Hadoop基础知识
Hadoop基础知识
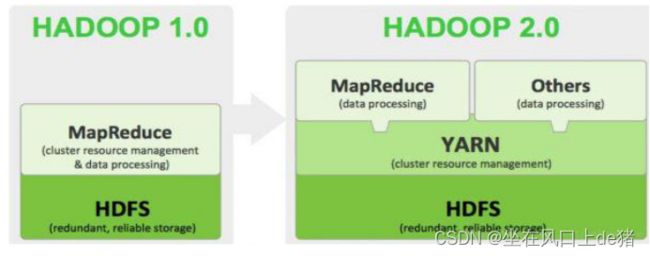
1、Hadoop简介
- 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
- 狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
- HDFS(分布式文件系统):解决海量数据存储
- YARN(作业调度和集群资源管理的框架):解决资源任务调度
- MAPREDUCE(分布式运算编程框架):解决海量数据计算
2、Hadoop特性优点
- 扩容能力(Scalable):Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
- 成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
- 高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
- 可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
3、hadoop集群中hadoop都需要启动哪些进程,他们的作用分别是什么?
- namenode =>HDFS的守护进程,负责维护整个文件系统,存储着整个文件系统的元数据信息,fsimage+edit log
- fsimage保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。
- editlog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。
- datanode =>是具体文件系统的工作节点,当我们需要某个数据,namenode告诉我们去哪里找,就直接和那个DataNode对应的服务器的后台进程进行通信,由DataNode进行数据的检索,然后进行具体的读/写操作
- secondarynamenode =>一个守护进程,相当于一个namenode的元数据的备份机制,定期的更新,和namenode进行通信,将namenode上的image和edits进行合并,可以作为namenode的备份使用
- 触发checkpoint需要满足两个条件中的任意一个,定时时间到和edits中数据写满了:
- 每隔一小时执行一次;
- 一分钟检查一次操作次数,当操作次数达到1百万时
- 触发checkpoint需要满足两个条件中的任意一个,定时时间到和edits中数据写满了:
- resourcemanager =>是yarn平台的守护进程,负责所有资源的分配与调度,client的请求由此负责,监控nodemanager
- nodemanager => 是单个节点的资源管理,执行来自resourcemanager的具体任务和命令
- DFSZKFailoverController高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态。FC也有选择谁作为Active NN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换)。
- 7)JournalNode 高可用情况下存放namenode的editlog文件
4、Hadoop主要的配置文件
-
hadoop-env.sh
- 文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
-
core-site.xml
-
设置Hadoop的文件系统地址
<property> <name>fs.defaultFSname> <value>hdfs://node-1:9000value> property>
-
-
hdfs-site.xml
-
指定HDFS副本的数量
-
secondary namenode 所在主机的ip和端口
<property> <name>dfs.replicationname> <value>2value> property> <property> <name>dfs.namenode.secondary.http-addressname> <value>node-2:50090value> property>
-
-
mapred-site.xml
-
指定mr运行时框架,这里指定在yarn上,默认是local
<property> <name>mapreduce.framework.namename> <value>yarnvalue> property>
-
-
yarn-site.xml
-
指定YARN的主角色(ResourceManager)的地址
<property> <name>yarn.resourcemanager.hostnamename> <value>node-1value> property>
-
5、Hadoop集群重要命令
-
初始化
- hadoop namenode –format
-
启动dfs
- start-dfs.sh
-
启动yarn
- start-yarn.sh
-
启动任务历史服务器
- mr-jobhistory-daemon.sh start historyserver
- 默认端口:19888
-
一键启动
- start-all.sh
-
启动成功后:
- NameNode http://nn_host:port/ 默认50070.
- ResourceManagerhttp://rm_host:port/ 默认 8088


