【论文解析】Single-Shot Bidirectional Pyramid Networks for High-Quality Object Detection
论文地址
AAAI 2018的文章,和Cascade R-CNN一样,注意到了IoU阈值的设置对目标检测的影响,但是这篇论文的网络设计比Cascade R-CNN复杂多了。
本文提出的Bidirectional Pyramid Networks(BPN)主要有两个模块:(1)a Bidirectional Feature Pyramid双向特征金字塔结构,主要是为了更有效和鲁棒的特征表示。(2)一个级联的anchor refinement来逐步地改善所预设计的anchors的质量来更有效的训练。
BPN已经在VOC和COCO超过了所有single-stage的检测器(当时)
目前来说,目标检测是基于IOU比较小的goal来实现的,如0.5的阈值(relatively low-quality precision)。但是如果训练的时候单纯的提高IoU的阈值,会导致训练时候positive training samples会变少,因为一开始训练很少有样本能够达到这个要求,从而导致过拟合,特别是像SSD这种没有proposal生成过程的one-stage算法。
本文是在SSD的基础上进行的改进。首先,目前SSD存在的两个主要问题:1.single-shot的特征表示没有足够的区分度和鲁棒性来精确定位。2.single-stage的检测框架基于预定义的anchors,显得很死板以及不精确。
一. 网络结构
动机
和R-CNN系列的two-stage检测器相比(如selective search,RPN等生成proposal),one-stage的检测器人工设计anchors,并且大多数的anchors和Ground Truth的IoU都没有0.5。这个问题在训练高IoU阈值的检测器时变得更加严峻,因为高阈值会导致positive samples数量急剧减少,从而过拟合。
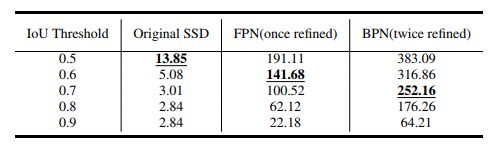
这个表表示的是不同阈值下每张图的平均anchors>阈值的数量。可以看到原始的SSD随着IoU阈值的升高positive samples的数量下降的很快。
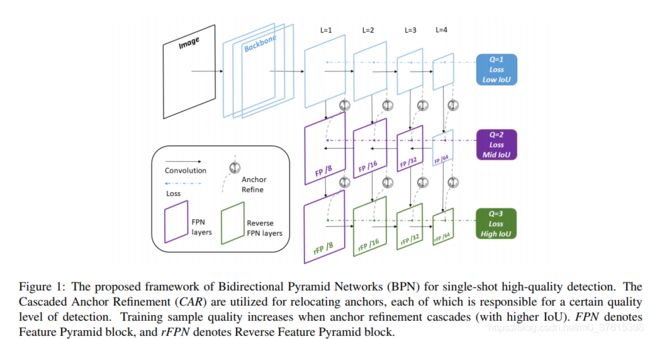
BPN的整体框架
如图1所示,BPN的BPN的backbone可以是任意的base model,论文中选择的是vgg16. 从图中可以看到,蓝色的部分和SSD类似,也是分stage,然后接着包括一个标准的类FPN结构(紫色)以及一个反向FPN结构(绿色)。这三个level的分支聚合了多level的特征来提供一个鲁棒的特征表示,同时也使得multi-quality训练和级联anchor refinement变得可行。
Cascade Anchor Refinement
级联的anchor精炼过程。我们假设用来预测的feature map的层级是L,L在论文中属于{1,2,3,4},质量的层级Q∈{1,2,3……},对应IoU(Q)∈{0.5,0.6,0.7……}。记层级L对应质量Q的feature map为FQL,anchor记为AQL。对于这个工作,我们选择了三个类型的检测器对应三个不同的质量等级:Low,Mid,High,对应的IoU阈值是0.5,0.6,0.7。为了增加positive anchors的数量并且提高他们的质量,我们定义了一个Cascaded Anchor Refinement(CAR)为CARQL。它包含两个部分:RegQL和ClsQL。对于每一个质量等级,回归器regressors接受前一级处理后的anchors来更好的优化(A1L人工定义)
A L Q = R e g Q ( A L Q − 1 ; F L Q ) , Q = 2 , 3 , … … , L = 1 , 2 , … … A^Q_L = Reg^Q(A^{Q-1}_L;F^Q_L), Q=2,3,……, L=1,2,…… ALQ=RegQ(ALQ−1;FLQ),Q=2,3,……,L=1,2,……
分类器预测类别置信度并指定给这些anchors:
C L Q = C l s Q ( F L Q ) , Q = 1 , 2 , 3 , … … , L = 1 , 2 , … … C^Q_L = Cls^Q(F^Q_L), Q=1,2,3,……, L=1,2,…… CLQ=ClsQ(FLQ),Q=1,2,3,……,L=1,2,……
training loss在质量等级Q可以表示为

