1. 请简述三次握手和四次挥手:
答:首先TCP是传输控制协议,提供可靠的连接服务,采用三次握手确认建立一个连接,在建立TCP连接时,需要客户端和服务器总共发送3个包。

三次握手的目的是连接服务器的指定端口、建立TCP连接、同步双方的序列号和确认号、交换TCP窗口大小信息,在socket编程中,客户端在执行connect()时将触发三次握手。
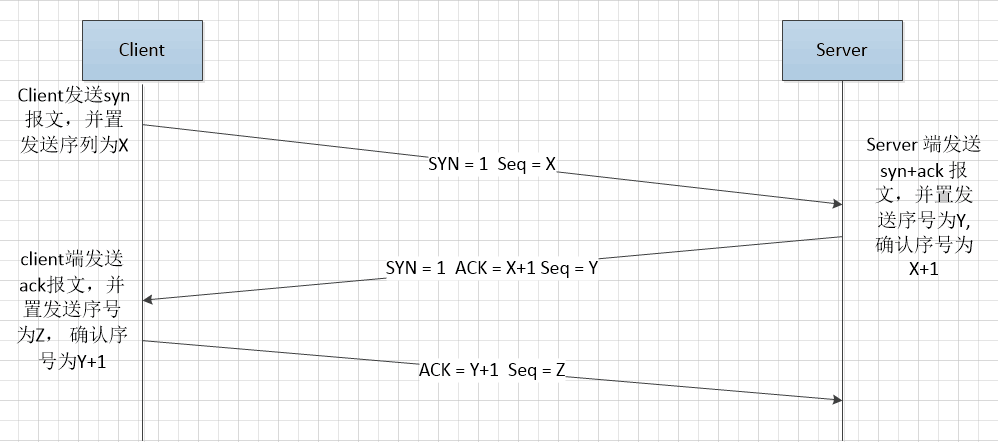
第一次握手:建立连接时,客户端发送syn包到服务器,并进入SYN_SENT状态,等待服务器确认。 SYN:同步序列编号
第二次握手:服务器收到客户端的syn包,必须向客户端发送确认信号(ack ),并且向客户端页发送一个syn包,此时服务器进入SYN_RECV状态
第三次握手:客户端收到服务器syn+ack,向服务器发送确认包ack,此包发送完毕,客户端和服务器端进入ESTABLISHED(tcp连接成功), 完成三次握手。
四次挥手: TCP连接的断开需要发送四次包,所以称之为四次挥手, 且Client端和服务器端均可主动发出断开请求,在socket中,任何一方执行close()操作皆可产收挥手操作。

