PipeCNN论文详解:用OpenCL实现FPGA上的大型卷积网络加速
PipeCNN: An OpenCL-Based FPGA Accelerator for Large-Scale Convolution Neuron Networks
参考文献:
论文地址: https://arxiv.org/abs/1611.02450
代码地址: https://github.com/doonny/PipeCNN
相关论文
深鉴科技FPGA2017最佳论文ESE Efficient speech recognition engine with sparse LSTM on FPGA论文详解
PipeCNN论文详解:用OpenCL实现FPGA上的大型卷积网络加速
韩松EIE:Efficient Inference Engine on Compressed Deep Neural Network论文详解
韩松博士毕业论文Efficient methods and hardware for deep learning论文详解
目录
一、摘要:
1.1 motivation:
1.2 贡献点:
1.3 相关知识
1.3.1 OpenCL
1.3.2 GOPS
二、简介
2.1 背景
2.2 前人工作
2.3 主要贡献
三、基于OpenCL的CNN实现
3.1 OpenCL架构
3.2 本文提出的架构
3.3 Convolution Kernel
3.4 Data mover Kernels
3.4.1 在Conv模式中
3.4.2 在FC模式中
3.5 Pooling kernel
3.6 LRN kernel
四、实验
五、个人总结
一、摘要:
1.1 motivation:
- FPGA比GPU更具有可定制性和能耗低的优点
- 过去基于OpenCL的研究没有运用FPGA的并行处理的优点和最小化内存带宽的考虑
1.2 贡献点:
- 在OpenCL的基础上加入了深度的并行化(deeply pipeline),数据复用(data reuse)和任务并行化(task mapping)
- 将AlexNet和VGG在Altera Stratix-V A7的FPGA上进行验证,达到了33.9GOP的运算速率,并且比以往的工作减少了34%的DSP block
1.3 相关知识
1.3.1 OpenCL
OpenCL(全称Open Computing Language,开放运算语言)是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器。
1.3.2 GOPS
(giga operations per second 每秒十亿次运算数(10的9次方),十亿次运算/秒)衡量处理器计算能力的指标单位。现在更为常用FLOPS。
二、简介
2.1 背景
- 卷积网络(CNNs)被大量运用,但是大型的卷积网络会有million数量级的神经元和billion数量级的连接权重。
- CPU不能有效运算CNN,GPU被广泛运用但是energy inefficient.
- FPGA具有1.大量的处理单元,2.可定制的模块,3.低功耗,因此非常适合用于实现神经网络
- 传统的基于RTL(register transfer level寄存器级别)的设计流程需要编写大量的复杂的RTL代码,非常耗时并且需要仿真和汇编。
- HLS工具,High-Level synthesis高层综合能将相应的高层语言比如c/c++转成底层的RTL语言。
2.2 前人工作
2.2.1 C. Zhang, P. Li, G. Sun, Y. Guan, B. J. Xiao, and J. Cong, “Optimizing FPGA-based accelerator design for deep convolutional neural networks,”in Proc. ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA ’15), 2015.
运用vivado HLS在Xilinx VC707上实现,将相应的运算流率(Computation throughput)和内存带宽(memory bandwidth)优化到了最大。但是只是优化了卷积操作。
2.2.2 N. Suda, V. Chandra, G. Dasika, A. Mohanty, Y. F. Ma, S. Vrudhula, J. S.Seo, and Y. Cao, “Throughput-Optimized OpenCL-based FPGA accelerator for large-scale convolutional neural networks,” in Proc. ACM/SIGDA
International Symposium on Field-Programmable Gate Arrays (FPGA’16), 2016.
