python机器学习——文本情感分析(英文文本情感分析)
本人机器学习课程的小作业,记录一下,希望可以帮到一些小伙伴。
项目介绍,给一段英文文本(英文影评评论)来预测情感是正向还是负向
模型使用的是LSTM+RNN。
代码包括数据处理,模型训练,对新数据做出预测,并将预测结果(正向情感)保存到result.txt中
软件:anaconda3
代码下载链接:下载链接
word文档(文本情感色彩分类技术报告)下载链接:下载链接
一.数据集介绍
数据集链接: https://pan.baidu.com/s/1oIXkaL_SL9GSN3S56ZwvWQ
提取码: qgtg
训练集labeledTrainData.tsv(24500条带标签的训练数据)
id sentiment review 分别表示:每段文本的唯一ID,情感色彩类别标签,待分析的文本数据。

测试集(testData.tsv:22000条无标签测试数据)
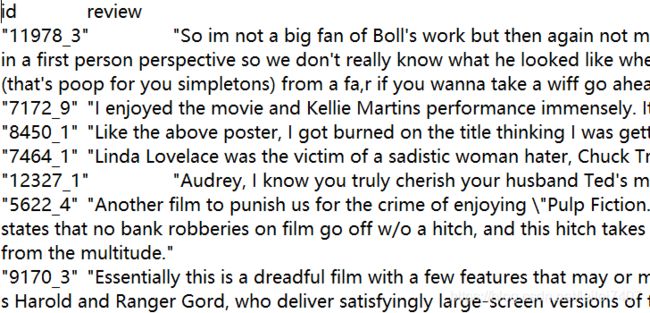
二.代码详解
import numpy as np
import tensorflow as tf
wordsList=np.load('C:/NLP/wordsList.npy') #包含40万个词的python列表
wordsList=np.load('C:/NLP/wordsList.npy') #包含40万个词的python列表
wordsList=wordsList.tolist()
wordsList=[word.decode('UTF-8') for word in wordsList]
wordVectors=np.load('C:/NLP/wordVectors.npy')
baseballIndex=wordsList.index('baseball')
print(wordVectors[baseballIndex])
import pandas as pd
#读入数据
df=pd.read_csv('C:/NLP/labeledTrainData.tsv',sep='\t',escapechar='\\')
numDimensions=300
print("down")
maxSeqLength=250
import re
strip_special_chars = re.compile("[^A-Za-z0-9 ]+")
#清洗数据,HTML字符使用空格替代
def cleanSentences(string):
string = string.lower().replace("
", " ")
return re.sub(strip_special_chars, "", string.lower())
# #生成索引矩阵,得到24500*250的索引矩阵
# ids=np.zeros((24500,maxSeqLength),dtype='int32')
# #print(ids.shape) #输出结果为(24500,250)
# fileCounter=0
# for pf in range(0,len(df)):
# #print(pf)
# indexCounter=0
# cleanedLine=cleanSentences(df['review'][pf])
# split=cleanedLine.split()
# for word in split:
# try:
# #print('111')
# ids[fileCounter][indexCounter]=wordsList.index(word)
# except ValueError:
# ids[fileCounter][indexCounter]=399999
# indexCounter=indexCounter+1
# if indexCounter>=maxSeqLength:
# break
# fileCounter=fileCounter+1
# print('down1')
# np.save('C:/NLP/idsMatrix',ids)
#上述注释后,将生成的索引矩阵保存到idsMatrix.npy文件中。避免了每次都要生成索引矩阵
ids=np.load('C:/NLP/idsMatrix.npy')
print(ids.shape)
#辅助函数
from random import randint
def getTrainBatch():
labels=[]
arr=np.zeros([batchSize,maxSeqLength])
i=0
for i in range(0,32):
j=0
while j<1:
num=randint(1,19600)
if df['sentiment'][num-1]==1:
j=j+1
labels.append([1,0])
arr[2*i]=ids[num-1:num]
j=0
while j<1:
num=randint(1,19600)
if df['sentiment'][num-1]==0:
j=j+1
labels.append([0,1])
arr[2*i+1]=ids[num-1:num]
return arr,labels
print('down')
batchSize=64 #批处理大小
lstmUnits=64 #LSTM单元个数
numClasses=2 #分类类别
iterations=50000 #训练次数
print('down')
import tensorflow as tf
tf.reset_default_graph()
labels = tf.placeholder(tf.float32, [None, numClasses])
input_data = tf.placeholder(tf.int32, [None, maxSeqLength])