- NameNode http://nn_host:port/ 默认50070.
| 选项名称 | 使用格式 | 含义 |
|---|---|---|
| -ls | -ls <路径> | 查看指定路径的当前目录结构 |
| -lsr | -lsr <路径> | 递归查看指定路径的目录结构 |
| -du | -du <路径> | 统计目录下个文件大小 |
| -dus | -dus <路径> | 汇总统计目录下文件(夹)大小 |
| -count | -count [-q] <路径> | 统计文件(夹)数量 |
| -mv | -mv <源路径> <目的路径> | 移动 |
| -cp | -cp <源路径> <目的路径> | 复制 |
| -rm | -rm [-skipTrash] <路径> | 删除文件/空白文件夹 |
| -rmr | -rmr [-skipTrash] <路径> | 递归删除 |
| -put | -put <多个linux上的文件> |
上传文件 |
| -copyFromLocal | -copyFromLocal <多个linux上的文件> |
从本地复制 |
| -moveFromLocal | -moveFromLocal <多个linux上的文件> |
从本地移动 |
| -getmerge | -getmerge <源路径> |
合并到本地 |
| -cat | -cat |
查看文件内容 |
| -text | -text |
查看文件内容 |
| -copyToLocal | -copyToLocal [-ignoreCrc][-crc] [hdfs源路径][linux目的路径] | 从本地复制 |
| -moveToLocal | -moveToLocal [-crc] |
从本地移动 |
| -mkdir | -mkdir |
创建空白文件夹 |
| -setrep | -setrep [-R][-w] <副本数> <路径> | 修改副本数量 |
| -touchz | -touchz <文件路径> | 创建空白文件 |
| -stat | -stat [format] <路径> | 显示文件统计信息 |
| -tail | -tail [-f] <文件> | 查看文件尾部信息 |
| -chmod | -chmod [-R] <权限模式> [路径] | 修改权限 |
| -chown | -chown [-R][属主][:[属组]] 路径 | 修改属主 |
| -chgrp | -chgrp [-R] 属组名称 路径 | 修改属组 |
| -help | -help [命令选项] | 帮助 |
6、HDFS的垃圾桶机制
-
修改core-site.xml
<property> <name>fs.trash.intervalname> <value>1440value> property> -
这个时间以分钟为单位,例如1440=24h=1天。HDFS的垃圾回收的默认配置属性为 0,也就是说,如果你不小心误删除了某样东西,那么这个操作是不可恢复的。
7、HDFS写数据流程
HDFS dfs -put a.txt /

详细步骤:
-
1)客户端通过Distributed FileSystem模块向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
-
client和namenode之间是通过RPC通信; datanode和namenode之间是通过RPC通信; client和datanode之间是通过简单的Socket通信;
-
-
2)namenode返回是否可以上传。
-
3)客户端请求第一个 block上传到哪几个datanode服务器上。
-
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
-
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。(RPC通信)
-
6)dn1、dn2、dn3逐级应答客户端。
-
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(大小为64k),dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
-
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。
8、Hadoop读数据流程
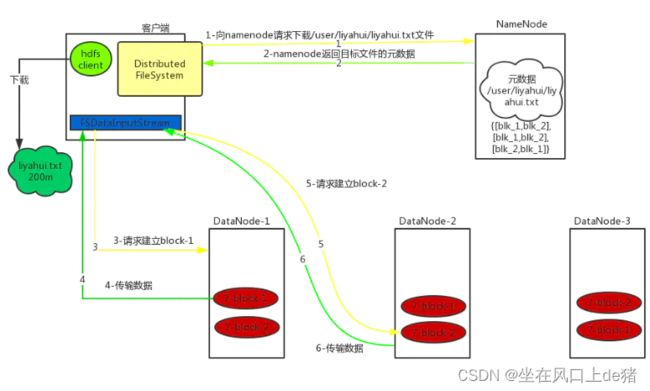
详细步骤:
- 1)客户端通过Distributed FileSystem向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
- 2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
- 3)datanode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验,大小为64k)。
- 4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
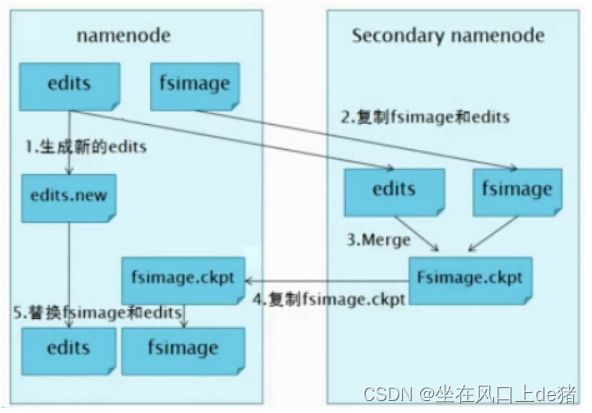
9、SecondaryNameNode的作用
NameNode职责是管理元数据信息,DataNode的职责是负责数据具体存储,那么SecondaryNameNode的作用是什么?
答:它的职责是合并NameNode的edit logs到fsimage文件。
每达到触发条件 [达到一个小时,或者事务数达到100万],会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint),如下图所示:
10、HDFS的扩容、缩容
10.1.动态扩容
随着公司业务的增长,数据量越来越大,原有的datanode节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。也就是俗称的动态扩容。
有时候旧的服务器需要进行退役更换,暂停服务,可能就需要在当下的集群中停止某些机器上hadoop的服务,俗称动态缩容。
10.1.1. 基础准备
在基础准备部分,主要是设置hadoop运行的系统环境
修改新机器系统hostname(通过/etc/sysconfig/network进行修改)

