CVPR2019 Relation-Shape CNN、ICCV2019 Dense Point论文及源码学习
笔记参考了这两篇论文的作者的讲解,b站链接放在了文末。
文章目录
- Relation-Shape CNN
- Relation-Shape CNN
- 源码学习
- rscnn_msn_seg.py
- pointnet2_modules.py
- PointnetSAModuleBase
- PointnetSAModuleMSG
- PointnetSAModule
- pytorch_utils.py
- RSConv
- GloAvgConv
- GroupAll
- DensePoint
- DensePoint
- 源码学习
- densepoint_cls_L6_k24_g2.py
- pointnet2_modules.py
- pytorch_utils.py
- PointConv
- EnhancedPointConv
- FC
- 点云处理存在的问题
- 研究方向
Relation-Shape CNN
Relation-Shape CNN
Relation-Shape Convolutional Neural Network for Point Cloud Analysis
作者认为通过感知点云的形状特征可以更好的完成点云上的分类、分割等任务,因此需要设计一种可以描述某区域内点云形状的编码 f P s u b f_{P_{sub}} fPsub,在设计时,作者选用了球体区域。建模如下:
f P usb = σ ( A ( { T ( f x j ) , ∀ x j } ) ) , d i j < r ∀ x j ∈ N ( x i ) \mathbf{f}_{P_{\text {usb }}}=\sigma\left(\mathcal{A}\left(\left\{\mathcal{T}\left(\mathbf{f}_{x_{j}}\right), \forall x_{j}\right\}\right)\right), d_{i j}
即学习以 x i x_i xi为中心,以 r r r为半径的球形邻域内各个点与中心点的关系,首先对邻域中的每个点进行特征变换 T \mathcal{T} T,然后进行特征聚合 A \mathcal{A} A,最后使用一个非线性变换 σ \sigma σ得到结果。
为了能够实现置换不变性, T \mathcal{T} T中的参数必须是共享的, A \mathcal{A} A则必须是对称的。但传统卷积 T ( f x j ) = w j ⋅ f x j \mathcal{T}(f_{x_j})=w_j · f_{x_j} T(fxj)=wj⋅fxj的权重参数并不是共享的,为了解决这一问题,作者认为应从点与点之间的关系中进行学习,具体的:
T ( f x j ) = w i j ⋅ f x j = M ( h i j ) ⋅ f x j \mathcal{T}\left(\mathbf{f}_{x_{j}}\right)=\mathbf{w}_{i j} \cdot \mathbf{f}_{x_{j}}=\mathcal{M}\left(\mathbf{h}_{i j}\right) \cdot \mathbf{f}_{x_{j}} T(fxj)=wij⋅fxj=M(hij)⋅fxj
预先定义几何特征编码 h i , j h_{i,j} hi,j,然后将低维度的关系特征用MLP M \mathcal{M} M映射到高纬度空间, h i , j = [ 3 D E u c l i d e a n d i s t a n c e , x i − x j , x i , x j ] h_{i,j}=[3D Euclidean distance,x_i-x_j,x_i,x_j] hi,j=[3DEuclideandistance,xi−xj,xi,xj]。因为在设计时采用的是与刚体变换无关的欧氏距离,对于刚体变换也有一定的鲁棒性,但并没有真正解决这一问题。
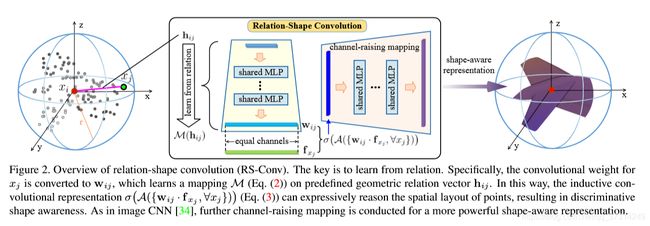
分割网络设计参考了PointNet++的上采用。论文最主要的亮点是设计了Relation-Shape Conv,RSConv的实现主要在pytorch_utils.py中。
源码学习
以分割网络为例,网络模型位于models目录下的rscnn_msn_seg.py,参数设置位于cfgs目录下的config_msn_partseg.yaml,训练使用train_partseg.sh. (果然还是更喜欢pytorch一些,感觉比tf写起来简洁清晰)
The code is heavily borrowed from Pointnet2_PyTorch.
