决策树在多因子模型中的应用(一)
一、决策树原理说明
日常生活中,我们对于事物的认知都是基于特征的判断与分类,例如,我们要判断一个西瓜是不是好西瓜,通常会进行一系列的判断,如先看它是什么颜色,它敲起来是什么声音。决策树就是采用这样的思想进行甄别。
当有一堆西瓜混在一起,我们要进行好瓜坏瓜区分,就要基于多个特征进行分类决策,过程如下图所示:

这个过程确实就像一棵倒置的树。
- 节点:能够进行分叉的结点(图中方块)
- 叶子节点:没有进行分叉的结点(图中椭圆)
在决策树的每个结点处,根据特征的表现通过某种规则分裂出下一层的叶子节点,终端的叶子节点即为最终的分类结果。也就是说,我们通过一个又一个条件判断,不断的对这堆西瓜进行划分,最终给出好瓜坏瓜的结论。决策树学习的关键就是选择最优划分属性。随着逐层划分,决策树分支结点所包含的样本类别会逐渐趋于一致,决策树算法追求的目标,就是寻找最有效的特征进行划分,即节点分裂时要使得节点分裂后的信息增益(Information Gain)最大,这里列出决策树中判断信息量增减的方法,信息熵(Entropy)和基尼系数(Gini)的计算公式。
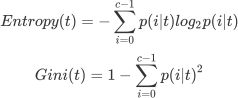
t 代表给定的节点
i 代表标签的任意分类,p(i|t)p(i|t) 代表标签分类 i 在节点 t 上所占的比例。
这两个公式就是衡量信息不纯度的指标,可以用来衡量每次决策前后,信息混程度变化的情况。
好了,经过这两个公式和熵、基尼系数、信息增益的概念引入,已经让本篇内容不够亲切了,而且,我们在使用这些机器学习算法的时候,可以进行参数设置,并不能改写算法干预算法内部的逻辑,所以,关于更多原理内容,大家可以参考其他学习资料进行学习,比如周志华《机器学习》等。
接下来我们从应用的层面进行探索。
二、决策树建立方法
机器学习有一套固定的建模流程方法, sklearn 的基本建模流程如下:

在这个流程下,我们分类树对应的代码是
from sklearn import tree #导入需要的模块
clf = tree.DecisionTreeClassifier() #实例化
clf = clf.fit(x_train,y_train) #用训练集数据训练模型
result = clf.score(x_test,y_test) #测试集测试打分这里我们发现,其实我们在使用机器学习方法的时候,需要使用的代码是非常少的,复杂的算法已经是封装好了的内容。
三、因子数据获取
有了上面的通用建模流程,这里首先进行因子数据获取,我们参考华泰证券《人工智能选股之随机森林模型》研报思路流程。

进行特征和标签提取,特征数据即为因子数据,标签即为收益情况。
本篇研究内容中,我们先获取了过去 5 年每个月月初截面期的 47 个因子数据(这里因子数据计算参考 西安交大元老师量化小组 的机器学习的因子计算内容),按获取因子数据的日历列表,进行空值和行业市值中性化处理,并将下期的股票收益也计算得出并加其中。
四、标签设置
第 T 期因子值和 T+1 期的收益均已计算加入数据表中,接下来我们给数据打标签,希望从给定训练数据集学得一个模型用以对新示例进行预测。
这里我们想尝试采用两种方式,以分类和回归方法分别进行学习并检查效果,两种方式都有具体操作代码示例。
五、模型拟合,得分检查
这里注意一下,我们直观理解,进行分类的情景多为离散的数值,如判断西瓜好坏的例子中,西瓜纹理是模糊的还是清晰的,就是对样本的离散特征描述。然而一般情况下,我们的样本特征是离散特征,与连续特征并存的。
决策树里面在进行连续值处理时采用二分法,即通过某个值将连续值集合划分为两个子集。即可延续离散值的划分方法。
我们这里的 y,是股票涨跌幅,是个连续值,所以首先想到的是用决策树回归的方法进行模型拟合。
这里我们对 score 进行说明,在回归模型中,这个 score 返回的是 R 平方,其中

