数据的值还是底层数据的值,视图依赖于原来表中的数据,底层数据改变,视图也改变。
视图创建后可以把它当做表,必须唯一命名;可以创建的视图没有数量限制;视图可以使用ORDER BY 但如果从视图检索数据的SELECT中有ORDER BY那么视图的将会被覆盖;视图不能有索引,也不能有关联的触发器和默认值。
视图可以嵌套使用也可以和表一块使用,部署大量视图时要进行性能测试。
- 创建视图
CREATE VIEW 视图名(列名a,列b,列c)AS SELECT 列a,列b,列c FROM 表a,表b
还可以加上限制条件
- 查看创建的视图
SHOW CREATE VIEW viewname;
- 删除视图
DROP VIEW viewname;
- 更新视图
可以先删除在创建,也可以使用如下语句
CREATE OR REPLACE VIEW
查看表的结构:
DESCRIBE 表名
从外部导入数据
因为安全原因,文件路径得先拷贝到数据库的安全路径,然后再从这个路径中加载
查看安全路径:
show variables like '%secure%';
拷贝方法
sudo cp -a 文件路径 /安全路径
导入表中
LOAD DATA INFILE '文件路径' INTO TABLE 表名
请注意如果用 Windows 中的编辑器(使用 \r\n 做为行的结束符)创建文件,应使用:
LOAD DATA INFILE '文件路径' INTO TABLE pet LINES
-> TERMINATED BY '\r\n';