rscnn_msn_seg.py
分割模型总共设置了4层PointnetSAModuleMSG,2层PointnetSAModule、4层PointnetFPModule和2层conv1d,其中PointnetSAModuleMSG用于提取局部特征,PointnetSAModule用于提取全局特征(global pooling),仅对forward部分添加了注释。各层的实现细节在pointnet2_modules.py中。
class RSCNN_MSN(nn.Module):
r"""
PointNet2 with multi-scale grouping
Semantic segmentation network that uses feature propogation layers
Parameters
----------
num_classes: int
Number of semantics classes to predict over -- size of softmax classifier that run for each point
input_channels: int = 6
Number of input channels in the feature descriptor for each point. If the point cloud is Nx9, this
value should be 6 as in an Nx9 point cloud, 3 of the channels are xyz, and 6 are feature descriptors
use_xyz: bool = True
Whether or not to use the xyz position of a point as a feature
"""
def __init__(self, num_classes, input_channels=0, relation_prior=1, use_xyz=True):
super().__init__()
self.SA_modules = nn.ModuleList()
c_in = input_channels
self.SA_modules.append( # 0
PointnetSAModuleMSG(
npoint=1024,
radii=[0.075, 0.1, 0.125],
nsamples=[16, 32, 48],
mlps=[[c_in, 64], [c_in, 64], [c_in, 64]],
first_layer=True,
use_xyz=use_xyz,
relation_prior=relation_prior
)
)
c_out_0 = 64*3
c_in = c_out_0
self.SA_modules.append( # 1
PointnetSAModuleMSG(
npoint=256,
radii=[0.1, 0.15, 0.2],
nsamples=[16, 48, 64],
mlps=[[c_in, 128], [c_in, 128], [c_in, 128]],
use_xyz=use_xyz,
relation_prior=relation_prior
)
)
c_out_1 = 128*3
c_in = c_out_1
self.SA_modules.append( # 2
PointnetSAModuleMSG(
npoint=64,
radii=[0.2, 0.3, 0.4],
nsamples=[16, 32, 48],
mlps=[[c_in, 256], [c_in, 256], [c_in, 256]],
use_xyz=use_xyz,
relation_prior=relation_prior
)
)
c_out_2 = 256*3
c_in = c_out_2
self.SA_modules.append( # 3
PointnetSAModuleMSG(
npoint=16,
radii=[0.4, 0.6, 0.8],
nsamples=[16, 24, 32],
mlps=[[c_in, 512], [c_in, 512], [c_in, 512]],
use_xyz=use_xyz,
relation_prior=relation_prior
)
)
c_out_3 = 512*3
self.SA_modules.append( # 4 global pooling
PointnetSAModule(
nsample = 16,
mlp=[c_out_3, 128], use_xyz=use_xyz
)
)
global_out = 128
self.SA_modules.append( # 5 global pooling
PointnetSAModule(
nsample = 64,
mlp=[c_out_2, 128], use_xyz=use_xyz
)
)
global_out2 = 128
self.FP_modules = nn.ModuleList()
self.FP_modules.append(
PointnetFPModule(mlp=[256 + input_channels, 128, 128])
)
self.FP_modules.append(PointnetFPModule(mlp=[512 + c_out_0, 256, 256]))
self.FP_modules.append(PointnetFPModule(mlp=[512 + c_out_1, 512, 512]))
self.FP_modules.append(
PointnetFPModule(mlp=[c_out_3 + c_out_2, 512, 512])
)
self.FC_layer = nn.Sequential(
pt_utils.Conv1d(128+global_out+global_out2+16, 128, bn=True), nn.Dropout(),
pt_utils.Conv1d(128, num_classes, activation=None)
)
def _break_up_pc(self, pc):
xyz = pc[..., 0:3].contiguous()
features = (
pc[..., 3:].transpose(1, 2).contiguous()
if pc.size(-1) > 3 else None
)
return xyz, features
def forward(self, pointcloud: torch.cuda.FloatTensor, cls):
r"""
pointcloud: Variable(torch.cuda.FloatTensor)
(B, N, 3 + input_channels) tensor
Point cloud to run predicts on
Each point in the point-cloud MUST
be formated as (x, y, z, features...)
