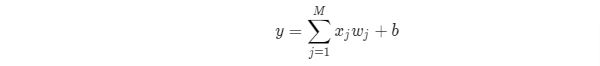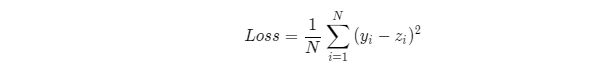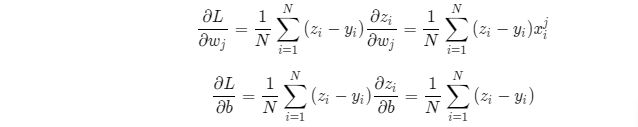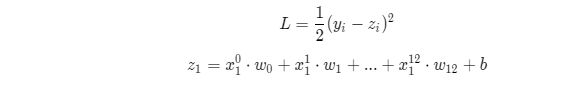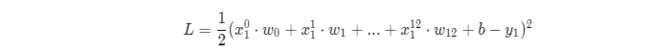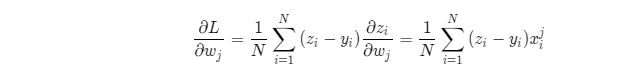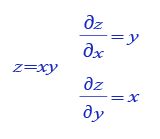class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights,1)
self.w[5] = -100.
self.w[9] = -100.
self.b = 0.
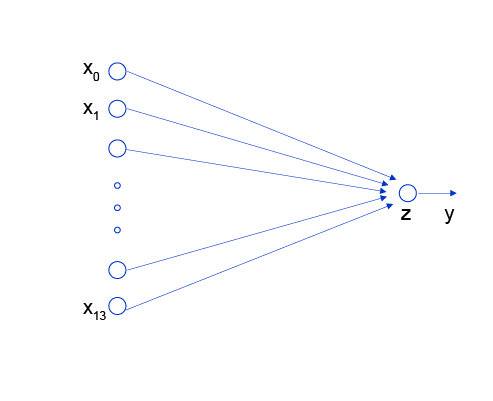
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, graident_w5, gradient_w9, eta=0.01):
net.w[5] = net.w[5] - eta * gradient_w5
net.w[9] = net.w[9] - eta * gradient_w9
def train(self, x, y, iterations=100, eta=0.01):
points = []
losses = []
for i in range(iterations):
points.append([net.w[5][0], net.w[9][0]])
z = self.forward(x)
L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y)
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
self.update(gradient_w5, gradient_w9, eta)
losses.append(L)
if i % 50 == 0:
print('iter {}, point {}, loss {}'.format(i, [net.w[5][0], net.w[9][0]], L))
return points, losses
# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=2000
# 启动训练
points, losses = net.train(x, y, iterations=num_iterations, eta=0.01)
# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
iter 0, point [-99.99144364382136, -99.93861587635192], loss 686.3005008179159
iter 50, point [-99.56362583488914, -96.92631128470325], loss 649.221346830939
iter 100, point [-99.13580802595692, -94.02279509580971], loss 614.6970095624063
iter 150, point [-98.7079902170247, -91.22404911807594], loss 582.543755023494
iter 200, point [-98.28017240809248, -88.52620357520894], loss 552.5911329872217
iter 250, point [-97.85235459916026, -85.9255316243737], loss 524.6810152322887
iter 300, point [-97.42453679022805, -83.41844407682491], loss 498.6667034691001
iter 350, point [-96.99671898129583, -81.00148431353688], loss 474.4121018974464
iter 400, point [-96.56890117236361, -78.67132338862874], loss 451.7909497114133
iter 450, point [-96.14108336343139, -76.42475531364933], loss 430.68610920670284
iter 500, point [-95.71326555449917, -74.25869251604028], loss 410.988905460488
iter 550, point [-95.28544774556696, -72.17016146534513], loss 392.5985138460824
iter 600, point [-94.85762993663474, -70.15629846096763], loss 375.4213919156372
iter 650, point [-94.42981212770252, -68.21434557551346], loss 359.3707524354014
iter 700, point [-94.0019943187703, -66.34164674796719], loss 344.36607459115214
iter 750, point [-93.57417650983808, -64.53564402117185], loss 330.33265059761464
iter 800, point [-93.14635870090586, -62.793873918279786], loss 317.2011651461846
iter 850, point [-92.71854089197365, -61.11396395304264], loss 304.907305311265
iter 900, point [-92.29072308304143, -59.49362926899678], loss 293.3913987080144
iter 950, point [-91.86290527410921, -57.930669402782904], loss 282.5980778542974
iter 1000, point [-91.43508746517699, -56.4229651670156], loss 272.47596883802515
iter 1050, point [-91.00726965624477, -54.968475648286564], loss 262.9774025287022
iter 1100, point [-90.57945184731255, -53.56523531604897], loss 254.05814669965383
iter 1150, point [-90.15163403838034, -52.21135123828792], loss 245.67715754581488
iter 1200, point [-89.72381622944812, -50.90500040003218], loss 237.796349191773
iter 1250, point [-89.2959984205159, -49.6444271209092], loss 230.3803798866218
iter 1300, point [-88.86818061158368, -48.42794056808474], loss 223.3964536766492
iter 1350, point [-88.44036280265146, -47.2539123610643], loss 216.81413643451378
iter 1400, point [-88.01254499371925, -46.12077426496303], loss 210.60518520483126
iter 1450, point [-87.58472718478703, -45.027015968976976], loss 204.74338990147896
iter 1500, point [-87.15690937585481, -43.9711829469081], loss 199.20442646183588
iter 1550, point [-86.72909156692259, -42.95187439671279], loss 193.96572062803054
iter 1600, point [-86.30127375799037, -41.96774125615467], loss 189.00632158541163
iter 1650, point [-85.87345594905815, -41.017484291751295], loss 184.3067847442463
iter 1700, point [-85.44563814012594, -40.0998522583068], loss 179.84906300239203
iter 1750, point [-85.01782033119372, -39.21364012642417], loss 175.61640587468244
