【图像处理】NEON编程5-向量重组
简介
在编写NEON代码时,你可以发现,在寄存器中的数据有些时候并不是跟算法要求的那种格式。你可能需要在向量中重组这些数据使得后续的计算能够自动将正确的部分加起来,或者传输到你函数中的数据是以一个奇怪的方式呈现的,然后在你使用SIMD代码时,这些数据需要被重新排序。
这种重新排序的方式叫做置换。置换指令重组从单个或者多个寄存器中选择的独立数据,并组成一个新的向量。
在我们开始前
在你开始使用这些置换指令时,考虑你是否真的需要使用它们。
置换指令类似于移动指令,特别是在使用CPU时钟周期准备数据而不是处理数据。
你的代码只有当它使用最少的周期完成一个任务时,才是速度最优的;如果需要优化,移动和置换指令通常是可以优先考虑的地方。
其他选择?
你如何避免不必要的置换?这里有一些选择:
- 重新安排你的输入数据。通过更合适的格式来存储数据,避免在加载和存储时进行置换的话,通常耗费不了什么东西。然而,改变数据结构时,需要先考虑到数据的存放位置及其它对cache性能的影响。
- 重新设计你的算法。使用类似的处理步骤,不同的算法也可能是有效的,但可以处理不同格式的数据。
- 修改之前的处理步骤。先前处理步骤中的一个微小变化,修改数据存储在内存中的方式,可能减少或者消除置换操作的需要
- 使用交错加载和存储指令。正如我们之前讨论的,加载和存储指令有交错及去交错的能力。即使这样的操作不能完全消除置换的需要,但它能够减少额外指令。
- 合并上述的方法。使用这些技术中超过一种的话,仍然可以比额外的置换指令更加高效。
如果你已经考虑了这些方面,但是没有能够把你的数据设置为正确的格式,尝试使用置换指令吧。
具体的指令
NEON提供很多置换指令,从基本的反转到任意向量重组。简单的置换指令可以通过一个指令周期执行完毕,而复杂的指令则通过很多个指令周期,并且可能需要设置额外的寄存器。正如往常的一样,基准测试并清晰描述你的代码检查处理器的参考文档获取更多的性能上的细节。
VMOV and VSWP: Move and Swap 移动及交换
VMOV和VSWP 是最简单的置换指令,复制整个寄存器的内容到另外一个寄存器,或者交换一对寄存器中的值。
尽管你可能不把它们当成置换指令,它们可以用来修改两个D寄存器(一个Q寄存器)中的值;例如 VSWP d0, d1 交换q0中的值。
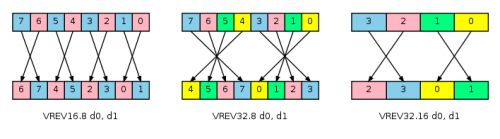
VREV: Reverse 反转
VREV 反转向量中的8,16或者32位数据,有以下三个变量:
- VREV16 反转向量中每一对能够组成16位数据的8位的数据
- VREV32 反转向量中能够组成32位数据的四个8位或者两个16位的数据
- VREV64 反转向量中8个8位,4个16位,2个32位数据。
使用VREV来反转数据的字节顺序,重组颜色分量或者交换声道数据。
VEXT: Extract 提取
VEXT 从一对已有的向量中提取出一个新的向量。新向量中的数据是从第一个操作数的头部和第二个操作数的尾部获得。这允许你从跨越两个向量的数据中创建一个新的向量
VEXT能够用来实现两个向量中的滑动窗格,在FIR滤波器中非常有用。对于置换而言,它也能够用来模拟旋转操作,当使用相同操作数的时候。

VTRN: Transpose 对换
VTRN 对换一对向量中的8,16,32bit数据。它将以下向量中的数据当做2x2矩阵,然后交换每个矩阵。
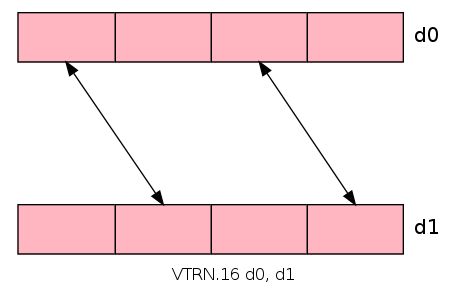
使用多个VTRN指令能够交换更大的矩阵,例如,使用三次VTRN指令,一个由16bit数据组成的4x4矩阵能够互相对换数据。

这跟VLD4 VST4的效果一样,当他们需要更少指令时,可以优先与VTRN,尝试使用内存访问的指令。
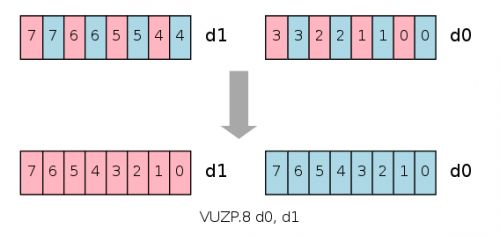
VZIP and VUZP: Zip and Unzip 压缩与解压缩
VZIP 能够让一对向量的数据( 8, 16 或者 32-bit)进行交错。这个操作与VST2一样的处理效果,因此可以优先使用VST2。

VUZP是VZIP的相反, 将交错的数据恢复原样。这个操作与VLD2类似。
VTBL, VTBX: Table and Table Extend 查表及查表扩展
VTBL 通过向量表及索引向量重组一个新的向量。它是一个字节为单位的查表操作。
向量表有1到4个相邻的D寄存器组成。索引向量中的每一个字节都可以用来索引向量表中的一个字节。根据索引向量上对应索引的位置,被索引的值会被插入到新的向量。
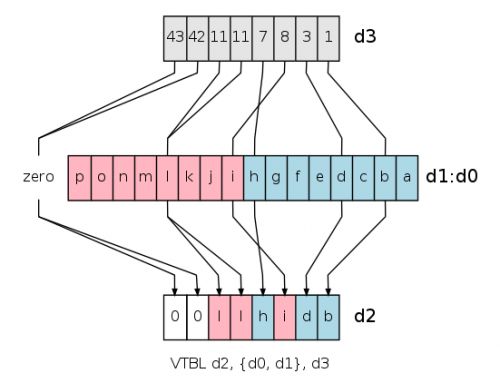
VTBL及VTBX在处理超出范围的索引时不同。如果一个索引超出向量表范围,VTBL在对应的位置上插入0。但是VTBX会保持结果向量中的值不变。
VTBL允许你实现向量的任意置换,只需要设置一个索引寄存器。如果操作是在循环中使用,置换的类型没有变化,你可以在循环外初始化索引寄存器,然后消除设置的开销。
其他
尽管还有其他方式来完成类似置换的操作,例如使用加载和存储指令来操作一个单向量数据,重复访问的内存将使得他们会变得更慢,所以这丫的方式并不推荐。
总结
仔细考虑是否真的需要置换指令是很明智的。然而,当你的算法需要它,置换指令将提供有效的方式把你的数据保存为正确的格式。