"""
# 将坐标数据和feature数据分开
xyz, features = self._break_up_pc(pointcloud)
l_xyz, l_features = [xyz], [features]
for i in range(len(self.SA_modules)):
# SA_modules的前5层,每层得到的li_xyz和li_feature打乱顺序后存入
# l_xyz和l_feature,作为下一次的输入,li_feature[4]为全局特征
if i < 5:
li_xyz, li_features = self.SA_modules[i](l_xyz[i], l_features[i])
if li_xyz is not None:
random_index = np.arange(li_xyz.size()[1])
np.random.shuffle(random_index)
li_xyz = li_xyz[:, random_index, :]
li_features = li_features[:, :, random_index]
l_xyz.append(li_xyz)
l_features.append(li_features)
# 再次计算一个全局特征
_, global_out2_feat = self.SA_modules[5](l_xyz[3], l_features[3])
# PointnetSAModuleMSG各层的计算顺序与添加顺序相反,大概这么写起来比较优雅,感觉hhhhh
for i in range(-1, -(len(self.FP_modules) + 1), -1):
l_features[i - 1 - 1] = self.FP_modules[i](
l_xyz[i - 1 - 1], l_xyz[i - 1], l_features[i - 1 - 1], l_features[i - 1]
)
# 把全局特征、FPmodules得到的特征和class one-hot-vector concate到一起
cls = cls.view(-1, 16, 1).repeat(1, 1, l_features[0].size()[2]) # object class one-hot-vector
l_features[0] = torch.cat((l_features[0], l_features[-1].repeat(1, 1, l_features[0].size()[2]), global_out2_feat.repeat(1, 1, l_features[0].size()[2]), cls), 1)
# 最后使用两层Conv1d得到分割结果
return self.FC_layer(l_features[0]).transpose(1, 2).contiguous()
pointnet2_modules.py
大概是为了提高代码复用率,模型的forward均在_PointnetSAModuleBase中定义,PointnetSAModuleMSG、PointnetSAModule两个类也基本在PointnetSAModuleMSG中定义好了。但具体的RSConv、GroupAll和GloAvgConv定义在了pytorch_utils.py。
PointnetSAModuleMSG首先对输入点进行最远点采样,然后将采样得到的点的数据和原始点云数据以及特征输入传入QueryAndGroup层(类似于pointnet++的sampling & grouping层),得到shape为[B, 3+C, npoint, nsample]的tensor,然后传入SharedRSConv层进行处理。Relation-Shape CNN的partseg部分 共设计了4层这样的PointnetSAModuleMSG,每层均包含3个尺度的操作。
PointnetSAModule,即global convolutional pooling操作,包含GroupAll层和GloAvgConv层。共设计了2层PointnetSAModule。
PointnetSAModuleBase
主要定义了前向传播函数,首先进行最远点采样,然后通过QueryAndGroup(sampling&grouping),再使用RSConv,如果使用了MSG,最后返回的是多尺度特征concat到一起的tensor,否则直接返回计算得到的特征。其中的furthest_point_sample和gather_operation的具体实现在pointnet2_utils.py、utils\csrc\sampling.c和utils\csrc\sampling_gpu.cu中。
class _PointnetSAModuleBase(nn.Module):
def __init__(self):
super().__init__()
self.npoint = None
self.groupers = None
self.mlps = None
def forward(self, xyz: torch.Tensor,
features: torch.Tensor = None) -> (torch.Tensor, torch.Tensor):
r"""
Parameters
xyz : (B, N, 3) tensor of the xyz coordinates of the points
features : (B, N, C) tensor of the descriptors of the the points
Returns
new_xyz (B, npoint, 3) tensor of the new points' xyz
new_features :(B, npoint, \sum_k(mlps[k][-1])) tensor of the new_points descriptors
"""
new_features_list = []
# (B,3,N)
xyz_flipped = xyz.transpose(1, 2).contiguous()
if self.npoint is not None:
# 最远点采样 fps_idx size=[B, npoint]
fps_idx = pointnet2_utils.furthest_point_sample(xyz, self.npoint)
# 从xyz中挑出最远点采样得到的点的坐标 new_xyz size=[B,npoint,3]
new_xyz = pointnet2_utils.gather_operation(xyz_flipped, fps_idx).transpose(1, 2).contiguous()
fps_idx = fps_idx.data
else:
new_xyz = None
fps_idx = None
# 逐层计算特征,并更新new_feature list
for i in range(len(self.groupers)):
new_features = self.groupers[i](xyz, new_xyz, features, fps_idx) if self.npoint is not None else self.groupers[i](xyz, new_xyz, features)
