自制Hadoop伪分布、集群安装详细过程(vmware)
Hadoop单机版、伪分布、集群安装教程推荐链接:
http://dblab.xmu.edu.cn/blog/page/2/?s=Hadoop
注:vmware6.5及以上,执行命令基本相同,除了编辑文件时“vi”指令替换为“vim”指令
一、下载安装所需文件
1.vmware10中文版
2.centos6.4
3.jdk1.8-Linux-32位
4.Hadoop2.7.1(要求jdk版本为1.7及以上)
5.spark2.2.1(要求hadoop版本为2.7)
二、安装虚拟机
1.安装vmware(具体细节可百度vmware安装)。
2.新建虚拟机
打开解压过的centos/centos.vmx
3.克隆虚拟机
选中虚拟机/右键/管理/克隆
4.查看虚拟机版本
查看centos版本命令:rpm -q centos-release
查看系统是32位还是64位:getconf LONG_BIT
三、hadoop伪分布安装(选centos虚拟机安装)
1.root用户名登陆,密码hadoop
之后已将主机名修改为hadoop 密码 hadoop IP 192.168.0.253
2.设置IP、主机名、绑定主机名和关闭防火墙
(1)设置静态IP
桌面右上角连接 右键 编辑连接
IPv4 method:从automatic(DCHCP)动态分配IP调整为Manual静态IP
设置与主机在同一个网段 可以用ipconfig和ping IP实现
本机IP 192.168.0.221
vmware vmnet1 192.168.0.251 vmnet8 192.168.0.252

service network restart //重启网卡
(2)修改主机名
hostname //查看当前主机名
hostname hadoop //对于当前界面修改主机名
vi /etc/sysconfig/network 进入配置文件下 修改主机名为hadoop
reboot -h now //重启虚拟机
//执行vi读写操作 按a修改 修改完之后 Esc 输入 :wq 回车 保存退出

3.hostname和主机绑定
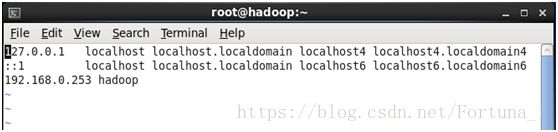
vi /etc/hosts //在前两行代码下添加第三行192.168.0.253 hadoop
之后 ping hadoop验证即可

4.关闭防火墙
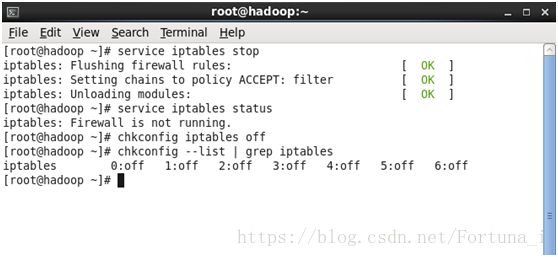
service iptables stop //关闭防火墙
service iptables status //查看防火墙状态
chkconfig iptables off //关闭防火墙自动运行
chkconfig --list | grep iptables //验证是否全部关闭
5.配置ssh免密码登陆(centos默认安装了SSH client、SSH server)
rpm -qa |grep ssh
//验证是否安装SSH,若已安装,界面如下

接着输入ssh localhost
输入yes 会弹出以下窗体内容

即每次登陆都需要密码
exit //退出ssh localhost
cd ~/.ssh/ //若不存在该目录,执行一次ssh localhost
ssh-keygen -t rsa 之后多次回车
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys //加入授权
chmod 600 ./authorized_keys //修改文件权限
注:在 Linux 系统中,~ 代表的是用户的主文件夹,即 "/home/用户名" 这个目录,如你的用户名为 hadoop,则 ~ 就代表 "/home/hadoop/"。