(一个一个敲实在太慢,先复制一下了hh)值得注意的是,每个loss都是在一个depth下的,也就是说,这是一个level的feature map的loss。
NQ是在Q下的positive sample数量。Li是anchor在feature map L的下标,lLi是anchor Li对应的ground truth的类别,Li和gLi是ground truth的位置和大小。λ是用了平衡的超参,分类用的是softmax,回归用的是smooth L1 loss。然后总的BPN的loss为:
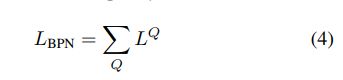
BPN结构

首先,为了解决SSD特征的弱表达问题,在SSD-style的结构中运用了FPN,使得浅层的特征也有强语义信息。但是我们发现,反方向的特征聚合也是很重要的,所以在提出的BPN中,既有FP也有反向FP。
反向FP的好处:1)对于CNN的堆叠来图像分类,反向FP用更少的卷积核来减少了浅层特征和深层特征的距离,从小保留了空间信息。2)侧连接重利用了浅层的特征来减少浅层到深层特征的信息衰减,3)我们的级联式的检测器可以自然地利用这种结构。
图2(a)是一个典型的FP结构,(b)则是一个反FP结构。公式如下:
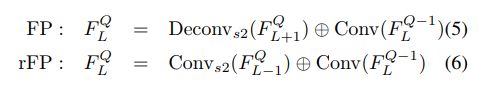
反FP和FP中相加的项都是上一级Q对应的feature map。用的融合是element-wise summation。在本论文中,FP和RFP用的是3×3的卷积核,256通道。
实现细节
在imagenet上预训练过的VGG16作为backbone,和SSD不同的是,fc6和fc7换成了conv_6和conv_7以减少参数量。
数据增强和SSD用的一样。
batchsize设置为了32,用的SGD优化器,momentum0.9,weight decay为0.005. 初始学习率0.001.(基本上都和SSD一样了)
实验结果
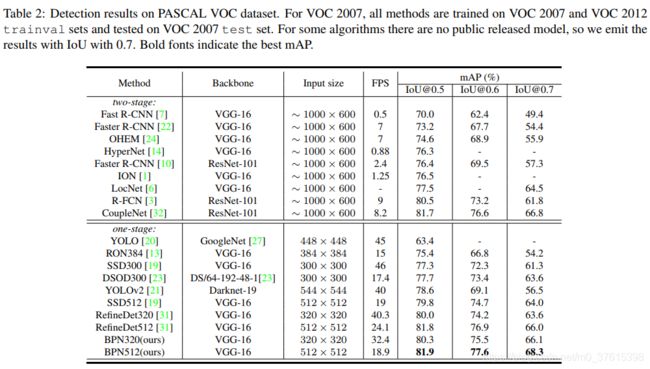
超过了所有的single-stage目标检测算法,同时FPS也没有降的很小,BPN320也有32左右。
同时作者也讨论的CAR级联level的重要性:
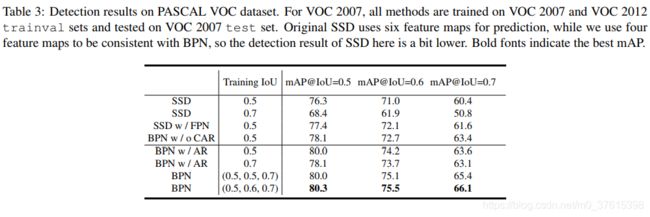
w/是with的意思,w/o是without的意思(一开始我也看不懂,后来查了才知道)。
在COCO上的测试结果:

量化与错误分析:
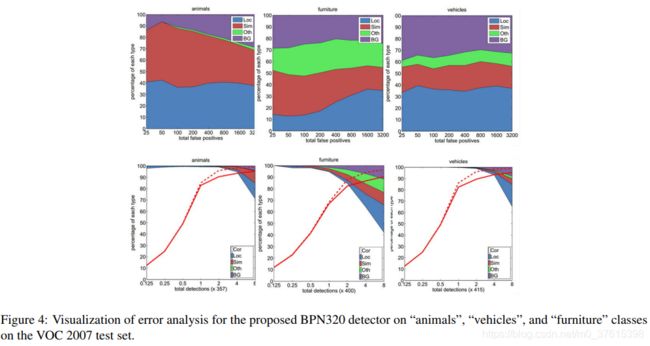
图4第一行表示了top false positive的错误率,第二行是 检测分数:correct(Cor)或different false positive types,定位issue(Loc),相似类别的混淆(Sim),和背景(BG)或是其他错误(Oth)。可以看到这个结构很好的区分了背景前景,说明特征更加鲁棒,同时级联会有更多高质量的预测。
