Hadoop集群环境搭建
文章目录
- 1、环境介绍
- 2、centos安装
- 2.1、集群规划
- 2.2、设置IP和Mac地址
- 2.3、关闭防火墙
- 2.4、关闭selinux
- 2.5、SSH免密登录
- 2.5.1、三台机器生成公钥与私钥
- 2.5.2、拷贝公钥到第一台服务器
- 2.5.3、复制第一台的认证到其他机器
- 2.5.4、验证是否成功
- 2.6、三台机器时钟同步
- 3、JDK安装
- 4、Zookeeper安装
- 4.1、集群规划
- 4.2、上传安装包
- 4.3、解压安装包
- 4.4、修改配置
- 4.5、设置机器id
- 4.6、安装包分发
- 4.7、修改机器id值
- 4.8、启动Zookeeper
- 5、Hadoop安装
- 5.1、集群规划
- 5.2、上传安装包并解压
- 5.3、 修改配置文件
- 5.3.1、core-site.xml
- 5.3.2、hadoop-env.sh
- 5.3.3、hdfs-site.xml
- 5.3.4、mapred-site.xml
- 5.3.5、yarn-site.xml
- 5.3.6、worker
- 5.4、创建数据和临时文件夹
- 5.5、分发安装包
- 5.6、在每个节点配置环境变量
- 5.7、格式化HDFS
- 5.8、启动集群
- 5.9、访问Hadoop
1、环境介绍
搭建Hadoop集群,由于考虑到电脑性能问题(只有8G内存),故选择使用VMWare虚拟机搭建三台服务器,每台服务器各有一台Hadoop。考虑到性能问题,学习阶段,选择了Hadoop 2.x的架构,HDFS和MapReduce均非高可用(HA)。
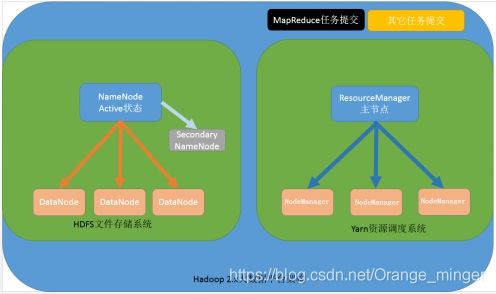
故前期需要搭建的环境包括centos服务器、zookeeper、JDK8、Hadoop。
2、centos安装
这里选择安装centos无界面版,直接使用之前安装过的(需要的可以私我),复制两份即可。每一台分配2G内存和40G的硬盘,网络使用NAT模式。
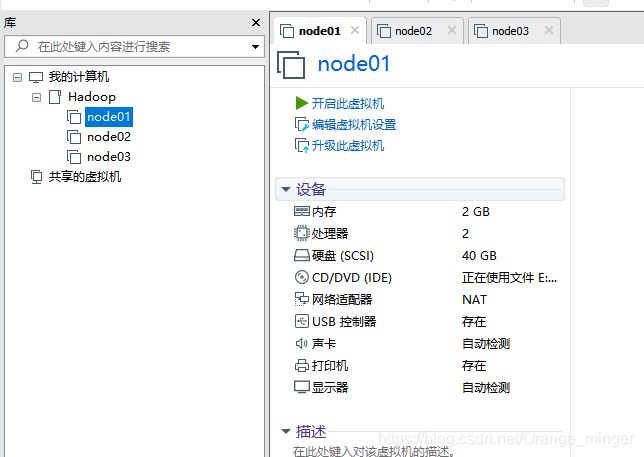
2.1、集群规划
| IP | 主机名 | 环境配置 | 安装 |
|---|---|---|---|
| 192.168.138.100 | node01 | 关防火墙和selinux, host映射, 时钟同步 | JDK, NameNode, DataNode,ResourceManager, Zookeeper |
| 192.168.138.110 | node02 | 关防火墙和selinux, host映射, 时钟同步 | JDK, DataNode, NodeManager, Zeekeeper |
| 192.168.138.120 | node03 | 关防火墙和selinux, host映射, 时钟同步 | JDK, DataNode, NodeManager, Zeekeeper |
2.2、设置IP和Mac地址
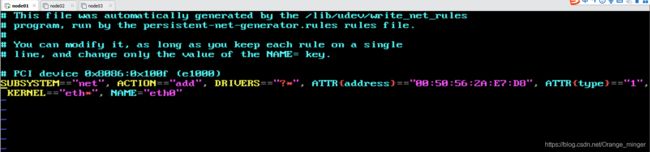