new_features = self.mlps[i](
new_features
) # (B, mlp[-1], npoint)
new_features_list.append(new_features)
# concat new_features_list的特征并返回
return new_xyz, torch.cat(new_features_list, dim=1)
PointnetSAModuleMSG
npoint == None的部分,均对应于PointnetSAModule。
class PointnetSAModuleMSG(_PointnetSAModuleBase):
r"""Pointnet set abstrction layer with multiscale grouping
Parameters
npoint : int
Number of points
radii : list of float32
list of radii to group with
nsamples : list of int32
Number of samples in each ball query
mlps : list of list of int32
Spec of the pointnet before the global max_pool for each scale
bn : bool
Use batchnorm
"""
def __init__(
self,
*,
npoint: int,
radii: List[float],
nsamples: List[int],
mlps: List[List[int]],
use_xyz: bool = True,
bias = True,
init = nn.init.kaiming_normal,
first_layer = False,
relation_prior = 1
):
super().__init__()
assert len(radii) == len(nsamples) == len(mlps)
self.npoint = npoint
self.groupers = nn.ModuleList()
self.mlps = nn.ModuleList()
# initialize shared mapping functions
C_in = (mlps[0][0] + 3) if use_xyz else mlps[0][0]
C_out = mlps[0][1]
# 根据relation_prior设置in_channels
if relation_prior == 0:
in_channels = 1
elif relation_prior == 1 or relation_prior == 2:
in_channels = 10
else:
assert False, "relation_prior can only be 0, 1, 2."
# 定义mapping modules,将特征映射到高维空间,仅在npoint不为None时使用,即只在PointnetSAModuleMSG中
# npoint=None对应的为PointnetSAModule
# 如果是第一层添加mapping_func1、mapping_func2、xyz_raising
if first_layer:
mapping_func1 = nn.Conv2d(in_channels = in_channels, out_channels = math.floor(C_out / 2), kernel_size = (1, 1),
stride = (1, 1), bias = bias)
mapping_func2 = nn.Conv2d(in_channels = math.floor(C_out / 2), out_channels = 16, kernel_size = (1, 1),
stride = (1, 1), bias = bias)
xyz_raising = nn.Conv2d(in_channels = C_in, out_channels = 16, kernel_size = (1, 1),
stride = (1, 1), bias = bias)
init(xyz_raising.weight)
if bias: #如果使用bias 初始化为0
nn.init.constant(xyz_raising.bias, 0)
# 否则只添加mapping_func1、mapping_func2
elif npoint is not None:
mapping_func1 = nn.Conv2d(in_channels = in_channels, out_channels = math.floor(C_out / 4), kernel_size = (1, 1),
stride = (1, 1), bias = bias)
mapping_func2 = nn.Conv2d(in_channels = math.floor(C_out / 4), out_channels = C_in, kernel_size = (1, 1),
stride = (1, 1), bias = bias)
# 初始化mapping_func1、mapping_func2的权重
if npoint is not None:
init(mapping_func1.weight)
init(mapping_func2.weight)
if bias:
nn.init.constant(mapping_func1.bias, 0)
nn.init.constant(mapping_func2.bias, 0)
# channel raising mapping
cr_mapping = nn.Conv1d(in_channels = C_in if not first_layer else 16, out_channels = C_out, kernel_size = 1,
stride = 1, bias = bias)
init(cr_mapping.weight)
nn.init.constant(cr_mapping.bias, 0)
if first_layer:
mapping = [mapping_func1, mapping_func2, cr_mapping, xyz_raising]
elif npoint is not None:
mapping = [mapping_func1, mapping_func2, cr_mapping]
# 根据radius为每层添加不同尺度的conv2d
for i in range(len(radii)):
radius = radii[i]
nsample = nsamples[i]
# 类似于pointnet++中的sampling & grouping 层
self.groupers.append(
pointnet2_utils.QueryAndGroup(radius, nsample, use_xyz=use_xyz) # [B, 3+C, npoint, nsample]