修改hosts文件,将集群所有节点hosts配置进去(集群所有节点保持hosts文件统一)

设置NameNode到DataNode的免密码登录(ssh-copy-id命令实现)
修改主节点slaves文件,添加新增节点的ip信息(集群重启时配合一键启动脚本使用)

在新的机器上上传解压一个新的hadoop安装包,从主节点机器上将hadoop的所有配置文件,scp到新的节点上。
10.1.2. 添加datanode
- 在namenode所在的机器的
/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop目录下创建dfs.hosts文件
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim dfs.hosts
添加如下主机名称(包含新服役的节点)
node-1
node-2
node-3
node-4
- 在namenode机器的hdfs-site.xml配置文件中增加dfs.hosts属性
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
<property>
<name>dfs.hostsname>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hostsvalue>
property>
dfs.hosts属性的意义:命名一个文件,其中包含允许连接到namenode的主机列表。必须指定文件的完整路径名。如果该值为空,则允许所有主机。相当于一个白名单,也可以不配置。
在新的机器上单独启动datanode: hadoop-daemon.sh start datanode
![]()
刷新页面就可以看到新的节点加入进来了

10.1.3.datanode负载均衡服务
新加入的节点,没有数据块的存储,使得集群整体来看负载还不均衡。因此最后还需要对hdfs负载设置均衡,因为默认的数据传输带宽比较低,可以设置为64M,即hdfs dfsadmin -setBalancerBandwidth 67108864即可
默认balancer的threshold为10%,即各个节点与集群总的存储使用率相差不超过10%,我们可将其设置为5%。然后启动Balancer,
sbin/start-balancer.sh -threshold 5,等待集群自均衡完成即可。
10.1.4.添加nodemanager
在新的机器上单独启动nodemanager:
yarn-daemon.sh start nodemanager
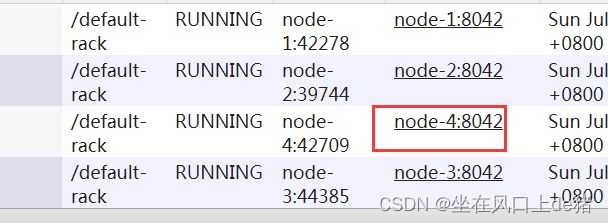
在ResourceManager,通过yarn node -list查看集群情况