三台服务器除了IP、Mac地址和主机名不同,其他都一样,下面列出第一台服务器的情况。
更改mac地址:vim /etc/udev/rules.d/70-persistent-net.rules
结果如下:
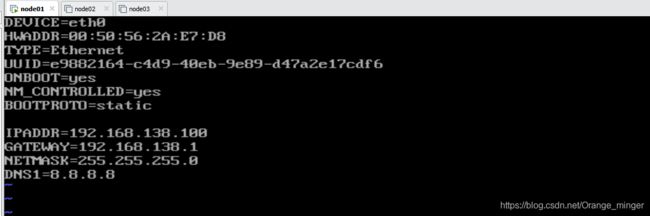
更改IP地址: vim /etc/sysconfig/network-scripts/ifcfg-eth0
结果如下:
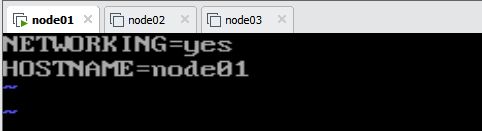
修改主机名: vim /ect/sysconfig/network
结果如下:
设置IP和域名映射(三台服务器均一致): vim /etc/hosts
结果如下:

重启使生效:reboot
2.3、关闭防火墙
三台服务器执行以下命令:
service iptables stop #关闭防火墙
chkconfig iptables off #禁止开机启动
2.4、关闭selinux
- 什么是SELinux
- SELinux是Linux的一种安全子系统
- Linux中的权限管理是针对于文件的, 而不是针对进程的
- SELinux在Linux的文件权限之外, 增加了对进程的限制, 进程只能在进程允许的范围内操作资源
- SELinux的工作模式
enforcing强制模式permissive宽容模式disable关闭
修改selinux的配置文件:vim /etc/selinux/config
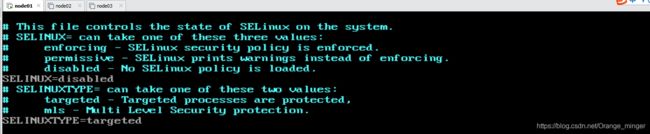
2.5、SSH免密登录
为什么要免密登录?
Hadoop集群节点众多, 所以一般在主节点启动从节点, 这个时候就需要程序自动在主节点登录到从节点中, 如果不能免密就每次都要输入密码, 非常麻烦!
2.5.1、三台机器生成公钥与私钥
在三台机器执行以下命令,生成公钥与私钥:ssh-keygen -t rsa
执行该命令之后,按下三个回车即可
2.5.2、拷贝公钥到第一台服务器
三台机器执行命令:ssh-copy-id node01
2.5.3、复制第一台的认证到其他机器
在第一台服务器上面执行以下命令:
scp /root/.ssh/authorized_keys node02:/root/.ssh
scp /root/.ssh/authorized_keys node03:/root/.ssh
2.5.4、验证是否成功
从第一台服务器登录第二台服务器:ssh node02

退出登录其他服务器:exit
2.6、三台机器时钟同步
为什么需要时间同步?
因为很多分布式系统是有状态的, 比如说存储一个数据, A节点记录的时间是xxx, B节点记录的时间是yyy, 就会出问题!
## 安装
yum install -y ntp
## 启动定时任务
crontab -e
## 输入
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
## 退出
esc
:wq
至此,centos的安装和配置完成!!