运用OpenCL和定点CNN(fixed-point CNN)系统化的提出了如何运用有限的资源实现最小化的执行时间。
2.3 主要贡献
2.3.1 基于OpenCL实现相应的FPGA加速。高效的架构和并行流水线(pipelined kernels)来实现大型的CNN网络
2.3.2 将AlexNet和VGG在Altera Stratix-V A7的FPGA上进行验证
2.3.3 作者在github公开了本文的代码以便他人使用。(作者在凑贡献点字数)
三、基于OpenCL的CNN实现
3.1 OpenCL架构
OpenCL是一个公开的跨平台的并行运算语言,可以用于GPU和FPGA。设计流程见Fig.1
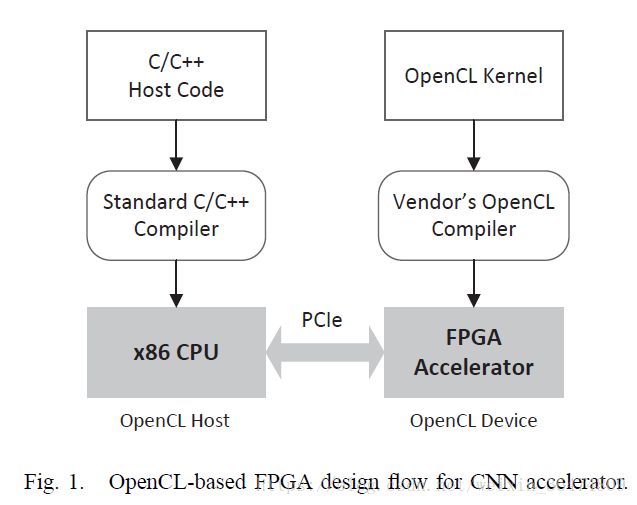
- 图中,FPGA板作为OpenCL Device,desktop CPU作为OpenCL Host,通过高速的PCIe组建了一个异源运算系统。
- OpenCL代码用内核函数(kernel function)指定了并行运算单元(CUs:computing units),被编译和综合之后用在FPGA板子上。
- 在Host中,c/c++代码会在CPU上运行,提供实现的API给FPGA板并与相应的kernels通信。(kernels为OpenCL的核函数,在xilinx上,HLS高层语义综合把相应的函数综合为IPcore,我们可以将kernels理解为IPcore)
3.2 本文提出的架构
3.2.1 典型的CNN由数个卷积层,池化层,全连接层组成。
- 典型的卷积层可以表示为:
 公式(1)
公式(1)
其中![]() 表示输入feature-map和输出feature-map中(x,y)处的神经元。
表示输入feature-map和输出feature-map中(x,y)处的神经元。![]() 代表L层中与对应输入feature-map卷积的权重
代表L层中与对应输入feature-map卷积的权重
- 池化层中,一张feature-map中相邻的神经元会进行2D下采样。
- 全连接层中,每个输出都是所有输入的加权和。
 公式(2)
公式(2)
- LRN(local response normalization)局部响应归一化层,有些CNN模型中有LRN。会对一个神经元根据其相邻的神经元值进行相应的正则化(normalization).LRN后面通常跟一个池化层。
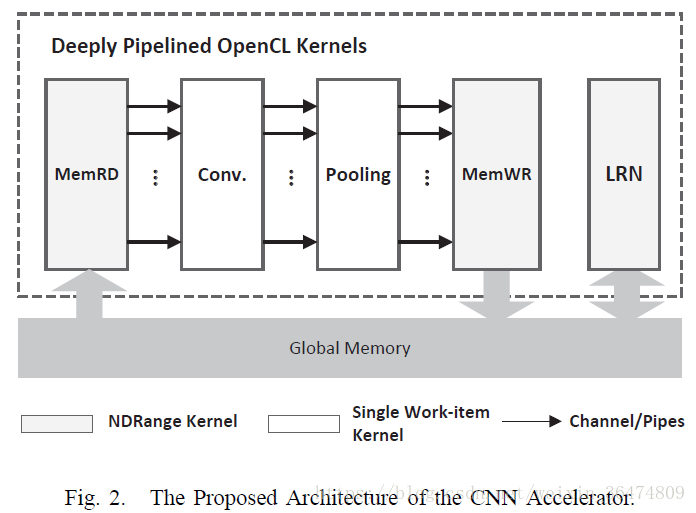
Fig.2中,四个模块运用Altera的OpenCL的channel/Pip连接起来。
图中Conv kernel既可以实现公式(1)的3D求和相加也可以实现公式(2)的内积操作。
Pooling kernel直接将conv.的输出数据流进行下采样操作。
两个数据搬运kernel,MemRD和MemWR,在global memory中运入和运出数据。
3.3 Convolution Kernel
这是一个具有并行数据传输的单进程kernel,可以用来实现卷积层和FC层。两个运算技巧被用于提升运算吞吐量和并行化处理。

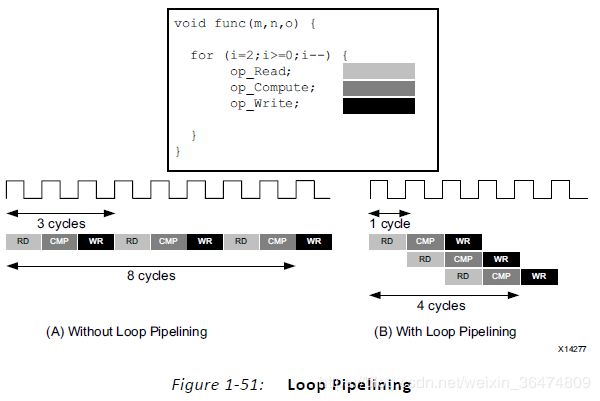
3.3.1 我们将公式(1)变为类似公式(2)的结构,然后只用函数实现一个两层嵌套的循环结构。伪码见上面fig.3,When the appropriate buffer depth N is set, an efficient pipeline with an initial interval of two can be synthesized by Altera’s OpenCL compiler.