10.2.动态缩容
10.2.1.添加退役节点
在namenode所在服务器的hadoop配置目录etc/hadoop下创建dfs.hosts.exclude文件,并添加需要退役的主机名称。
注意:该文件当中一定要写真正的主机名或者ip地址都行,不能写node-4
node04.hadoop.com
在namenode机器的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
<property>
<name>dfs.hosts.excludename>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts.excludevalue>
property>
dfs.hosts.exclude属性的意义:命名一个文件,其中包含不允许连接到namenode的主机列表。必须指定文件的完整路径名。如果值为空,则不排除任何主机。
10.2.2.刷新集群
在namenode所在的机器执行以下命令,刷新namenode,刷新resourceManager。
hdfs dfsadmin -refreshNodes
yarn rmadmin –refreshNodes
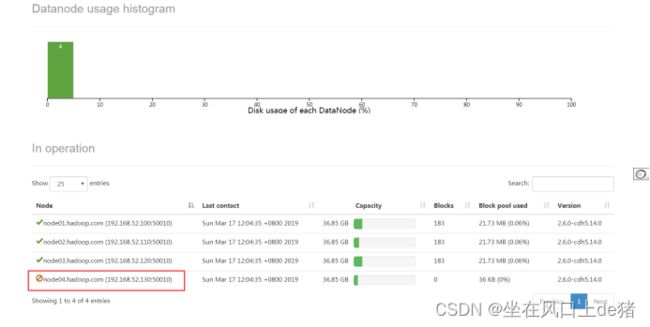
等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。
node-4执行以下命令,停止该节点进程
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/hadoop-daemon.sh stop datanode
sbin/yarn-daemon.sh stop nodemanager
namenode所在节点执行以下命令刷新namenode和resourceManager
hdfs dfsadmin –refreshNodes
yarn rmadmin –refreshNodes
namenode所在节点执行以下命令进行均衡负载
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-balancer.sh
11、HDFS安全模式
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求,是一种保护机制,用于保证集群中的数据块的安全性。
在NameNode主节点启动时,HDFS首先进入安全模式,集群会开始检查数据块的完整性。DataNode在启动的时候会向namenode汇报可用的block信息,当整个系统达到安全标准时,HDFS自动离开安全模式。
-
手动进入安全模式
hdfs dfsadmin -safemode enter -
手动离开安全模式
hdfs dfsadmin -safemode leave
12、机架感知
hadoop自身是没有机架感知能力的,必须通过人为的设定来达到这个目的。一种是通过配置一个脚本来进行映射;另一种是通过实现DNSToSwitchMapping接口的resolve()方法来完成网络位置的映射。
-
写一个脚本,然后放到hadoop的core-site.xml配置文件中,用namenode和jobtracker进行调用。
#!/usr/bin/python
#-*-coding:UTF-8 -*-
import sys
rack = {"hadoop-node-31":"rack1",
"hadoop-node-32":"rack1",
"hadoop-node-33":"rack1",
"hadoop-node-34":"rack1",
"hadoop-node-49":"rack2",
"hadoop-node-50":"rack2",
"hadoop-node-51":"rack2",
"hadoop-node-52":"rack2",
"hadoop-node-53":"rack2",
"hadoop-node-54":"rack2",
"192.168.1.31":"rack1",
"192.168.1.32":"rack1",
"192.168.1.33":"rack1",
"192.168.1.34":"rack1",
"192.168.1.49":"rack2",
"192.168.1.50":"rack2",
"192.168.1.51":"rack2",
"192.168.1.52":"rack2",
"192.168.1.53":"rack2",
"192.168.1.54":"rack2",
}
if __name__=="__main__":
print "/" + rack.get(sys.argv[1],"rack0")
-
将脚本赋予可执行权限chmod +x RackAware.py,并放到bin/目录下。
-
然后打开conf/core-site.html
<property>
<name>topology.script.file.namename>
<value>/opt/modules/hadoop/hadoop-1.0.3/bin/RackAware.pyvalue>
property>
<property>
<name>topology.script.number.argsname>
<value>20value>
property>
-
重启Hadoop集群
- namenode日志
2012-06-08 14:42:19,174 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.49:50010 storage DS-1155827498-192.168.1.49-50010-1338289368956 2012-06-08 14:42:19,204 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack2/192.168.1.49:50010 2012-06-08 14:42:19,205 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.53:50010 storage DS-1773813988-192.168.1.53-50010-1338289405131 2012-06-08 14:42:19,226 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack2/192.168.1.53:50010 2012-06-08 14:42:19,226 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.34:50010 storage DS-2024494948-127.0.0.1-50010-1338289438983 2012-06-08 14:42:19,242 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/192.168.1.34:50010 2012-06-08 14:42:19,242 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.54:50010 storage DS-767528606-192.168.1.54-50010-1338289412267 2012-06-08 14:42:49,492 INFO org.apache.hadoop.hdfs.StateChange: STATE* Network topology has 2 racks and 10 datanodes 2012-06-08 14:42:49,492 INFO org.apache.hadoop.hdfs.StateChange: STATE* UnderReplicatedBlocks has 0 blocks 2012-06-08 14:42:49,642 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: ReplicateQueue QueueProcessingStatistics: First cycle completed 0 blocks in 0 msec 2012-06-08 14:42:49,642 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: ReplicateQueue QueueProcessingStatistics: Queue flush completed 0 blocks in 0 msec processing time, 0 msec clock time, 1 cycles