LRU Cache + 并查集
什么是LRU Cache
LRU是Least Recently Used的缩写,意思是最近最少使用,它是一种Cache替换算法。
什么是 Cache?
狭义的Cache指的是位于CPU和主存间的快速RAM,
广义上的Cache指的是位于速度相差较大的两种 硬件之间, 用于协调两者数据传输速度差异的结构。
除了CPU与主存之间有Cache, 内存与硬盘 之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache── 称为Internet临时文件夹或 网络内容缓存等。
为什么要用LRU ?
Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选 并舍弃原有的部分内容,从而腾出空间来放新内容。LRU Cache 的替换原则就是将最近最少使用 的内容替换掉。其实,LRU译成最久未使用会更形象, 因为该算法每次替换掉的就是一段时间内 最久没有使用过的内容。
2.LRU Cache的实现
实现LRU Cache的方法和思路很多,但是要保持高效实现O(1)的put和get,那么使用双向链表和 哈希表的搭配是最高效和经典的。使用双向链表是因为双向链表可以实现任意位置O(1)的插入和 删除,使用哈希表是因为哈希表的增删查改也是O(1)。


class LRUCache {
public:
LRUCache(int capacity) : cap(capacity) {
}
int get(int key) {
if (map.find(key) == map.end()) return -1;
auto key_value = *map[key];
cache.erase(map[key]);
cache.push_front(key_value);
map[key] = cache.begin();
return key_value.second;
}
void put(int key, int value) {
if (map.find(key) == map.end()) {
if (cache.size() == cap) {
//抛出 mp中的该位置存储
map.erase(cache.back().first);
//抛出list中的存储
cache.pop_back();
}
}
else {
cache.erase(map[key]);
}
cache.push_front({key, value});
map[key] = cache.begin();
}
private:
int cap;
list<pair<int, int>> cache;//将来存的时候,按照键值对存储
unordered_map<int, list<pair<int, int>>::iterator> map;
};
并查集
1. 并查集原理
在一些应用问题中,需要将n个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个 单元素集合,然后按一定的规律将归于同一组元素的集合合并。在此过程中要反复用到查询某一 个元素归属于那个集合的运算。适合于描述这类问题的抽象数据类型称为并查集(union-find set)。
比如:某公司今年校招全国总共招生10人,西安招4人,成都招3人,武汉招3人,10个人来自不 同的学校,起先互不相识,每个学生都是一个独立的小团体,现给这些学生进行编号:{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; 给以下数组用来存储该小集体,数组中的数字代表:该小集体中具有成员的个 数。(负号下文解释)
毕业后,学生们要去公司上班,每个地方的学生自发组织成小分队一起上路,于是: 西安学生小分队s1={0,6,7,8},成都学生小分队s2={1,4,9},武汉学生小分队s3={2,3,5}就相互认识
了,10个人形成了三个小团体。假设右三个群主0,1,2担任队长,负责大家的出行。
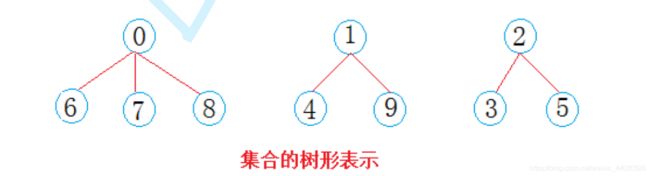
一趟火车之旅后,每个小分队成员就互相熟悉,称为了一个朋友圈。

从上图可以看出:编号6,7,8同学属于0号小分队,该小分队中有4人(包含队长0);编号为4和9的同 学属于1号小分队,该小分队有3人(包含队长1),编号为3和5的同学属于2号小分队,该小分队有3 个人(包含队长1)。
仔细观察数组中内融化,可以得出以下结论:
1. 数组的下标对应集合中元素的编号
2. 数组中如果为负数,负号代表根,数字代表该集合中元素个数
3. 数组中如果为非负数,代表该元素双亲在数组中的下标
在公司工作一段时间后,西安小分队中8号同学与成都小分队1号同学奇迹般的走到了一起,两个 小圈子的学生相互介绍,最后成为了一个小圈子:
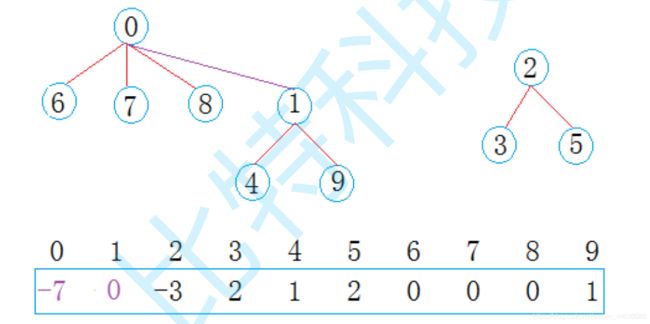
现在0集合有7个人,2集合有3个人,总共两个朋友圈。 通过以上例子可知,并查集一般可以解决一下问题:
- 查找元素属于哪个集合 沿着数组表示树形关系以上一直找到根(即:树中中元素为负数的位置)
- 查看两个元素是否属于同一个集合 沿着数组表示的树形关系往上一直找到树的根,如果根相同表明在同一个集合,否则不在
- 将两个集合归并成一个集合
将两个集合中的元素合并
将一个集合名称改成另一个集合的名称 - 集合的个数 遍历数组,数组中元素为负数的个数即为集合的个数。
并查集的实现:
朋友圈
class UnionFindSet{
public:
// 初始时,将数组中元素全部设置为-1
UnionFindSet(size_t size): _ufs(size, -1) {}
// 给一个元素的编号,找到该元素所在集合的名称
int FindRoot(int index){
// 如果数组中存储的是负数,找到,否则一直继续
while(_ufs[index] >= 0){
index = _ufs[index];
}
return index;
}
bool Union(int x1, int x2){
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
// x1已经与x2在同一个集合
if(root1 == root2)
return false; // 将两个集合中元素合并
_ufs[root1] += _ufs[root2];
// 将其中一个集合名称改变成另外一个
_ufs[root2] = root1;
return true;
}
// 数组中负数的个数,即为集合的个数
size_t Count() const {
size_t count = 0;
for(auto e : _ufs){
if(e < 0)
++count;
}
return count;
}
private:
vector<int> _ufs;
};
class Solution {
public:
int findCircleNum(vector<vector<int>>& M) {
//矩阵的行和列下标相当于人的编号,元素相当于两人是否为朋友关系
UnionFindSet ufs(M.size());
for(size_t i = 0; i < M.size(); ++i)
for(size_t j = 0; j < M[i].size(); ++j) {
// 自己和自己的关系除外
if(i == j)
continue;
// 如果i和j是朋友,将其添加到一个朋友圈
if(1 == M[i][j])
ufs.Union(i, j);
}
return ufs.Count(); }
};