注:上文中Initial interval经常出现,也被称为II,II到底是什么意思?我们在HLS中见到过类似,例如:
//Load input image data
for (i = 0; i < 27 * 600; i++) {
#pragma HLS PIPELINE II=1
buf_in[i] = streamPop < float, FloatAxis, FloatStream > (streamIn);
}II的含义为initiation interval。表示将循环pipeline时,两个循环初始开始的时间差。
3.3.2 data vectorization和并行化CU(compute units)
- 向量化的输入和权重
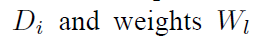 会被综合为数据流。
会被综合为数据流。 - VEC_SIZE这一参数会被引入来控制相应的输入吞吐量。
- 最外层的for循环会根据CU_NUM这一参量展开,以创建卷积流水线。
于是,输出在不同feature-map的fo中的Do会被并行的生成。
在3D卷积模式时,CN被设为K*K*C' ,在FC模式时,CN被设为C', C'=C/VEC_SIZE。当channel access不产生pipeline时,加速为VEC_SIZE*CU_NUM
3.4 Data mover Kernels
两个multi-mode的3D NDRange的kernels被设计出来用于在global memory中为运算pipeline存取数据。(multi-mode与3D NDRange为OpenCL中的概念)
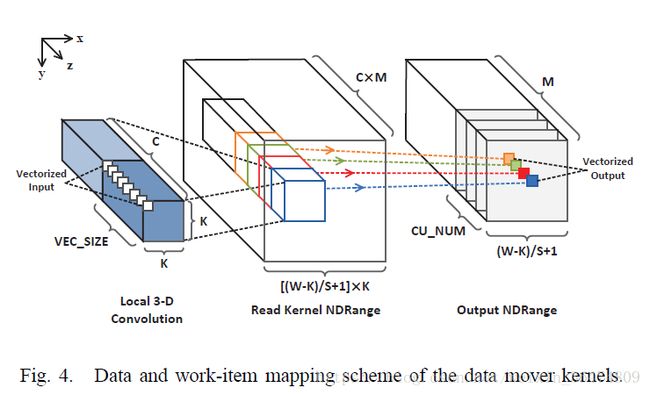
3.4.1 在Conv模式中

3.4.2 在FC模式中
输入的feature和weight都是1D的,见公式(2),直接运用MemRD会减少数据重用。所以我们在MemRD中引入batch processing。例如,一个64分类的batch可以被当作一个kernel,作为一个3D的feature-map(C,8,8)
3.5 Pooling kernel
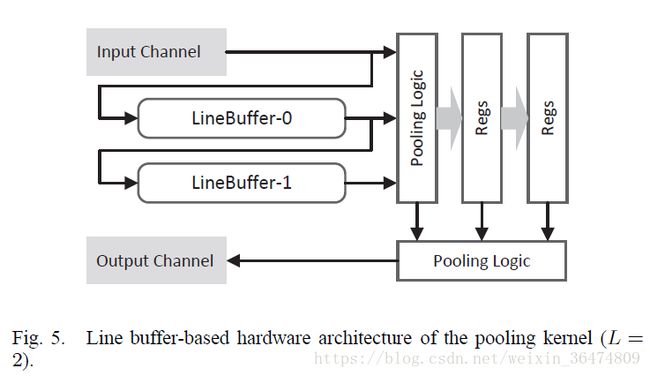
fig5为一个line buffer-based hardware architecture。kernel首先从同一张feature中逐行的read data,然后存在一组L行的buffer中。所有buffer被读满时,一个窗口的feature map数据就被读出送入下一个阶段的pooling logic中。CNN中,最大值池化和均值池化被广泛应用,所以pooling logic模型可以支持对(L+1)个输入的均值和最大值计算。kernel可以被控制寄存器关闭。
3.6 LRN kernel


四、实验
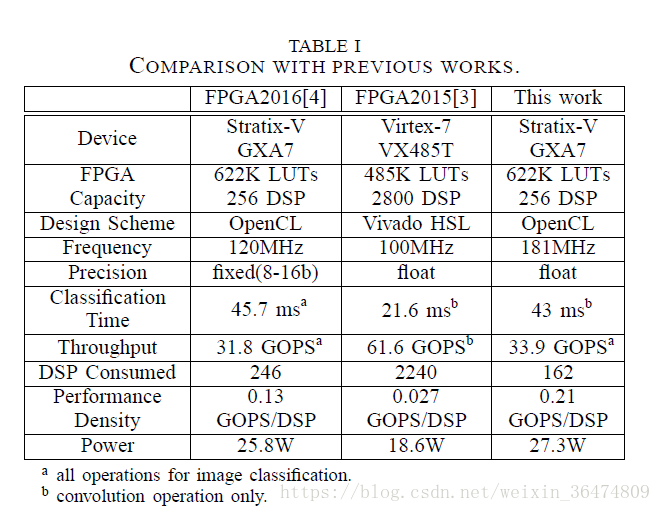
