一、过度拟合

对于图中的例子,
可以看出第一幅图中使用一个变量从而用一条直线来拟合数据,可以看出效果不好,偏差很大,因此,定义其为:欠拟合(underfit),高偏差(high bias);
第三幅图中,使用多个变量,高次数来拟合数据,可以看出全部数据都能很好的拟合,但是这种情况导致拟合函数变量过多,复杂度高,对于新的样本拟合度欠佳,因此无法泛化到其他样本,称其为:过度拟合(overfit),*高方差 (high variance)
因此,过度拟合的特点如下:

看看另一个例子

对于第一个图,使用两个变量,可以拟合出一条直线,可以看出效果不是很好,这也是一个欠拟合的例子。
对于第二个图中,增加了假如了一些二次项,很好的拟合了数据,可以说是训练集训练出的最好拟合结果。
对于第三个图中,使用了很多的高阶项,会使逻辑回归自身扭曲,过度拟合了数据,形成图中的决策边界。这是一个过度拟合的例子。
二、解决过度拟合
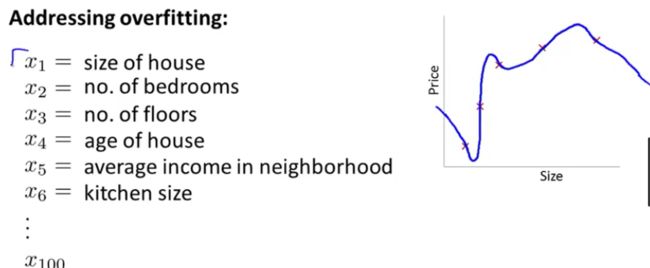
同样在这个问题中,假设我们只有很少的样本数量,并且样本的特征值很多的时候,那么就会出现过度拟合的问题。
解决这个问题有两个思路,

第一种方法就是【减少特征的数量】:通过【人工检查】来决定或者使用【模型选择算法】自动选择,这两个措施都可以解决过拟合,然而会去掉一些特征,但是我们有时候并不想舍弃一些看起来有用的特征。
第二种方法就是【正规化】:保留所有的特征,但是减少参数theta(j)的量级(magnitude)或者大小(value)。这种措施能够很好的作用,使得当有很多特征时,每一个特征将会对预测值y产生一点影响。
下面我们介绍正规化。
三、 正规化(regularization)

这个图中,我们根据前面的知识知道图二过拟合,一般性不好。在所有的特征中,我们根据关联度来抉择那个特征的权重,也就是特征的亲疏关系,如果特征的重要性不高的话,那么我们就通过某种方法降低这个特征的影响力,这种方法就是正规化。

如图中,我们假设theta(3),theta(4)的权重不高,也就是他们两个参数的关联度不够重要,我们需要降低他们两个的影响。
那么我们通过在代价函数中通过增加后面两个式子,这样在计算某个theta的最小值时,
例如计算theta(3)的时候,后面增加了1000*theta(3)^2,要使得代价函数最小,那么我们可以知道,theta(3)的值必须趋近于0的时候,整个代价函数才能够得到最小值。
这样的结果,最终我们可以获得更小的theta(3),theta(4)的值,那么在拟合函数里面,

,theta(3),theta(4)的影响力下降,整个式子接近与二次函数,从而拟合度更好!
正规化的好处于:

1.更简单的拟合函数
2.不易发生过拟合问题

在这个问题中,可以看到有100个特征,101个参数,类似的,在很多问题中,我们不知道这些特征的关联度,因此无法很好的选择该“惩罚”那个特征,因此我们就对所有的参数进行收缩惩罚,【下标从1开始的】
因此,正规化的公式如下:
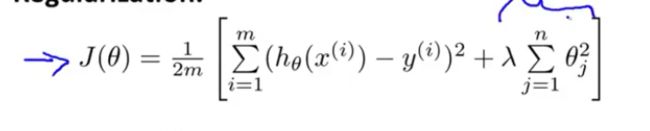
这里有一个问题,当我们随意选择labmda的时候,假设我们使得lambda很大,

会发生什么情况呢?

有前面的思路,我们可以知道,labmda越大,那么参数theta(1),theta(2)..都会变得非常小, 那么拟合函数就如图中成为了一个常数函数直线theta(0),造成的结果就是【过拟合】
四、正规化在线性规划的应用

在这张图片中,我们将正规化的代价函数应用到梯度下降算法中,可以看到之后新的迭代公式,其中,

为啥会是小于1的呢?alpha一般很小,而且m是很大的存在,一般差值为0.99?有点不明白。
对于线性规划的另一种方法---正规方程

【暂且不懂】
五、线性规划对于逻辑回归的应用
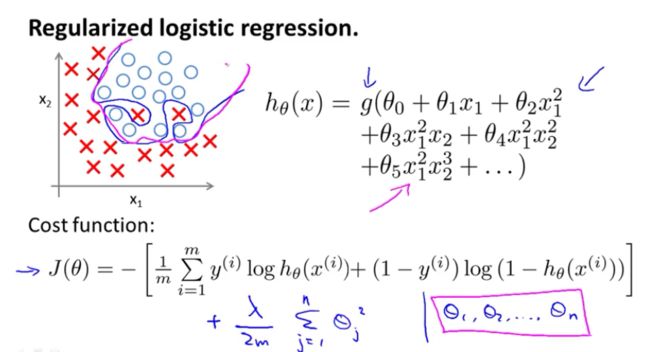
正规化的代价函数如图,
应用于梯度下降,迭代公式如图,
