【TensorFlow】DNNRegressor 的简单使用
tf.contrib.learn.DNNRegressor 是 TensoFlow 中实现的一个神经网络回归器。一般神经网络用于分类问题的比较多,但是同样可以用于回归问题和无监督学习问题。
此文的代码和所生成的 TensorBoard 文件可以从 这里 下载。
tf.contrib.learn
tf.contrib.learn 是 TensorFlow 提供的一个机器学习高级 API 模块,让用户可以更方便的配置、训练和评估各种各样的机器学习模型,里面内置了很多模型可以直接调用,使用类似 scikit-learn 的 API 。大致有以下几种模型,具体可参考 Learn (contrib):
- K-means 聚类
tf.contrib.learn.KMeansClustering - 神经网络分类器
tf.contrib.learn.DNNClassifier - 神经网络回归器
tf.contrib.learn.DNNRegressor - 广度深度回归
tf.contrib.learn.DNNLinearCombinedRegressor - 广度深度分类
tf.contrib.learn.DNNLinearCombinedClassifier - 线性分类
tf.contrib.learn.LinearClassifier - 线性回归
tf.contrib.learn.LinearRegressor - 逻辑斯谛回归
tf.contrib.learn.LogisticRegressor
DNNRegressor
下面以波士顿房价预测的例子来说明一下 DNNRegressor 的使用。
波士顿房价数据集大小为 506*14,也就是说有 506 个样本,每个样本有 13 个特征,另外一个是要预测的房价。数据集我们直接使用 scikit-learn 的 load_boston() 函数直接载入,这里引用下UCI 的解释:
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000’s
开始前先说明一下,DNNRegressor 的使用逻辑和其他库的不太一样,如果你比较熟悉 TensorFlow 的话就比较好理解:我们是先定义一些计算图,这时候并不真正的传入数据,然后在训练的时候去执行这个计算图,也就是说这时候才开始将真正的数据穿进去。相当于是组装一条产品的生产线,刚开始我们只是把这台生产线组装好,并不开始真正的生产产品(保有数据),到最后阶段(训练阶段)才会真正的把原材料「喂给」生产线上来生产产品。
下面的程序大致上是这么几个步骤:
- 载入数据
- 定义
FeatureColumn - 定义 regressor
- 训练
- 评估
- 预测
载入数据
如上所说,这里我们使用 scikit-learn 的 load_boston() 函数来载入数据。
boston = load_boston()
boston_df = pd.DataFrame(np.c_[boston.data, boston.target], columns=np.append(boston.feature_names, 'MEDV'))
LABEL_COLUMN = ['MEDV']
FEATURE_COLUMNS = [f for f in boston_df if not f in LABEL_COLUMN]boston 是一个 numpy 多维数组,为了后面方便转换成 pandas 的 DataFrame 类型,MEDV 就是我们要预测的变量。
