使用re模块定位网页信息数据位置--Python
尽管我们使用urllib.request可以获取到网页的所有数据,但是要获取我们想要的数据还需要进一步进行数据处理。本篇主要介绍如何使用python的re模块进行数据定位及获取。
1、目标网页源码观察
- 首先来到我们的目标网页:国防科技大学本科生招生信息网,观察其网页结构
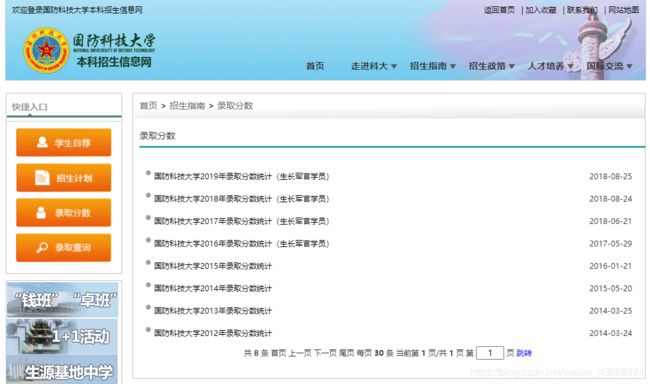
- 所谓“知己知彼,百战不殆”,我们要获取国防科技大学几年来的本科招生各地分数线信息,可以看到在当前网页中存放了近年来的录取分数统计链接。右键点击“查看网页源代码”
- 查看到的网页源代码大致如下,这同时也是我们使用urllib.request获取到的网页的全部数据

- 在网页源代码中找到我们需要的数据内容
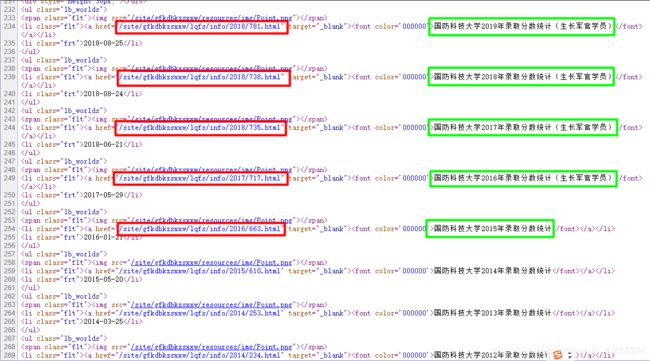
2、确定数据定位方法
- 从源代码中可以看出我们需要的今年录取分数线就在对应的文字前部分,并且可以看到所有url的存放形式都是一样的,对我们进行定位十分有帮助。
</ul>
<ul class="lb_worlds">
<span class="flt"><img src="/site/gfkdbkzsxxw/resources/img/Point.png"></span>
<li class="flt"><a href="/site/gfkdbkzsxxw/lqfs/info/2018/735.html" target="_blank"><font color='000000'>国防科技大学2017年录取分数统计(生长军官学员)</font></a></li>
<li class="frt">2018-06-21</li>
</ul>
- 根据观察我们可以看到所有的录取分数线url都是以“ 国防科技大学xxxx年录取分数统计 ”的形式出现的,并且网页中只有这一个位置出现了该信息,于是我们初步确定使用该关键字定位关键数据
- 由于所有的url标签的形式都大同小异,url在关键字定位的index前39位字符到前52位字符,因此我们可以使用find()获得关键字的位置在进一步根据位置关系获得需要的信息
ex="http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/"
index=data.find('国防科技大学'+str(i)+'年录取分数统计')
urls.append(ex+data[(index-52):(index-39)])
3、代码部分
import urllib.request as req
import re
# 录取分数网页URL
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/index.html'
webpage = req.urlopen(url) # 打开网页
data = webpage.read() # 读取网页数据
data = data.decode('utf-8') # 将byte类型的data解码为字符串
def Geturl():
# 建立空列表urls,来保存子网页的url
urls = []
ex="http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/"
# 从data中提取2016到2012每一年分数线子网站地址添加到urls列表中
for i in range(2016,2011,-1):
index=data.find('国防科技大学'+str(i)+'年录取分数统计')
urls.append(ex+data[(index-52):(index-39)])
return urls
print(Geturl())
获取结果如下,次序为:2016-2012年的录取分数统计网页url
['http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2017/717.html', 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2016/663.html', 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2015/610.html', 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2014/253.html', 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2014/234.html']
下一篇会进一步给大家介绍获取每年录取分数统计的具体情况