iter 1800, point [-84.5900025222615, -38.35768737548557], loss 171.59326591927967
iter 1850, point [-84.16218471332928, -37.530876349682856], loss 167.76521193253296
iter 1900, point [-83.73436690439706, -36.73213067476985], loss 164.11884842217898
iter 1950, point [-83.30654909546485, -35.96041373329276], loss 160.64174090423475
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta = 0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, x, y, iterations=100, eta=0.01):
losses = []
for i in range(iterations):
z = self.forward(x)
L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(L)
if (i+1) % 10 == 0:
print('iter {}, loss {}'.format(i, L))
return losses
# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=1000
# 启动训练
losses = net.train(x,y, iterations=num_iterations, eta=0.01)
# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
iter 9, loss 1.8984947314576224
iter 19, loss 1.8031783384598725
iter 29, loss 1.7135517565541092
iter 39, loss 1.6292649416831264
iter 49, loss 1.5499895293373231
...
...
iter 969, loss 0.18762412556104593
iter 979, loss 0.18609645920539716
iter 989, loss 0.18459651940712488
iter 999, loss 0.18312333809366155
batch_size = 10
n = len(train_data)
mini_batches = [train_data[k:k+batch_size] for k in range(0, n, batch_size)]
print('total number of mini_batches is ', len(mini_batches))
print('first mini_batch shape ', mini_batches[0].shape)
print('last mini_batch shape ', mini_batches[-1].shape)
total number of mini_batches is 41
first mini_batch shape (10, 14)
last mini_batch shape (4, 14)
# 新建一个array
a = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
a = a.reshape([6, 2])
print('before shuffle\n', a)
np.random.shuffle(a)
print('after shuffle\n', a)
# 获取数据
train_data, test_data = load_data()
# 打乱样本顺序
np.random.shuffle(train_data)
# 将train_data分成多个mini_batch
batch_size = 10
n = len(train_data)
mini_batches = [train_data[k:k+batch_size] for k in range(0, n, batch_size)]
# 创建网络
net = Network(13)
# 依次使用每个mini_batch的数据
for mini_batch in mini_batches:
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
loss = net.train(x, y, iterations=1)
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
a = self.forward(x) #前向计算
loss = self.loss(a, y) #计算损失
gradient_w, gradient_b = self.gradient(x, y) #计算梯度
self.update(gradient_w, gradient_b, eta) #更新参数
将两部分改写的代码集成到Network类中的train函数中,最终的实现如下。
import numpy as np
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
#np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
N = x.shape[0]
gradient_w = 1. / N * np.sum((z-y) * x, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = 1. / N * np.sum(z-y)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta = 0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, training_data, num_epoches, batch_size=10, eta=0.01):
n = len(training_data)
losses = []
for epoch_id in range(num_epoches):
# 在每轮迭代开始之前,将训练数据的顺序随机打乱
# 然后再按每次取batch_size条数据的方式取出
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个mini_batch包含batch_size条的数据
mini_batches = [training_data[k:k+batch_size] for k in range(0, n, batch_size)]
for iter_id, mini_batch in enumerate(mini_batches):
#print(self.w.shape)
#print(self.b)
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
a = self.forward(x)
loss = self.loss(a, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(loss)
print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.
format(epoch_id, iter_id, loss))
return losses
# 获取数据
train_data, test_data = load_data()
# 创建网络
net = Network(13)
# 启动训练
losses = net.train(train_data, num_epoches=50, batch_size=100, eta=0.1)
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
Epoch 0 / iter 0, loss = 0.6273
Epoch 0 / iter 1, loss = 0.4835
Epoch 0 / iter 2, loss = 0.5830
Epoch 0 / iter 3, loss = 0.5466
Epoch 0 / iter 4, loss = 0.2147
Epoch 1 / iter 0, loss = 0.6645
Epoch 1 / iter 1, loss = 0.4875
Epoch 1 / iter 2, loss = 0.4707
Epoch 1 / iter 3, loss = 0.4153
Epoch 1 / iter 4, loss = 0.1402
Epoch 2 / iter 0, loss = 0.5897
Epoch 2 / iter 1, loss = 0.4373
Epoch 2 / iter 2, loss = 0.4631
Epoch 2 / iter 3, loss = 0.3960
Epoch 2 / iter 4, loss = 0.2340
...