·第一次挥手:Cilent端停止发送报文,并发出断开请求FIN,并将序列号置为X,此时客户端进入(终止等待1)状态。
·第二次挥手:Server端接收到FIN包后立即向Client端发送确认包ACK = X+1,并置序列号为Y,此时服务器进入关闭等待状态。
·第三次挥手:Server端在发送确认信号后也向Client端发送了关闭信号FIN和确认信号ACK,并将序列号置为Y,此时服务器进入(最后确认)状态。
·第四次挥手:Client端接收到服务器发来的断开请求报文后,必须发出确认信号ACK = Y, 并置序列号为Z+1, 并进入(时间等待)状态,且此时连接还没有断,客户端需要等待2MSL时间才会断开
2. 为什么握手三次且挥手四次?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,
所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
3. 为什么第四次握手后要等待2MSL(最大报文生存时间)时间才会返回close状态?
答:假象网络不可靠,当客户端发送ack后ack却丢失了,那么服务器端收不到确认信号,就会一直发送FIN请求,所以这时客户端不能立即关闭,必须等待2MSL时间才行(因为客户端发送ack需要MSL, 服务端发送FIN也需要MSL时间),
如果在2MSL时间内没收到服务器端发来的FIN,就代表服务器端已经接收到了客户端的ack,词汇客户端才会关闭。
4。get和post请求的区别?
答:首先定性:get和post并没有什么本质的区别。
w3schools的说法:
GET在浏览器回退时是无害的,而POST会再次提交请求
GET产生的URL地址可以被Bookmark,而POST不可以。
GET请求会被浏览器主动cache,而POST不会,除非手动设置。
GET请求只能进行url编码,而POST支持多种编码方式。
GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
GET请求在URL中传送的参数是有长度限制的,而POST么有。
对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
GET参数通过URL传递,POST放在Request body中。
然而这不是本质,本质是:
get和post是什么? 他们俩是http协议中的两种请求方式。
http是什么呢?http是基于tip/ip的关于数据如何在万维网中通信的协议
http的底层是TCP/IP,那就是说get和post底层也是TCP/IP,也就是说,get和pos请求本质都是TCP连接,get请求和post请求能做的事儿是一样的。你要给get请求加上request body,给post请求带上url参数,技术上完全行得通。
但是不同的浏览器和服务器对此做出了一些限制,如url长度不超过2k个字节等等。
不过get和post请求还是有一个重大区别的:GET产生一个TCP数据包;POST产生两个TCP数据包。
get请求会将header和data一并发过去,服务器相应200
但是post请求:浏览器先发送header, 服务器响应100 continue, 浏览器再发送data,服务器响应200.
也就是说,GET只需要汽车跑一趟就把货送到了,而POST得跑两趟,第一趟,先去和服务器打个招呼“嗨,我等下要送一批货来,你们打开门迎接我”,然后再回头把货送过去。
5. 简述python 主流web框架特性。
答:
Django:Python 界最全能的 web 开发框架,battery-include 各种功能完备,可维护性和开发速度一级棒。常有人说 Django 慢,其实主要慢在 Django ORM 与数据库的交互上,所以是否选用 Django,
取决于项目对数据库交互的要求以及各种优化。而对于 Django 的同步特性导致吞吐量小的问题,其实可以通过 Celery 等解决,倒不是一个根本问题。Django 的项目代表:Instagram,Guardian。
Tornado:天生异步,性能强悍是 Tornado 的名片,然而 Tornado 相比 Django 是较为原始的框架,诸多内容需要自己去处理。当然,随着项目越来越大,框架能够提供的功能占比越来越小,更多的内容需要团队自己实现,
而大项目往往需要性能的保证,这时候 Tornado 就是比较好的选择。Tornado项目代表:知乎。
Flask:微框架的典范,号称 Python 代码写得最好的项目之一。Flask 的灵活性,也是双刃剑:能用好 Flask 的,可以做成 Pinterest,用不好就是灾难(显然对任何框架都是这样)。
Flask 虽然是微框架,但是也可以做成规模化的 Flask。加上 Flask 可以自由选择自己的数据库交互组件(通常是 Flask-SQLAlchemy),而且加上 celery +redis 等异步特性以后,Flask 的性能相对 Tornado 也不逞多让,也许Flask 的灵活性可能是某些团队更需要的。
6. 解释GIL
答:(Global Interpreter Lock)全局解释器锁,是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅会有一个线程在执行,即使在多核处理器上,使用GIL的解释器也只允许同一时间执行一个程序,常见的使用GIL的解释器有CPython和Ruby MRI.
CPython解释器的线程使用的是操作系统的原生线程,在linux下是pthread, 在windows下是Win thread,完全由操作系统调度线程的执行。
在讨论普通的GIL之前,有一点要强调的是GIL只会影响到那些严重依赖CPU的程序(比如计算型的)。 如果你的程序大部分只会涉及到I/O,比如网络交互,那么使用多线程就很合适, 因为它们大部分时间都在等待。
实际上,你完全可以放心的创建几千个Python线程, 现代操作系统运行这么多线程没有任何压力,没啥可担心的。
Python的多线程在多核CPU上,只对于IO密集型计算产生正面效果;而当有至少有一个CPU密集型线程存在,那么多线程效率会由于GIL而大幅下降。
7. 死锁的产生、避免、解决
答:死锁的产生原因:
(1)因为系统资源不足。
(2)进程运行推进的顺序不合适。
(3)资源分配不当
如果系统自资源充足,进程的请求都可以得到满足,死锁出现的可能就会非常低,否则就会因竞争有限的资源而陷入死锁,其次,进程运行推进顺序和速度不同,也会产生死锁。
产生死锁的四个必要条件:
(1)互斥条件:一个资源每次只能被一个进程调用。
(2)请求与保持条件:一个进程因请求资源而阻塞时,对已获取的资源保持不放。
(3)不剥夺条件:进程已获取的资源,在未使用完之前,不能强制剥夺。
(4)循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
这四个是产生死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,思索就不会发生。
8。redis崩溃了怎么办?
答:首先是避免崩溃,保证redis高可用性,主从+哨兵 来避免redis全盘崩溃。
其次是redis持久化,一旦redis重启,自动从磁盘上加载数据,快速回复缓存数据。
ps: 缓存雪崩:存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,或者某一时间缓存大范围挂掉,导致请求全部转发到DB,DB瞬时压力过重宕掉。
缓存穿透:缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能DB就挂掉了
9. TCP和UDP:
答: 1.基于连接与无连接
2.TCP要求系统资源较多,UDP较少;
3.UDP程序结构较简单
4.流模式(TCP)与数据报模式(UDP);
5.TCP保证数据正确性,UDP可能丢包
6.TCP保证数据顺序,UDP不保证

10. http的长连接和短连接:
推荐这篇文章:https://www.cnblogs.com/0201zcr/p/4694945.html
答:HTTP的长连接和短连接本质上是TCP长连接和短连接。HTTP属于应用层协议,在传输层使用TCP协议,在网络层使用IP协议。IP协议主要解决网络路由和寻址问题,TCP协议主要解决如何在IP层之上可靠的传递数据包,
使在网络上的另一端收到发端发出的所有包,并且顺序与发出顺序一致。TCP有可靠,面向连接的特点。
在HTTP/1.0中,默认使用的是短连接。也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。如果客户端浏览器访问的某个HTML或其他类型的 Web页中包含有其他的Web资源,如JavaScript文件、图像文件、CSS文件等;当浏览器每遇到这样一个Web资源,就会建立一个HTTP会话。
但从 HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头有加入这行代码:Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的 TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接要客户端和服务端都支持长连接。
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。
想了解更多Python关于爬虫、数据分析的内容,获取大量爬虫爬取到的源数据,欢迎大家关注我的微信公众号:悟道Python