data = tf.Variable(
tf.zeros([batchSize, maxSeqLength, numDimensions]), dtype=tf.float32)
data = tf.nn.embedding_lookup(wordVectors, input_data)
lstmCell = tf.contrib.rnn.BasicLSTMCell(lstmUnits)
#lstmCell = tf.contrib.rnn.LSTMCell(lstm_units)
lstmCell = tf.contrib.rnn.DropoutWrapper(cell=lstmCell, output_keep_prob=0.75)
value, _ = tf.nn.dynamic_rnn(lstmCell, data, dtype=tf.float32)
weight = tf.Variable(tf.truncated_normal([lstmUnits, numClasses]))
bias = tf.Variable(tf.constant(0.1, shape=[numClasses]))
value = tf.transpose(value, [1, 0, 2])
last = tf.gather(value, int(value.get_shape()[0]) - 1)
prediction = (tf.matmul(last, weight) + bias)
pre=tf.nn.softmax(prediction)
print(pre)
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(
logits=prediction, labels=labels))
optimizer = tf.train.AdamOptimizer().minimize(loss)
print('down')
sess=tf.InteractiveSession()
saver=tf.train.Saver()
sess.run(tf.global_variables_initializer())
for i in range(0,40001):
nextBatch,nextBatchLabels=getTrainBatch();
#print(nextBatch.shape)
#print(nextBatchLabels)
sess.run(optimizer,{input_data:nextBatch,labels:nextBatchLabels})
if(i%1000==0 and i!=0):
loss_=sess.run(loss,{input_data:nextBatch,labels:nextBatchLabels})
accuracy_=sess.run(accuracy,{input_data:nextBatch,labels:nextBatchLabels})
print("i...{}".format(i),"loss... {}".format(loss_),"accuracy {}".format(accuracy_))
if(i%10000==0 and i!=0):
save_path=saver.save(sess,"C:/NLP/models1/pretrained_lstm.ckpt",global_step=i)
print("saved to %s"%save_path)
print('down')
sess=tf.InteractiveSession()
saver=tf.train.Saver()
saver.restore(sess,"C:/NLP/models1/pretrained_lstm.ckpt-10000")
print('down')
#预测
in3 = np.load('C:/NLP/test_review.npy')
x_test=in3
print(x_test.shape)
arr=np.zeros([1,maxSeqLength])
print(arr.shape)
numpy_data=[]
sum=0
for i in range(0,2):
arr = np.array([x_test[i]])
print("result for test:",(sess.run(pre,{input_data:arr})))
numpy_data.append(sess.run(pre,{input_data:arr}))
#print("labels1:",labels1,"....result for test:",(sess.run(pre,{input_data:arr,labels:labels1})),"accuracy for test:",(sess.run(accuracy,{input_data:arr,labels:labels1})))
#sum=sum+sess.run(accuracy,{input_data:arr,labels:labels1})
#print(sum)
print('down')
result_data=[]
#print(in3.shape)
for i in range(0,22000):
arr = np.array([x_test[i]])
result_data.append(sess.run(pre,{input_data:arr}))
print('down')
f=open('C:/NLP/possubmission.txt','w')
for i in range (22000):
#print(i)
f.write('\n'+str(result_data[i][0][0]))
f.close()
print('down')
最终possubmission.txt中的内容如下(存储的是为正向情感的概率):