...
Epoch 45 / iter 4, loss = 0.0074
Epoch 46 / iter 0, loss = 0.1008
Epoch 46 / iter 1, loss = 0.0915
Epoch 46 / iter 2, loss = 0.0877
Epoch 46 / iter 3, loss = 0.1139
Epoch 46 / iter 4, loss = 0.0292
Epoch 47 / iter 0, loss = 0.0679
Epoch 47 / iter 1, loss = 0.0987
Epoch 47 / iter 2, loss = 0.0929
Epoch 47 / iter 3, loss = 0.1098
Epoch 47 / iter 4, loss = 0.4838
Epoch 48 / iter 0, loss = 0.0693
Epoch 48 / iter 1, loss = 0.1095
Epoch 48 / iter 2, loss = 0.1128
Epoch 48 / iter 3, loss = 0.0890
Epoch 48 / iter 4, loss = 0.1008
Epoch 49 / iter 0, loss = 0.0724
Epoch 49 / iter 1, loss = 0.0804
Epoch 49 / iter 2, loss = 0.0919
Epoch 49 / iter 3, loss = 0.1233
Epoch 49 / iter 4, loss = 0.1849
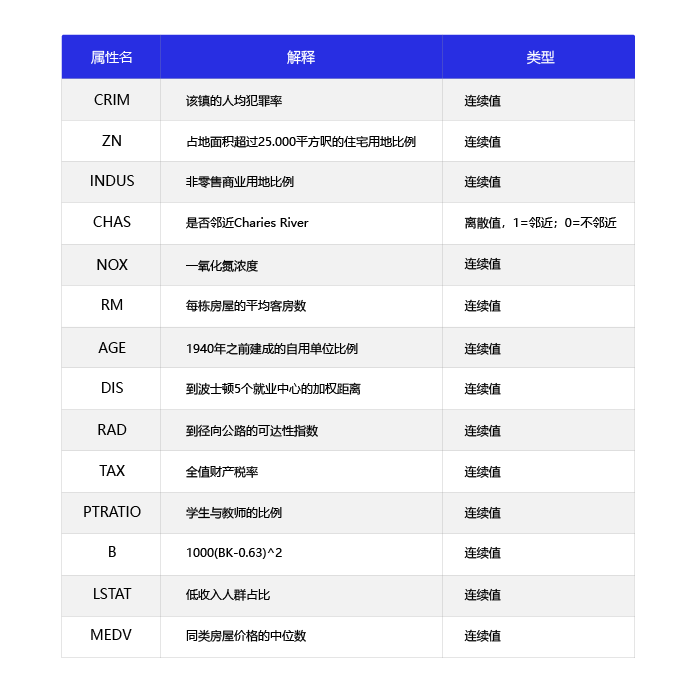
以教员和课程为例介绍一对多关联关系,在这里认为一个教员可以叫多门课程,而一门课程只有1个教员教,这种关系在实际中不太常见,通过教员和课程是多对多的关系。
示例数据:
地址表:
CREATE TABLE ADDRESSES
(
ADDR_ID INT(11) NOT NULL AUTO_INCREMENT,
STREET VAR
In this lesson we used the key "UITextAttributeTextColor" to change the color of the UINavigationBar appearance to white. This prompts a warning "first deprecated in iOS 7.0."
Ins
质数也叫素数,是只能被1和它本身整除的正整数,最小的质数是2,目前发现的最大的质数是p=2^57885161-1【注1】。
判断一个数是质数的最简单的方法如下:
def isPrime1(n):
for i in range(2, n):
if n % i == 0:
return False
return True
但是在上面的方法中有一些冗余的计算,所以
hbase(hadoop)是用java编写的,有些语言(例如python)能够对它提供良好的支持,但也有很多语言使用起来并不是那么方便,比如c#只能通过thrift访问。Rest就能很好的解决这个问题。Hbase的org.apache.hadoop.hbase.rest包提供了rest接口,它内嵌了jetty作为servlet容器。
启动命令:./bin/hbase rest s
下面这段sql本来目的是想更新条件下的数据,可是这段sql却更新了整个表的数据。sql如下:
UPDATE tops_visa.visa_order
SET op_audit_abort_pass_date = now()
FROM
tops_visa.visa_order as t1
INNER JOIN tops_visa.visa_visitor as t2
ON t1.