u 是残差平方和(MSE * N)
v 是总平方和,N 是样本数量
i 是每一个数据样本
fi 是模型回归出的数值
yi 是样本点i实际的数值标签
y 帽是真实数值标签的平均数
R 平方可以为正为负,如果模型的残差平方和远远大于模型的总平方和,模型非常糟糕,R 平方就会为负,我们进行了回归模型的尝试,目前来看,拟合得分结果就非常不理想。
基于这种情况,接着我们用构造分类的模型进行拟合,对于股票涨跌幅超过基准则标签记为 1,小于基准则标签记为 0,对标签 y 进行构造,重新构建测试集与训练集合,进行的模拟拟合得分为 54.7%,也就是预测的准确率为 54.7%(到这里,内心已经蛮崩溃的,这个正确率和随机能有多少差别,看到《人工智能选股之随机森林模型》中模型的预测得分是在 55~60%之间,有点释怀了)
六、调优说明
“剪枝是决策树学习算法对付‘过拟合’的主要手段,在决策树学习中,为了尽可能正确分类训练样本,结果划分过程将不断重复,有时会造成决策树分支过多,这时就可能因为训练样本学得太好了,以致于把训练集自身的一些特点当做所有数据都具有的一般性质而导致过拟合,因此,可通过主动去掉一些分支来降低过拟合的风险”,这段描述来自《机器学习》决策树部分剪枝处理。
过拟合造成的结果就是,模型会在训练集上表现很好,在测试集上却表现糟糕,为了让决策树有更好的泛化性,需要对决策树进行剪枝处理。
可用于剪枝的参数

进行剪枝参数调整,参数优化。
我们发现,模型可以进行设置的参数并不少,这里,就可以采取如同策略回测中用到的参数调优方法,以不同参数为横轴坐标,模型得分为纵轴指标,展示不同参数下模型的学习效果,得到的就是超参数学习曲线。


在回归模式中,我们看到,模型测试集得分从一开始就没有到 0 轴以上,这显示是一个很糟糕的结果,训练集本身的拟合效果随着树的最大深度增加,不断的逼近 1。
在分类模式中,我们看到,模型测试集得分一开始在 55%左右,在不断增加最大深度后,测试集得分不断下降,靠近 50%,训练集部分过拟合,不断靠近 1。
目前,暂时只进行了最大深度的参数效果检查,其他参数效果可以在提供的研究代码上进行设置检查。
七、特征重要性说明
拟合出的模型,有很多属性和方法(我们可以在拟合的模型后面加一个点然后 tab 键就可以显示)。

对决策树来说,它的工作原理就是基于特征对模型进行划分的过程,下面展示在我们给的数据集中一棵深度为 3 的分类树。

这就是白盒模型的优势所在,能够追溯整个决策过程,除了能够图形化展示决策过程,决策树可以对各个特征对模型的重要性进行查看,这个方法,可以直接用于检查股票因子模型中各因子在收益中的重要性占比了,非常实用,属性方法是 featureimportances,可以在代码中看到。
这里我们取一棵决策树,调用这个方法,并展示这棵树在进行决策分类时的因子重要性情况。
我们获取该因子决策树中特征重要性数据,与特征标签匹配后用条形统计图展示。

八、后续
相比其他复杂的机器学习算法,决策树模型易于理解与解释,而且支持处理分类和回归两种变量,属于白盒模型,能够获取到特征在参与决策过程中的重要性数据,作为复杂一些集成学习算法中的基学习器,还是很有必要进行进一步的探索研究的。
我们会继续进行决策树在多因子模型应用探索,并且根据拟合模型做收益预测构建策略。
点击【阅读原文】,查看完整研究源码~