- 本文在Altera Stratix-V FPGA的DE5-net板子上进行实验。Stratix-V A7 FPGA具有622K的逻辑单元(LEs),256DSP blocks和2560 M20K RAMs,并且有两个2GB DDR3 DRAMS 被连在FPGA上当作global memory。
- OpenCL kernel codes被通过Altera OpenCL SDK v15.1编译。
- 两个大型的网络,AlexNet(8层)和VGG(16层)被用于设计。


五、个人总结
FPGA实现大型神经网络加速的方法:
- OpenCL框架
- HLS高层语义综合
- 本文提出的架构,尽量增加数据复用
- 尽量增加资源复用
更详细解析会持续补充更新,欢迎提问与批评。
相关论文
深鉴科技FPGA2017最佳论文ESE Efficient speech recognition engine with sparse LSTM on FPGA论文详解
PipeCNN论文详解:用OpenCL实现FPGA上的大型卷积网络加速
韩松EIE:Efficient Inference Engine on Compressed Deep Neural Network论文详解
韩松博士毕业论文Efficient methods and hardware for deep learning论文详解
FPGA基础知识
FPGA基础知识(一)UG998相关硬件知识
FPGA基础知识(二)HLS相关知识
FPGA基础知识(三)UG902 接口综合
FPGA基础知识(四)UG902 RTL simulation and export
FPGA基础知识(五)系统集成知识
FPGA基础知识(六)UG586 Mermoy Interface Solutions
FPGA基础知识(七)片上单片机
FPGA基础知识(八)vivado设计流程中的知识
FPGA基础知识(九)SDK相关知识
FPGA基础知识(十)DMA与AXI4总线
尝试用IPcore调用DDR3及相关知识
vivado HLS硬件化指令
vivado HLS硬件化指令(一)HLS针对循环的硬件优化
vivado HLS硬件化指令(二)HLS针对数组的硬件优化
vivado HLS硬件化指令(三)HLS增大运算吞吐量的硬件优化
vivado HLS硬件化指令(四)卷积相关的指令优化
卷积操作的HLS优化
FPGA实践教程
FPGA实践教程(一)用HLS将c程序生成IPcore
FPGA实践教程(二)连接片上ARM
FPGA实践教程(三)系统搭建与烧录
FPGA实践教程(四)片上ARM运行程序
FPGA实践教程(五)PS用MIG调用DDR
FPGA实践教程(六)AXI-Lite实现PS与PL通信
FPGA实践教程(八)PS与PL共享DDR
FPGA vivado系统集成操作
DMA在linux下PS端c语言相关内容
数据流输入输出IPcore时c语言相关内容
调通DMA系统集成中遇到的问题
ARM用MIG调用DDR3的c程序解析
MIZ7035上的AXI接口的MIG测试
MIZ7035交叉编译单片机程序运行