操作完成之后输入ssh localhost验证 出现Last login

6.安装java环境
(1)将本机已下载的jdk1.8上传到centos服务器下:
方法一:下载Xshell5,点击新建文件传输

之后按要求下载Xftp,下载安装之后根据主机IP及用户名和密码登录虚拟机
IP 192.168.0.253 用户名root 密码hadoop
然后将本机已下载好的jdk文件拖拽到虚拟机(可在虚拟机根目录中输入 / )到根目录下的opt文件夹
方法二:右键点击虚拟机,设置/选项/共享文件夹/总是启用 之后新建文件夹share存放在本机中,此文件夹也可在虚拟机根目录中显示 将jdk放入共享文件夹之后copy即可
(2)解压jdk
终端输入命令 rpm -ivh jdk-8u151-linux-i586.rpm //解压jdk安装包
解压之后默认存放在/usr/java/目录下 输入cd /usr/java 再输入ls即可看到解压好的jdk

(3)配置环境变量
vi /etc/profile //修改文件
在最末尾加入以下内容,用于设置环境变量
JAVA_HOME=/usr/java/jdk1.8.0_151
JRE_HOME=/usr/java/jdk1.8.0_151/jre
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME PATH CLASSPATH

之后输入 source /etc/profile //使设置立即生效
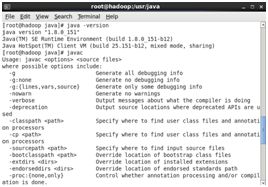
(4)验证
依次输入java java -version javac 查看
7.安装hadoop
(1)解压hadoop
将下载好的hadoop2.7.1copy到虚拟机(/mnt目录下)中
tar -zxf /mnt/hadoop2.7.1.tar.gz -C /usr/local //将hadoop安装包解压到/usr/local/
会有短暂停顿
cd /usr/local ls之后可看到hadoop2.7.1
重命名文件夹 mv ./hadoop2.7.1/ ./hadoop (已跳转到该目录下执行该指令)
也可从computer进入找到文件夹右键重命名
chmod -R 777 ./hadoop //修改文件权限
(2)验证
cd /usr/local/hadoop
./bin/hadoop version

(3)hadoop伪分布配置
a)设置hadoop环境变量
gedit ~/.bashrc // 用记事本打开文件
然后在文件末尾添加如下9行代码
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export JAVA_HOME=/usr/java/jdk1.8.0_151

之后点击上方save保存关闭即可
然后source ~/.bashrc //使配置生效 source+文件
b)修改两个配置文件
首先跳转到配置文件夹下
cd /usr/local/hadoop/etc/hadoop
然后gedit core-site.xml //记事本打开文件
在
etcories.

点击上方save保存退出即可
接着gedit hdfs-site.xml
同样在
注:也可通过文件路径找到这两个文件,然后右键记事本方式打开编辑
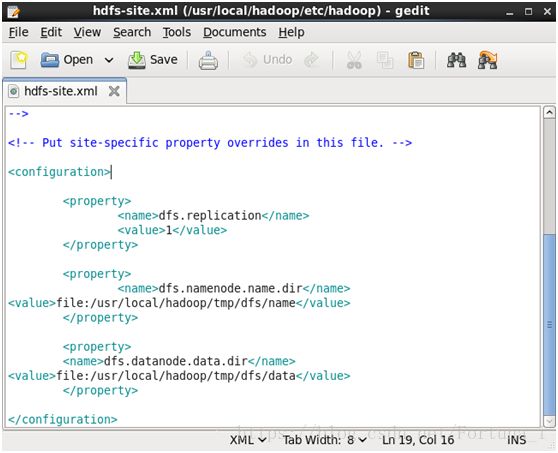
点击上方save保存退出
c)执行namenode格式化
cd /usr/local/hadoop/etc/hadoop
hdfs namenode -format //格式化
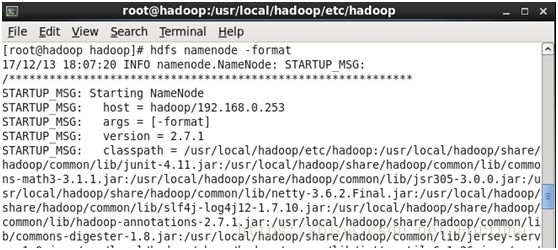
执行成功后会有以下两点提示
成功格式化 退出状态为0(若为1则说明未执行)