然后我们使用 train_test_split() 来按照 7:3 的比例来分割数据集。
X_train, X_test, y_train, y_test = train_test_split(boston_df[FEATURE_COLUMNS], boston_df[LABEL_COLUMN], test_size=0.3)
print('训练集:{}\n测试集:{}'.format(X_train.shape, X_test.shape))训练集:(354, 13)
测试集:(152, 13)在进行下一步之前,我们先来简单的看下这个数据集的分布情况。
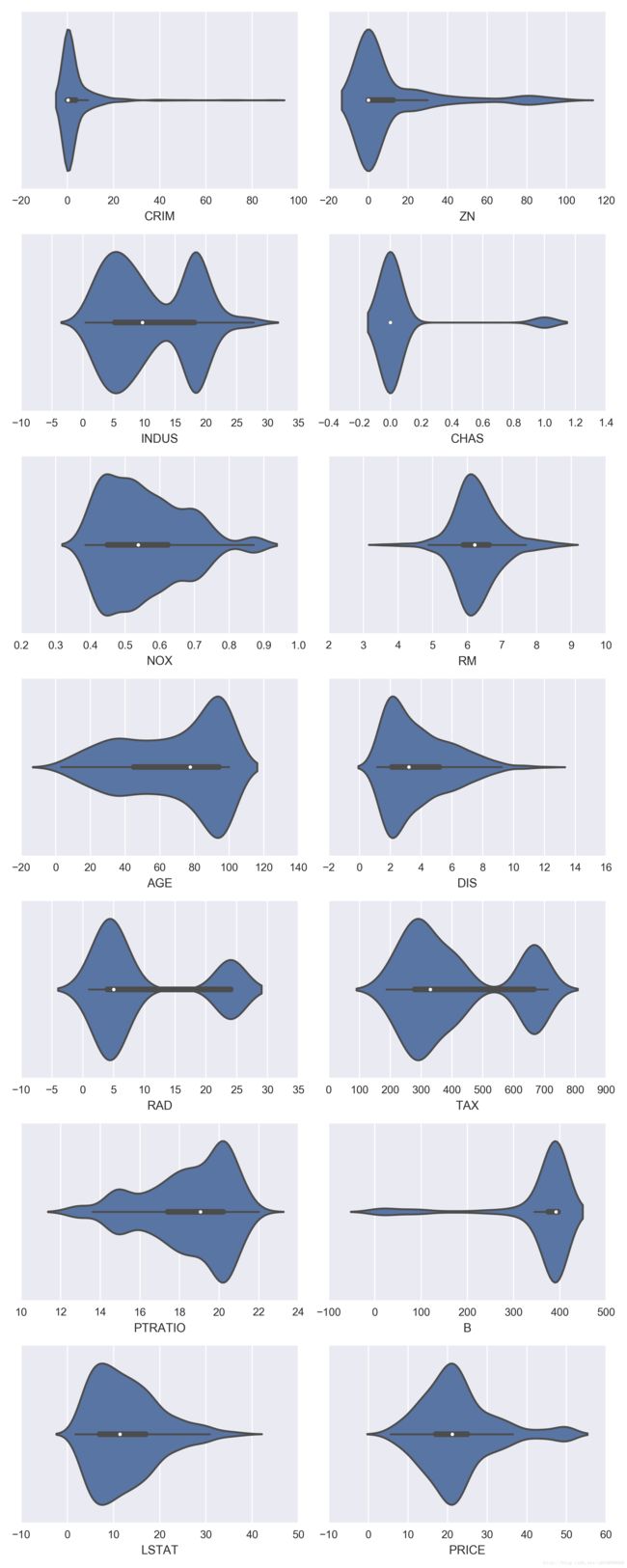
各个变量的 violin 图,从这些图我们可以看出每个变量的分布情况:
14 个变量之间的相关情况:
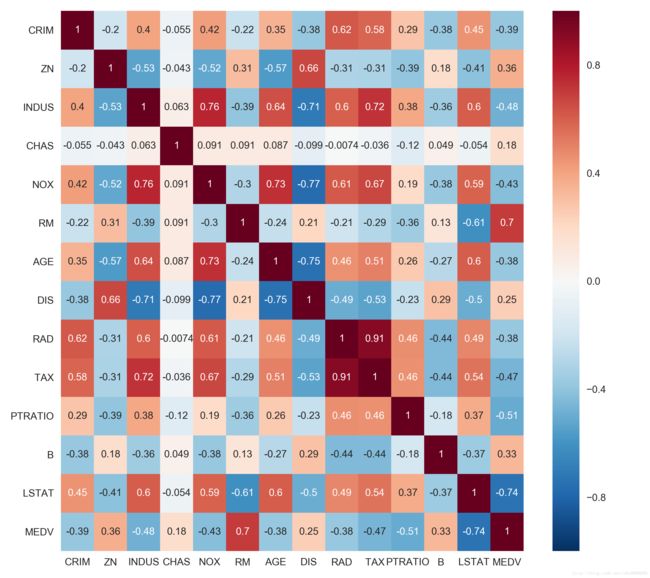
右键在新标签页打开可以查看大图
从这个图我们可以看出 RM (住宅平均房间数)与最终的售价是最正相关的,而 LSTAT (人口中地位低下者的比例)是最负相关的。
定义 FeatureColumn
TensorFlow 使用 FeatureColumn 来表示数据集中的一个的特征,我们需要根据特征类型(连续或者分类)把原来的特征都转换成 FeatureColumn。此处数据已经都是连续数值了,所以直接使用 tf.contrib.layers.real_valued_column() 来转换成 FeatureColumn,如果是分类变量,则需要使用 tf.contrib.layers.sparse_column_with_keys() 或者 tf.contrib.layers.sparse_column_with_hash_bucket()。
feature_cols = [tf.contrib.layers.real_valued_column(k) for k in FEATURE_COLUMNS]定义 regressor
这里就到定义模型的时候了,也就是 DNNRegressor,将我们前面定义的 FeatureColumn 传进去,再设置下隐藏层的层数和神经元数量,指定模型保存目录(训练完成后可以使用 tensorboard 可视化网络结构和训练过程)。
regressor = tf.contrib.learn.DNNRegressor(feature_columns=feature_cols,
hidden_units=[64, 128],
model_dir='./models/dnnregressor')定义 input_fn
定义完 regressor 之后就是模型的训练了,但是在训练开始前,我们需要定义一下传给模型训练的数据的格式,这就是 input_fn 的作用。input_fn 必须返回 feature_cols 和 labels。
feature_cols是一个字典, key 是特征的名字,value 是对应的数据(Tensor 格式)labels是一个 Tensor,就是你要预测的变量
def input_fn(df, label):
feature_cols = {k: tf.constant(df[k].values) for k in FEATURE_COLUMNS}
label = tf.constant(label.values)
return feature_cols, label
def train_input_fn():
'''训练阶段使用的 input_fn'''
