大数据量联合主键的插入更新解决方案
数据量大了之后想对一张表的数据进行插入/更新就会非常慢!目前环境是一张主表数据量在一亿的样子,之前做插入更新处理是用的KETTLE抽取工具,然而这张表是四个字段的联合主键,这样判断起来效率就会非常低,现在跑任务直接会卡死不动。网上找了一些类似的解决方案:建一张新表B,跟原表A的表结构相同,把每次导入的数据全部导入B表中,然后用左外连接把重复的数据删除(DELETE FROM A WHERE A.ID IN(SELECT B.ID FROM B LEFT JOIN A ON B.ID = A.ID) ),然后执行(INSERT INTO A SELECT * FROM B),最后删除B表的数据,网上说测试发现不到一分钟就可以在一百万数据中完成十万数据的导入。这的确是一种方法,但是如果是联合主键或者主表的数据量非常大基本就废了,经测试100W的数据插入更新10W数据,更新的这张表是四个字段的联合主键,所需时间在45分钟,如果数据量继续增大,那么显然这种方式是肯定不能满足需求的。最后解决方式是通过MERGE INTO的方式解决,示例如下:
--原始表
CREATE TABLE PRODUCTS (
PRODUCT_ID VARCHAR2(50),
PRODUCT_NAME VARCHAR2(100),
category VARCHAR2(100)
);
INSERT INTO PRODUCTS VALUES ('1','空调','电器');
INSERT INTO PRODUCTS VALUES ('2','JAVA从入门到精通','书籍');
--增量表
CREATE TABLE NEWPRODUCTS (
PRODUCT_ID VARCHAR2(50),
PRODUCT_NAME VARCHAR2(100),
category VARCHAR2(100)
);
INSERT INTO NEWPRODUCTS VALUES ('1','冰箱','电器');
INSERT INTO NEWPRODUCTS VALUES ('3','C++从入门到精通','书籍');
--插入更新
MERGE INTO products p
USING newproducts np ON (p.product_id = np.product_id)
WHEN MATCHED THEN
UPDATE
SET p.product_name = np.product_name,
p.category = np.category
WHEN NOT MATCHED THEN
INSERT
VALUES (np.product_id, np.product_name, np.category);
注:该语句是DML语句,执行完之后需要进行COMMIT结束事务。
执行完这条语句后会看到以下变化:id相同的数据得到了更新,不同的数据进行了插入操作,完成了我们的需求
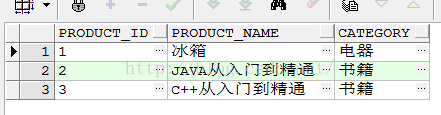
于是将这种方法运用到了真实的环境中(这张表是四个字段的联合主键,数据量在九千万)
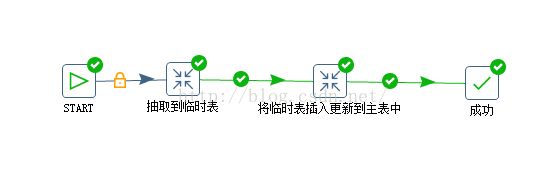
这里运用了KETTLE工具进行辅助,形成了一套完整的流程,首先会去查询原表最大的时间戳,然后将时间戳作为条件去增量数据来源表查询大于该时间的数据,即需要插入更新的数据,通过KETTLE抽取到临时表中(表结构和主表一样),抽取完之后然后通过MERGE INTO 进行插入/更新:
MERGE INTO tlgpxx_shcj_20160601 a
USING tlgp_shcj_temp b ON (a.tj_rqsj = b.tj_rqsj and a.gp_czbh = b.gp_czbh and a.gp_spck = b.gp_spck and a.gp_ph = b.gp_ph)
WHEN MATCHED THEN
UPDATE SET a.xxzx_hj = b.xxzx_hj,a.sp_rqsj = b.sp_rqsj,a.gp_lcbh = b.gp_lcbh,a.gp_cc = b.gp_cc,a.fc_rqsj = b.fc_rqsj,
a.gp_cxh = b.gp_cxh,a.gp_zwh = b.gp_zwh,a.gp_zxlx = b.gp_pw,a.gp_cfz = b.gp_cfz,a.gp_mdz = b.gp_mdz,a.gp_cz = b.gp_cz,
a.gp_zjlxmc = b.gp_zjlxmc,a.gp_gmsfhm = b.gp_gmsfhm,a.gp_xm = b.gp_xm,a.gp_xh = b.gp_xh,a.gp_gxsj = b.gp_gxsj
WHEN NOT MATCHED THEN
INSERT
VALUES (b.xxzx_hj,b.tj_rqsj,b.gp_czbh,b.gp_spck,b.gp_ph,b.sp_rqsj,b.gp_lcbh,b.gp_cc,b.fc_rqsj,b.fc_sj,b.gp_cxh,
b.gp_zwh,b.gp_zxlx,b.gp_pw,b.gp_cfz,b.gp_mdz,b.gp_cz,b.gp_zjlxmc,b.gp_gmsfhm,b.gp_xm,b.gp_xh,b.gp_gxsj,b.bzh_id);
COMMIT;
经实际环境测试九千万的数据中更新5W数据,时间在五分钟内,20W数据在30分钟内,速度比起KETTLE组件的插入/更新,效率提高了N倍
当完成了数据合并之后清空临时表数据
TRUNCATE TABLE tlgp_shcj_temp;
最后通过KETTLE JOB将这几个步骤定时执行就可以完成自动更新任务了!
更多MERGE INTO的方法请浏览:http://blog.csdn.net/shiningrunner/article/details/53463108