注:若此时出现状态为1,很有可能是文件权限问题,可尝试chmod -R 777 dir或者chmod 755 dir及chmod -R ugo+rw dir修改文件属性为可读写。
d)开启namenode和datanode守护进程
首先跳转到sbin文件夹下
cd /usr/local/hadoop/sbin
然后输入start-dfs.sh
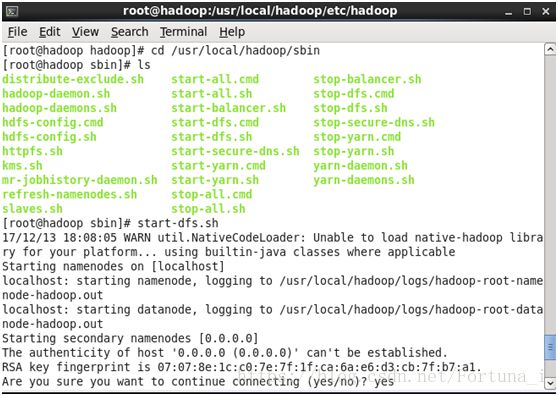
之后会提示开启第二个namenode节点

e)验证
输入jps会出现如下进程

打开浏览器,访问web界面
http://localhost:50070可查看namenode和datanode节点信息

四、安装hadoop集群
1.网络配置
(1)将已经安装好hadoop的虚拟机(centos)克隆出来两个相同的虚拟机(centos2, centos3)
并设置好相关IP及端口(设置完IP需重启)
|
|
本机 |
vmnet1 |
vmnet8 |
centos |
centos2 |
centos3 |
| IP |
192.168.0.221 |
192.168.0.251 |
192.168.0.252 |
192.168.0.253 |
192.168.0.254 |
192.168.0.245 |
| 端口 |
255.255.255.0 |
255.255.255.0 |
255.255.255.0 |
255.255.255.0 |
255.255.255.0 |
255.255.255.0 |
| 网关 |
192.168.0.1 |
192.168.0.1 |
192.168.0.1 |
192.168.0.1 |
192.168.0.1 |
192.168.0.1 |
| 节点 |
|
|
|
主节点 Master |
从节点 Slave1 |
从节点 Slave2 |
(2)将一台机器选定为master(centos),两台机器为slave(centos2,entos3),在 主节点上开启hadoop,然后右键点击虚拟机/设置/网络适配器,将三个节点改为 桥接模式,确定退出
(3)将主节点主机名改为Master,两个从节点改为Slave1,Slave2
vi /etc/sysconfig/network //修改主机名

(4)修改映射关系
vi /etc/hosts //添加映射关系
192.168.0.253 Master
192.168.0.254 Slave1
192.168.0.245 Slave2

注:(3)(4)两步均需要在各个节点上操作,切操作略有差异
(5)验证
首先重启虚拟机reboot -h 之后会看到主机名已分别为Master和Slave1,Slave2
然后测试各节点是否互通,在各节点上输入
ping Master -c 3 //ping3次
ping Slave1 -c 3
ping Slave2 -c 3
若连接成功则应为

2.SSH无密码登陆
为使Master节点可以无密码SSH登陆到各个Slave节点上
(1)在Master节点上生成公钥
cd ~/.ssh //若没有该目录则执行 ssh localhost(肯定有,克隆过来的)
rm ./id_rsa* //删除之前生成的公钥 输入yes后回车
ssh-keygen -t rsa //生成公钥,一直回车就行
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys //修改文件权限
//让Master节点能无密码SSH本机
输入ssh Master验证 执行成功后应为

(2)将公钥copy到各从节点
先exit返回原来终端(.ssh)
scp ~/.ssh/id_rsa.pub root@Slave1:/home/hadoop/
//将Master节点上公钥传输到各个从节点
scp ~/.ssh/id_rsa.pub root@Slave2:/home/hadoop/

(3)在各个从节点上将ssh公钥加入授权
cd /home/hadoop //若不存在该文件夹则执行mkdir ~/.ssh
cat /home/hadoop/id_rsa.pub >> ~/.ssh/authorized_keys
各节点需输入ssh Master或者ssh Slave1,2等重新创建(yes即可)
(4)验证
在Master节点上分别输入ssh Slave1,之后输入ssh Slave2若成功则应为