return input_fn(X_train, y_train)
def test_input_fn():
'''测试阶段使用的 input_fn'''
return input_fn(X_test, y_test)训练
定义完 input_fn 我们就可以开始真正的训练过程了。
regressor.fit(input_fn=train_input_fn, steps=5000)训练阶段和测试阶段所用的数据是不一样的,所以在上面我又分别为训练和测试写了一个 input_fn。当然除了这种方式还有其他方式,你可以只写一个 input_fn,然后在 fit 的时候使用类似 input_fn=lambda: input_fn(training_set) 来制定传入的数据集。注意你不能直接使用 input_fn=input_fn(training_set) ,因为 input_fn 参数的值是一个函数。
测试
ev = regressor.evaluate(input_fn=test_input_fn, steps=1)
print('ev: {}'.format(ev))测试结果是一个字典,包括最终损失和迭代步数:
ev: {'loss': 32.229404, 'global_step': 5000}我们从 TensorBoard 可以看到最终的训练损失和测试损失:
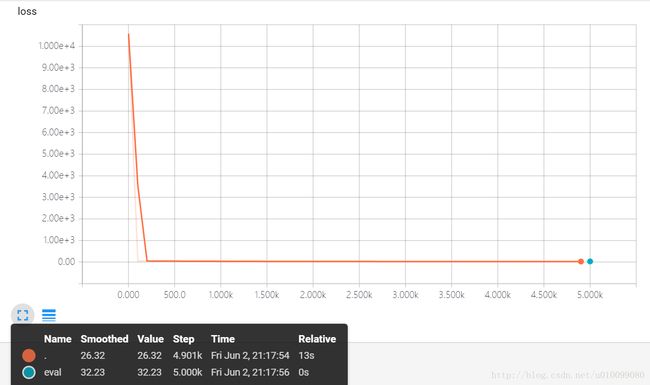
右键在新标签页打开可以查看大图
整个计算图是这样的:
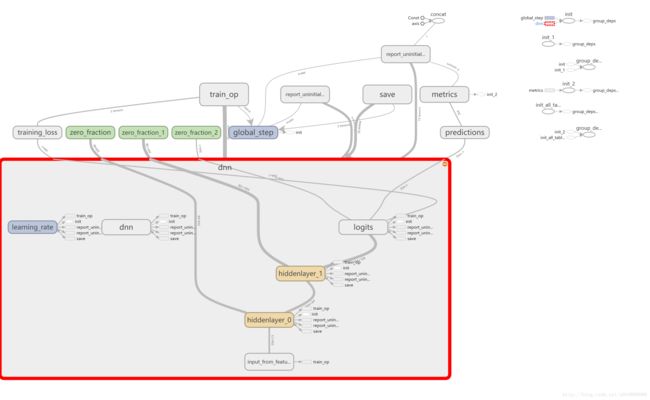
右键在新标签页打开可以查看大图
预测
使用训练好的模型对测试数据进行预测,只输出前 10 项预测结果:
predict = regressor.predict(input_fn=test_input_fn, as_iterable=False)
print(predict[:10])[ 25.04570198 31.65488815 11.31779861 14.20497131 31.12402344
37.50260925 25.20910835 24.17683983 20.83440208 35.22043991]Trouble Shooting
InternalError (see above for traceback): Blas SGEMM launch failed
如果你的程序报类似这样的错,说明你在使用 GPU 计算(默认行为)且你的 GPU 可用显存不足,TensorFlow 总是试图为自己分配全部显存,例如你的显存是 2GB,那么他就会试图为自己分配 2GB,但是一般情况下你的显存不会一点都不被其他程序占用的,导致 TensorFlow 分配显存失败。
解决办法是在定义 regressor 的时候使用 config 参数中的 gpu_memory_fraction 来指定分配给 TensorFlow 的显存大小(比例):
# log_device_placement 用于记录并输出使用的设备,可以不用写
config = tf.contrib.learn.RunConfig(gpu_memory_fraction=0.3, log_device_placement=True)
regressor = tf.contrib.learn.DNNRegressor(feature_columns=feature_cols,
hidden_units=[64, 128],
model_dir='./models/dnnregressor',
config=config)