3、JDK安装
-
查看自带的JDK:
rpm -qa | grep java -
卸载系统自带的JDK
-
创建目录:后期所以软件均存放在这个目录:
mkdir -p /export/servers -
创建目录:后期所有软件压缩包均存放在这个目录:
mkdir -p /export/softwares -
上传JDK到/export/softwares路径下去,并解压:
tar -zxvf jdk-8u141-linux-x64.tar.gz -C ../servers/
- 配置环境变量:
vim /etc/profile,添加下面的配置:
export JAVA_HOME=/export/servers/jdk1.8.0_141
export PATH=:$JAVA_HOME/bin:$PATH
-
使配置生效:
source /etc/profile -
验证是否成功:
java -version
4、Zookeeper安装
4.1、集群规划
| 服务器IP | 主机名 | myid的值 |
|---|---|---|
| 192.168.174.100 | node01 | 1 |
| 192.168.174.110 | node02 | 2 |
| 192.168.174.120 | node03 | 3 |
4.2、上传安装包
从官网http://archive.apache.org/dist/zookeeper/下载安装包,然后上传到linux的/export/softwares路径下。4.3-4.5的操作只需要在第一台机器执行即可,然后4.6复制到第二台机器和第三台机器。
4.3、解压安装包
解压zookeeper的压缩包到/export/servers路径
cd /export/software
tar -zxvf zookeeper-3.4.9.tar.gz -C ../servers/
4.4、修改配置
复制配置文件:
cd /export/servers/zookeeper-3.4.9/conf/
cp zoo_sample.cfg zoo.cfg
mkdir -p /export/servers/zookeeper-3.4.9/zkdatas/
修改配置文件:vim zoo.cfg,并添加如下配置:
dataDir=/export/servers/zookeeper-3.4.9/zkdatas
# 保留多少个快照
autopurge.snapRetainCount=3
# 日志多少小时清理一次
autopurge.purgeInterval=1
# 集群中服务器地址
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
4.5、设置机器id
在第一台机器的/export/servers/zookeeper-3.4.9/zkdatas /这个路径下创建一个文件,文件名为myid ,文件内容为1:
echo 1 > /export/servers/zookeeper-3.4.9/zkdatas/myid
4.6、安装包分发
将安装包分发到其他两台服务器,在第一台机器上面执行以下两个命令:
scp -r /export/servers/zookeeper-3.4.9/ node02:/export/servers/
scp -r /export/servers/zookeeper-3.4.9/ node03:/export/servers/
4.7、修改机器id值
第二台机器上修改myid的值为2:echo 2 > /export/servers/zookeeper-3.4.9/zkdatas/myid
第三台机器上修改myid的值为3:echo 3 > /export/servers/zookeeper-3.4.9/zkdatas/myid
4.8、启动Zookeeper
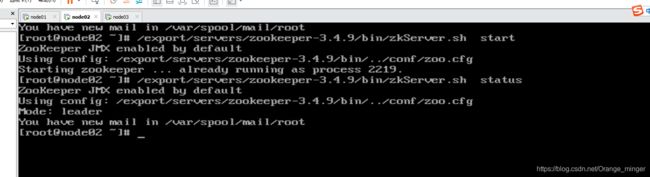
三台服务器分别执行:/export/servers/zookeeper-3.4.9/bin/zkServer.sh start
查看启动状态:/export/servers/zookeeper-3.4.9/bin/zkServer.sh status
结果如下:
5、Hadoop安装
5.1、集群规划
| 服务器IP | 192.168.174.100 | 192.168.174.110 | 192.168.174.120 |
|---|---|---|---|
| 主机名 | node01 | node02 | node03 |
| NameNode | 是 | 否 | 否 |
| SecondaryNameNode | 是 | 否 | 否 |
| dataNode | 是 | 是 | 是 |
| ResourceManager | 是 | 否 | 否 |
| NodeManager | 是 | 是 | 是 |
5.2、上传安装包并解压
- 上传压缩包到/export/software目录
cd /export/softwaretar xzvf hadoop-3.1.1.tar.gz -C ../servers
5.3、 修改配置文件
配置文件总共需要配置6个,位置均在 hadoop/etc/hadoop目录下
5.3.1、core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://node01:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/export/servers/hadoop-3.1.1/datas/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>8192value>
property>
<property>
<name>fs.trash.intervalname>
<value>10080value>
property>
configuration>
5.3.2、hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
5.3.3、hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///export/servers/hadoop-3.1.1/datas/namenode/namenodedatasvalue>
property>
<property>
<name>dfs.blocksizename>
<value>134217728value>
property>
<property>
<name>dfs.namenode.handler.countname>
<value>10value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///export/servers/hadoop-3.1.1/datas/datanode/datanodeDatasvalue>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>node01:50070value>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
<property>
<name>dfs.namenode.checkpoint.edits.dirname>
<value>file:///export/servers/hadoop-3.1.1/datas/dfs/nn/snn/editsvalue>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node01.hadoop.com:50090value>
property>
<property>
<name>dfs.namenode.edits.dirname>
<value>file:///export/servers/hadoop-3.1.1/datas/dfs/nn/editsvalue>
property>
<property>
<name>dfs.namenode.checkpoint.dirname>
<value>file:///export/servers/hadoop-3.1.1/datas/dfs/snn/namevalue>
property>
configuration>
5.3.4、mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.map.memory.mbname>
<value>1024value>
property>
<property>
<name>mapreduce.map.java.optsname>
<value>-Xmx512Mvalue>
property>
<property>
<name>mapreduce.reduce.memory.mbname>
<value>1024value>
property>
<property>