即root用户后面主机名随之变化为从节点主机名
然后exit退出即可
3.配置变量
由于已经在单机版中配置过,所以直接跳过即可
4.修改配置文件
首先cd /usr/local/hadoop/etc/hadoop
ls 需要修改的文件名均可看到
修改文件都用gedit操作比vi更可见 修改完之后保存关闭(保存需要几秒钟)
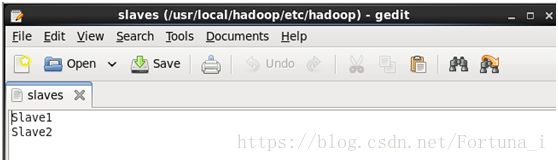
(1)修改文件slaves文件
内容写从节点主机名,一行一个
(2)修改core-site.xml文件
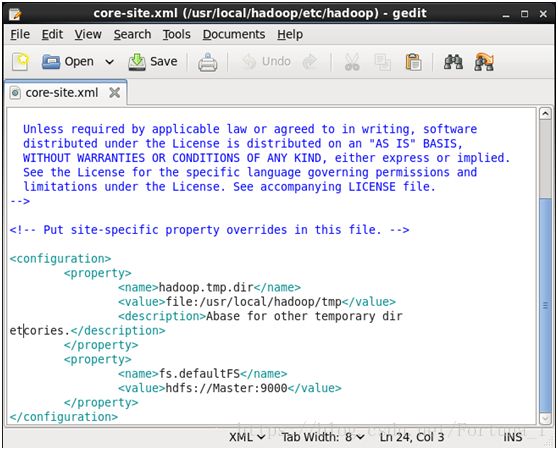
(3)修改hdfs-site.xml.文件
同样在configuration内添加如下代码
注:dfs.replication下value值为节点个数(包含主节点namenode在内),一般设置为3

(4)修改mapred-site.xml文件
configuration内添加如下代码

(5)修改yarn-site.xml文件
configuration内添加如下代码

5.复制hadoop文件到各个节点
Master节点操作:
cd /usr/local/hadoop
rm -rf tmp //删除缓存文件
rm -rf logs/* //删除日志
tar -zcf ~/hadoop.master.tar.gz ./hadoop //先压缩后复制
cd ~ //应该是为了压缩后重新进入,也可以ls
scp hadoop.master.tar.gz Slave1:/home/hadoop
Slave各节点操作:
cd /usr/local/hadoop 最好ls一下看内容
rm -r /usr/local/hadoop //删除以前的hadoop 若无此文件夹可跳过 cd /home/hadoop //可看到压缩包
tar -zxf hadoop.master.tar.gz -C /usr/local //解压
chmod -R 777 /usr/local/hadoop
(图就先不传了,可以跳转到目录然后ls查看各个操作是否执行)
6.格式化并启动
可先将hadoop内的tmp和logs删掉
rm -rf /usr/local/hadoop/tmp/*
rm -rf /usr/local/hadoop/logs/*
然后hdfs namenode -format //格式化hdfs

注:status 为0则执行成功,为1则执行失败
启动hadoop
跳转到执行目录cd /usr/local/hadoop/sbin
start-dfs.sh运行如下图
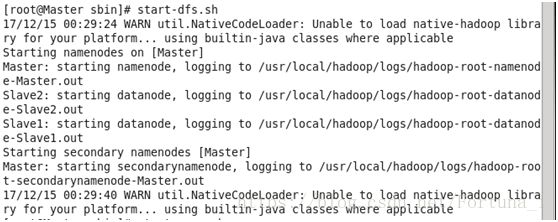
start-yarn.sh运行如下图

mr-jobhistory-daemon.sh start historyserver //启动historyserver进程
所有步骤完成结果应为
Master节点上输入jps

Slave1节点上输入jps

Slave2节点上输入jps

重要:无论出现何种问题,查看日志,执行验证,判断问题出现原因及处理方法才是关键!