if npoint is not None else pointnet2_utils.GroupAll(use_xyz) # [B, 3+C, 1, N]
)
mlp_spec = mlps[i]
# 如果使用xyz作为特征输入,in_channels需要添加3个通道
if use_xyz:
mlp_spec[0] += 3
# 设置模型的rsconv层
if npoint is not None:
self.mlps.append(pt_utils.SharedRSConv(mlp_spec, mapping = mapping, relation_prior = relation_prior, first_layer = first_layer))
else: # global convolutional pooling
self.mlps.append(pt_utils.GloAvgConv(C_in = C_in, C_out = C_out))
PointnetSAModule
在 PointnetSAModuleMSG中已经定义好了,只包含GroupAll层和GloAvgConv层。根据前面rscnn_msn_seg.py中的设置,GroupAll返回的是xyz和feature concat到一起的tensor,shape为[B,C+3,1,N],然后通过GloAvgConv进行特征提取得到shape为[B,c_out,N]的tensor。
class PointnetSAModule(PointnetSAModuleMSG):
r"""Pointnet set abstrction layer
Parameters
----------
npoint : int Number of features
radius : float Radius of ball
nsample : int Number of samples in the ball query
mlp : list Spec of the pointnet before the global max_pool
bn : bool Use batchnorm
"""
def __init__(
self,
*,
mlp: List[int],
npoint: int = None,
radius: float = None,
nsample: int = None,
use_xyz: bool = True,
):
super().__init__(
mlps=[mlp],
npoint=npoint,
radii=[radius],
nsamples=[nsample],
use_xyz=use_xyz
)
pytorch_utils.py
RSConv
主要就是根据前面设计的mapping函数来实现的,参数共享主要是因为输入的tensor不只包含中心点的信息,还包含相邻点和中心点与邻点之间的relation shape(作者使用的是欧氏距离)。
class RSConv(nn.Module):
'''
Input shape: (B, C_in, npoint, nsample)
Output shape: (B, C_out, npoint)
'''
def __init__(
self,
C_in,
C_out,
activation = nn.ReLU(inplace=True),
mapping = None,
relation_prior = 1,
first_layer = False
):
super(RSConv, self).__init__()
self.bn_rsconv = nn.BatchNorm2d(C_in) if not first_layer else nn.BatchNorm2d(16)
self.bn_channel_raising = nn.BatchNorm1d(C_out)
self.bn_xyz_raising = nn.BatchNorm2d(16)
if first_layer:
self.bn_mapping = nn.BatchNorm2d(math.floor(C_out / 2))
else:
self.bn_mapping = nn.BatchNorm2d(math.floor(C_out / 4))
self.activation = activation
self.relation_prior = relation_prior
self.first_layer = first_layer
self.mapping_func1 = mapping[0]
self.mapping_func2 = mapping[1]
self.cr_mapping = mapping[2]
if first_layer:
self.xyz_raising = mapping[3]
def forward(self, input): # input: (B, 3 + 3 + C_in, npoint, centroid + nsample)
# (B, C_in, npoint, nsample+1), input features
x = input[:, 3:, :, :]
C_in = x.size()[1]
nsample = x.size()[3]
if self.relation_prior == 2:
abs_coord = input[:, 0:2, :, :]
delta_x = input[:, 3:5, :, :]
zero_vec = Variable(torch.zeros(x.size()[0], 1, x.size()[2], nsample).cuda())
else:
abs_coord = input[:, 0:3, :, :] # (B, 3, npoint, nsample+1), absolute coordinates
delta_x = input[:, 3:6, :, :] # (B, 3, npoint, nsample+1), normalized coordinates
# (B, 3, npoint, nsample), centroid point
coord_xi = abs_coord[:, :, :, 0:1].repeat(1, 1, 1, nsample)
h_xi_xj = torch.norm(delta_x, p = 2, dim = 1).unsqueeze(1)
# h_xi_xj size=(B, 10, npoint, nsample)
if self.relation_prior == 1:
h_xi_xj = torch.cat((h_xi_xj, coord_xi, abs_coord, delta_x), dim = 1)
elif self.relation_prior == 2:
h_xi_xj = torch.cat((h_xi_xj, coord_xi, zero_vec, abs_coord, zero_vec, delta_x, zero_vec), dim = 1)
del coord_xi, abs_coord, delta_x