<name>mapreduce.reduce.java.optsname>
<value>-Xmx512Mvalue>
property>
<property>
<name>mapreduce.task.io.sort.mbname>
<value>256value>
property>
<property>
<name>mapreduce.task.io.sort.factorname>
<value>100value>
property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopiesname>
<value>25value>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node01.hadoop.com:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node01.hadoop.com:19888value>
property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dirname>
<value>/export/servers/hadoop-3.1.1/datas/jobhsitory/intermediateDoneDatasvalue>
property>
<property>
<name>mapreduce.jobhistory.done-dirname>
<value>/export/servers/hadoop-3.1.1/datas/jobhsitory/DoneDatasvalue>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.1.1value>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.1.1/value>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.1.1value>
property>
configuration>
5.3.5、yarn-site.xml
<configuration>
<property>
<name>dfs.namenode.handler.countname>
<value>100value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>node01:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>node01:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>node01:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>node01:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>node01:8088value>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>node01value>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>1024value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>2048value>
property>
<property>
<name>yarn.nodemanager.vmem-pmem-rationame>
<value>2.1value>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>1024value>
property>
<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilitiesname>
<value>truevalue>
property>
<property>
<name>yarn.nodemanager.local-dirsname>
<value>file:///export/servers/hadoop-3.1.1/datas/nodemanager/nodemanagerDatasvalue>
property>
<property>
<name>yarn.nodemanager.log-dirsname>
<value>file:///export/servers/hadoop-3.1.1/datas/nodemanager/nodemanagerLogsvalue>
property>
<property>
<name>yarn.nodemanager.log.retain-secondsname>
<value>10800value>
property>
<property>
<name>yarn.nodemanager.remote-app-log-dirname>
<value>/export/servers/hadoop-3.1.1/datas/remoteAppLog/remoteAppLogsvalue>
property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffixname>
<value>logsvalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>18144000value>
property>
<property>
<name>yarn.log-aggregation.retain-check-interval-secondsname>
<value>86400value>
property>
<property>
<name>yarn.app.mapreduce.am.resource.mbname>
<value>1024value>
property>
configuration>
5.3.6、worker
node01
node02
node03
5.4、创建数据和临时文件夹
mkdir -p /export/servers/hadoop-3.1.1/datas/tmp
mkdir -p /export/servers/hadoop-3.1.1/datas/dfs/nn/snn/edits
mkdir -p /export/servers/hadoop-3.1.1/datas/namenode/namenodedatas
mkdir -p /export/servers/hadoop-3.1.1/datas/datanode/datanodeDatas
mkdir -p /export/servers/hadoop-3.1.1/datas/dfs/nn/edits
mkdir -p /export/servers/hadoop-3.1.1/datas/dfs/snn/name
mkdir -p /export/servers/hadoop-3.1.1/datas/jobhsitory/intermediateDoneDatas
mkdir -p /export/servers/hadoop-3.1.1/datas/jobhsitory/DoneDatas
mkdir -p /export/servers/hadoop-3.1.1/datas/nodemanager/nodemanagerDatas
mkdir -p /export/servers/hadoop-3.1.1/datas/nodemanager/nodemanagerLogs
mkdir -p /export/servers/hadoop-3.1.1/datas/remoteAppLog/remoteAppLogs
5.5、分发安装包
cd /export/servers
scp -r hadoop-3.1.1/ node02:$PWD
scp -r hadoop-3.1.1/ node03:$PWD
5.6、在每个节点配置环境变量
vim /etc/profile
export HADOOP_HOME=/export/servers/hadoop-3.1.1/
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
5.7、格式化HDFS
cd /export/servers/hadoop-3.1.1/
bin/hdfs namenode -format
5.8、启动集群
/export/servers/hadoop-3.1.1/sbin/start-dfs.sh
/export/servers/hadoop-3.1.1/sbin/start-yarn.sh
5.9、访问Hadoop
- HDFS:
http://192.168.138.100:50070 - Yarn:
http://192.168.138.100:8088
结果如下:

