对一段示例代码的分析,在mnist数据集上使用tensorflow建立多层感知器(MLP)和用tensorflow的方法训练深度神经网络(DNN)
文章目录
- tf.feature_column.numeric_column
- tf.estimator.inputs.numpy_input_fn
- 评估结果中含有的信息
- 预测结果中含有的信息
- 完整代码
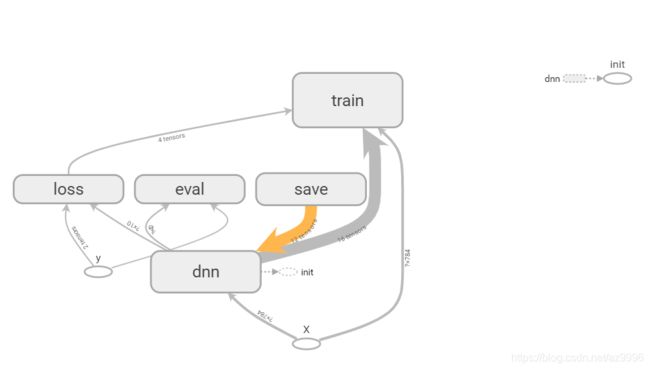
- 尝试用tensorboard可视化图
代码来自书上:
tf.feature_column.numeric_column
特征列是指一组数据的相关特征,包含了数据的相关类型和长度等信息
>>>feature_cols = [tf.feature_column.numeric_column("X",shape=[28*28])]
[NumericColumn(key='X', shape=(784,), default_value=None, dtype=tf.float32, normalizer_fn=None)]
特征列FeatureColumns
https://www.jianshu.com/p/fceb64c790f3
.
TensorFlow Estimator 官方文档之----Feature column
https://blog.csdn.net/u014061630/article/details/82937333
tf.estimator.inputs.numpy_input_fn
将python array、numpy array、pandans dataframe类型的变量转为tensorflow张量
#输入函数,将python array、numpy array、pandans dataframe类型的变量转为tensorflow张量
>>>test_input_fn=tf.estimator.inputs.numpy_input_fn(x={"X":X_test},y=y_test,shuffle=False)
<function numpy_input_fn.<locals>.input_fn at 0x0000029915B87378>
<class 'function'>
tensorflow(4) 在tf.estimator中建立input函数
https://blog.csdn.net/u013608336/article/details/78031788
在tf.estimator中构建inpu_fn解读
https://blog.csdn.net/vagrantabc2017/article/details/77482891
评估结果中含有的信息
>>>dnn_clf.evaluate(input_fn=test_input_fn)
{'accuracy': 0.9798, 'average_loss': 0.10640016, 'loss': 13.468374, 'global_step': 44000}
预测结果中含有的信息
>>>y_pred_iter = dnn_clf.predict(input_fn=test_input_fn)
>>>y_pred=list(y_pred_iter)
>>>print(y_pred[0])
{'logits': array([ -6.8882995 , -6.5348635 , -1.476299 , 5.218721 ,
-9.047006 , -2.298601 , -23.06852 , 26.49086 ,
0.35283503, 3.4610562 ], dtype=float32), 'probabilities': array([3.1887161e-15, 4.5405760e-15, 7.1452436e-13, 5.7760052e-10,
3.6821499e-16, 3.1397560e-13, 2.9966425e-22, 1.0000000e+00,
4.4504084e-12, 9.9605449e-11], dtype=float32), 'class_ids': array([7], dtype=int64), 'classes': array([b'7'], dtype=object)}
完整代码
'''
使用纯tensorflow训练DNN
实现一个小批次梯度下降来训练MNIST数据集
首先是构建阶段,建立tensorflow的计算图,第二步是执行阶段
具体运行这个图来训练模型。
'''
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import tensorflow as tf
datasets_path="../../Datasets/mnist/mnist.npz"
try:
data=np.load(datasets_path)
X_train, y_train, X_test, y_test = data['x_train'], data['y_train'], data['x_test'], data['y_test']
#保存一条数据,方便查看
np.savetxt('test.txt', X_train[0], fmt='%3d', newline='\n\n')
# matplotlib可视化查看
for i in range(20):
plt.subplot(4, 5, i + 1)
plt.imshow(X_train[i], cmap=matplotlib.cm.binary, interpolation='none')
plt.title("Class {}".format(y_train[i]))
#plt.axis("off")
#plt.show()
#将数据归一化
X_train=X_train.astype(np.float32).reshape(-1,28*28)/255.0
X_test=X_test.astype(np.float32).reshape(-1,28*28)/255.0
except Exception as e:
print('%s',e)
#将数据类型转为int32
y_train=y_train.astype(np.int32)
y_test=y_test.astype(np.int32)
#将训练集的前5000个实例作为正式数据集,5000以后的作为训练集
X_valid,X_train=X_train[:5000],X_train[5000:]
y_valid,y_train=y_train[:5000],y_train[5000:]
#特征列=,使用tf.feature_column.numeric_column获取数值特征列
#特征列是指一组数据的相关特征,包含了数据的相关类型和长度等信息
feature_cols = [tf.feature_column.numeric_column("X",shape=[28*28])]
# print(feature_cols)
# exit()
dnn_clf=tf.estimator.DNNClassifier(hidden_units=[300,100], #隐藏层的列表,值代表该层神经元个数
n_classes=10, #类别为10
feature_columns=feature_cols) #特征列
input_fn=tf.estimator.inputs.numpy_input_fn(
x={"X":X_train},#输入的训练集
y=y_train, #训练集对应的标签
num_epochs=40, #迭代次数
batch_size=50, #批次大小
shuffle=True) #洗牌,打乱数据集
dnn_clf.train(input_fn=input_fn)
#输入函数,将python array、numpy array、pandans dataframe类型的变量转为tensorflow张量
test_input_fn=tf.estimator.inputs.numpy_input_fn(x={"X":X_test},y=y_test,shuffle=False)
# print(test_input_fn,type(test_input_fn))
# exit()
#评估结果,dnn_clf模型的分数
eval_results=dnn_clf.evaluate(input_fn=test_input_fn)
print(eval_results)
#对多批数据进行迭代预测,输出值放在列表中
y_pred_iter = dnn_clf.predict(input_fn=test_input_fn)
y_pred=list(y_pred_iter)
print(y_pred[0])
#exit()
'''
----------------------------------------------------------------------
使用纯tensorflow
'''
n_inputs=28*28 #MNIST中,每一张图片是28*28像素,每一个特征代表了像素点的强度
n_hidden1=300
n_hidden2=100
n_outputs=10
tf.reset_default_graph()#重置默认图
X=tf.placeholder(tf.float32,shape=(None,n_inputs),name="X") #创建一个占位符节点,来表示训练数据。已知X是一个二维张量,一个维度是实例,另一个维度是特征。实例数量未知,所以设为None;特征数量已知,所以设为n_inputs
y=tf.placeholder(tf.int32,shape=(None),name="y") #已知y是一个一维的张量,每个实例都有一个入口,但是我们现在还不知道训练批次的大小,所以形状是None
def neuron_layer(X,n_neurons,name,activatioin=None):
with tf.name_scope(name):
n_inputs = int(X.get_shape()[1])
stddev=2/np.sqrt(n_inputs)
init=tf.truncated_normal((n_inputs,n_neurons),stddev=stddev)
W=tf.Variable(init,name="kernel")
b=tf.Variable(tf.zeros([n_neurons]),name="bias")
Z=tf.matmul(X,W)+b
if activatioin is not None:
return activatioin(Z)
else:
return Z
with tf.name_scope("dnn"):
hidden1=neuron_layer(X,n_hidden1,name="hidden1",
activatioin=tf.nn.relu)
hidden2=neuron_layer(hidden1,n_hidden2,name="hidden2",
activatioin=tf.nn.relu)
logits=neuron_layer(hidden2,n_outputs,name="outputs")
with tf.name_scope("loss"):
xentropy=tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,
logits=logits)
loss=tf.reduce_mean(xentropy,name="loss")
learning_rate=0.01
with tf.name_scope("train"):
optimizer=tf.train.GradientDescentOptimizer(learning_rate)
training_op=optimizer.minimize(loss)
with tf.name_scope("eval"):
correct=tf.nn.in_top_k(logits,y,1)
accuracy=tf.reduce_mean(tf.cast(correct,tf.float32))
init=tf.global_variables_initializer()
saver=tf.train.Saver()
n_epochs=40
batch_size=50
def shuffle_batch(X,y,batch_size):
rnd_idx=np.random.permutation(len(X))
n_batches=len(X) // batch_size
for batch_idx in np.array_split(rnd_idx,n_batches):
X_batch,y_batch=X[batch_idx],y[batch_idx]
yield X_batch,y_batch
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for X_batch,y_batch in shuffle_batch(X_train,y_train,batch_size):
sess.run(training_op,feed_dict={X:X_batch,y:y_batch})
acc_batch=accuracy.eval(feed_dict={X:X_batch,y:y_batch})
acc_val=accuracy.eval(feed_dict={X:X_valid,y:y_valid})
print(epoch,"Batch accuracy:",acc_batch,"Val accuracy:",acc_val)
save_path=saver.save(sess,"../checkpoint/dnn_model/my_model_final.ckpt")
尝试用tensorboard可视化图

在批次的迭代中加入写tensorboard的操作后,发现save节点向dnn节点有回馈张量的操作