# 使用预先定义好的mapping layers以及batch_norm层和activation function将feature映射到高维空间处理
h_xi_xj = self.mapping_func2(self.activation(self.bn_mapping(self.mapping_func1(h_xi_xj))))
if self.first_layer:
x = self.activation(self.bn_xyz_raising(self.xyz_raising(x)))
x = F.max_pool2d(self.activation(self.bn_rsconv(torch.mul(h_xi_xj, x))), kernel_size = (1, nsample)).squeeze(3) # (B, C_in, npoint)
del h_xi_xj
x = self.activation(self.bn_channel_raising(self.cr_mapping(x)))
return x
class RSConvLayer(nn.Sequential):
def __init__(
self,
in_size: int,
out_size: int,
activation=nn.ReLU(inplace=True),
conv=RSConv,
mapping = None,
relation_prior = 1,
first_layer = False
):
super(RSConvLayer, self).__init__()
conv_unit = conv(
in_size,
out_size,
activation = activation,
mapping = mapping,
relation_prior = relation_prior,
first_layer = first_layer
)
self.add_module('RS_Conv', conv_unit)
class SharedRSConv(nn.Sequential):
def __init__(
self,
args: List[int],
*,
activation=nn.ReLU(inplace=True),
mapping = None,
relation_prior = 1,
first_layer = False
):
super().__init__()
for i in range(len(args) - 1):
self.add_module(
'RSConvLayer{}'.format(i),
RSConvLayer(
args[i],
args[i + 1],
activation = activation,
mapping = mapping,
relation_prior = relation_prior,
first_layer = first_layer
)
)
GloAvgConv
Conv2d+BatchNorm2d+acitvation function(ReLU)+max_pool2d
class GloAvgConv(nn.Module):
'''
Input shape: (B, C_in, 1, nsample)
Output shape: (B, C_out, npoint)
'''
def __init__(
self,
C_in,
C_out,
init=nn.init.kaiming_normal,
bias = True,
activation = nn.ReLU(inplace=True)
):
super(GloAvgConv, self).__init__()
self.conv_avg = nn.Conv2d(in_channels = C_in, out_channels = C_out, kernel_size = (1, 1),
stride = (1, 1), bias = bias)
self.bn_avg = nn.BatchNorm2d(C_out)
self.activation = activation
init(self.conv_avg.weight)
if bias:
nn.init.constant(self.conv_avg.bias, 0)
def forward(self, x):
nsample = x.size()[3]
x = self.activation(self.bn_avg(self.conv_avg(x)))
x = F.max_pool2d(x, kernel_size = (1, nsample)).squeeze(3)
return x
GroupAll
rscnn_msn_seg.py的模型中,该层用于把xyz和feature concate到一起,返回一个shape为[B,3+C,1,N]的tensor。
class GroupAll(nn.Module):
def __init__(self, use_xyz: bool = True):
super().__init__()
self.use_xyz = use_xyz
def forward(
self,
xyz: torch.Tensor,
new_xyz: torch.Tensor,
features: torch.Tensor = None
) -> Tuple[torch.Tensor]:
r"""
Parameters
xyz : xyz coordinates of the features (B, N, 3)
new_xyz : Ignored
features : Descriptors of the features (B, C, N)
Returns
new_features : (B, C + 3, 1, N) tensor
"""
# grouped_xyz shape=[B,3,N]
grouped_xyz = xyz.transpose(1, 2).unsqueeze(2)
if features is not None:
grouped_features = features.unsqueeze(2)
if self.use_xyz:
# new_features shape = [B, 3 + C, 1, N]
new_features = torch.cat([grouped_xyz, grouped_features],dim=1)
else:
# new_features shape = [B, C, 1, N]
new_features = grouped_features
else:
# new_features shape = [B, 3, 1, N]
new_features = grouped_xyz
return new_features
DensePoint
DensePoint
DensePoint: Learning Densely Contextual Representation for Efficient Point Cloud Processing
Motivation:引入上下文信息(多尺度的信息)可以更好的对目标的pattern进行识别。
Context:potential semantic dependencies between a target pattern and its surroundings.
最直接的做法是使用多尺度学习,但像PointNet++使用的多尺度学习,参数量、Flops会增加,一般最多会做到三个尺度。从我们的认识逻辑上来讲,不同尺度的信息反应的语义程度是不同的,而在同层进行多尺度的学习得到的是同一层的semantic level,而不是不同级别的semantic level。
作者希望能够聚集如下图中所示的多个上下文信息来进行识别。


在进行实现时,参考了DenseNet的做法,将不同层的不同感受野处理得到的信息进行aggregation,并使用filter grouping来增强卷积PConv的效果。


最后在Model40、Model10的classification效果还不错,对于噪声和信息丢失具有很好的鲁棒性。

源码学习
densepoint_cls_L6_k24_g2.py
DensePoint的分类网络结构设计部分,主要包括两个stage、一个global pooling模块以及最后的全连接层模块,stage1包含一层PointnetSAModuleMSG,stage2包含4层PointnetSAModuleMSG,global pooling包含一层PointnetSAModule,最后的FC_layer包括3层全连接层,层与层之间添加了dropout。
因为在设置PointnetSAModuleMSG层时,使用的conv操作视参数设置而定,根据参数的设定,stage1只包含一层PointConv层(ppools),在stage2中,第一层PointnetSAModuleMSG同样使用了PointConv层,此后的三层使用了EnhancedPointConv操作(pconvs),global pooling使用的则是GloAvgConv层。PointConv、EnhancedPointConv、GloAvgConv和FC的细节定义在pytorch_utils.py中。
# DensePoint: 2 PPools + 3 PConvs + 1 global pool;
class DensePoint(nn.Module):
r"""
PointNet2 with multi-scale grouping
Semantic segmentation network that uses feature propogation layers
Parameters
----------
num_classes: int
Number of semantics classes to predict over -- size of softmax classifier that run for each point
input_channels: int = 6
Number of input channels in the feature descriptor for each point. If the point cloud is Nx9, this
value should be 6 as in an Nx9 point cloud, 3 of the channels are xyz, and 6 are feature descriptors
use_xyz: bool = True
Whether or not to use the xyz position of a point as a feature
"""
def __init__(self, num_classes, input_channels=0, use_xyz=True):
super().__init__()
self.SA_modules = nn.ModuleList()
# stage 1 begin
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=512,
radii=[0.25],
nsamples=[64],
mlps=[[input_channels, 96]],
use_xyz=use_xyz,
pool=True
)
)
# stage 1 end
# stage 2 begin
input_channels = 96
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=128,
radii=[0.32],
nsamples=[64],
mlps=[[input_channels, 93]],
use_xyz=use_xyz,
pool=True
)
)
input_channels = 93
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=128,
radii=[0.39],
nsamples=[16],
mlps=[[input_channels, 96]],
group_number=2,
use_xyz=use_xyz,
after_pool=True
)
)
input_channels = 117
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=128,
radii=[0.39],
nsamples=[16],
mlps=[[input_channels, 96]],
group_number=2,
use_xyz=use_xyz
)
)
input_channels = 141
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=128,
radii=[0.39],
nsamples=[16],
mlps=[[input_channels, 96]],
group_number=2,
use_xyz=use_xyz,
before_pool=True
)
)
# stage 2 end
# global pooling
input_channels = 165
self.SA_modules.append(
PointnetSAModule(
mlp=[input_channels, 512], use_xyz=use_xyz
)
)
self.FC_layer = nn.Sequential(
pt_utils.FC(512, 512, activation=nn.ReLU(inplace=True), bn=True),
nn.Dropout(p=0.5),
pt_utils.FC(512, 256, activation=nn.ReLU(inplace=True), bn=True),
nn.Dropout(p=0.5),
pt_utils.FC(256, num_classes, activation=None)
)
def _break_up_pc(self, pc):
xyz = pc[..., 0:3].contiguous()
features = (
pc[..., 3:].transpose(1, 2).contiguous()
if pc.size(-1) > 3 else None
)
return xyz, features
def forward(self, pointcloud: torch.cuda.FloatTensor):
r"""
Forward pass of the network
Parameters
----------
pointcloud: Variable(torch.cuda.FloatTensor)
(B, N, 3 + input_channels) tensor
Point cloud to run predicts on
Each point in the point-cloud MUST
be formated as (x, y, z, features...)
"""
xyz, features = self._break_up_pc(pointcloud)
for module in self.SA_modules:
xyz, features = module(xyz, features)
return self.FC_layer(features.squeeze(-1))
pointnet2_modules.py
PointnetSAModuleMSG、PointnetSAModule以及PointnetFPModule的具体实现。在此前Relation-Shape CNN的实现上做了修改,_PointnetSAModuleBase、PointnetSAModule、PointnetFPModule与Relation-Shape CNN的实现相比没有什么变化,主要的修改在PointnetSAModuleMSG部分,根据参数设置来设置添加的是PointConv、EnhancedPointConv、GloAvgConv中的那一层。
class PointnetSAModuleMSG(_PointnetSAModuleBase):
r"""Pointnet set abstrction layer with multiscale grouping
Parameters
npoint : Number of points
radii : list of radii to group with
nsamples : Number of samples in each ball query
mlps : Spec of the pointnet before the global max_pool for each scale
bn : bool, Use batchnorm
"""
def __init__(
self,
*,
npoint: int,
radii: List[float],
nsamples: List[int],
mlps: List[List[int]],
group_number = 1,
use_xyz: bool = True,
pool: bool = False,
before_pool: bool = False,
after_pool: bool = False,
bias = True,
init = nn.init.kaiming_normal
):
super().__init__()
assert len(radii) == len(nsamples) == len(mlps)
self.pool = pool
self.npoint = npoint
self.groupers = nn.ModuleList()
self.mlps = nn.ModuleList()
if pool:
# 定义和初始化pintconv操作
C_in = (mlps[0][0] + 3) if use_xyz else mlps[0][0]
C_out = mlps[0][1]
pconv = nn.Conv2d(in_channels = C_in, out_channels = C_out, kernel_size = (1, 1),
stride = (1, 1), bias = bias)
init(pconv.weight)
if bias:
nn.init.constant(pconv.bias, 0)
convs = [pconv]
# 根据输入条件设置卷积操作
for i in range(len(radii)):
radius = radii[i]
nsample = nsamples[i]
self.groupers.append(
pointnet2_utils.QueryAndGroup(radius, nsample, use_xyz=use_xyz)
if npoint is not None else pointnet2_utils.GroupAll(use_xyz)
)
mlp_spec = mlps[i]
if use_xyz:
mlp_spec[0] += 3
if npoint is None:
self.mlps.append(pt_utils.GloAvgConv(C_in = mlp_spec[0], C_out = mlp_spec[1]))
elif pool:
self.mlps.append(pt_utils.PointConv(C_in = mlp_spec[0], C_out = mlp_spec[1], convs = convs))
else:
self.mlps.append(pt_utils.EnhancedPointConv(C_in = mlp_spec[0], C_out = mlp_spec[1], group_number = group_number, before_pool = before_pool, after_pool = after_pool))
pytorch_utils.py
PointConv、EnhancedPointConv、GloAvgConv等的具体操作。GloAvgConv与Relation-shape CNN中一样,没有变化。
PointConv
PointConv比较简单,根据传入的预先设定参数convs来处理,结构是convs+batchnorm2d+activation function(ReLU)+max pooling
class PointConv(nn.Module):
'''
Input shape: (B, C_in, npoint, nsample)
Output shape: (B, C_out, npoint)
'''
def __init__(self, C_in, C_out, convs=None):
super(PointConv, self).__init__()
self.bn = nn.BatchNorm2d(C_out)
self.activation = nn.ReLU(inplace=True)
self.pconv = convs[0]
def forward(self, x): # x: (B, C_in, npoint, nsample)
nsample = x.size(3)
x = self.activation(self.bn(self.pconv(x)))
return F.max_pool2d(x, kernel_size = (1, nsample)).squeeze(3)
EnhancedPointConv
每次通过conv层来从输入点中获得特征,并与此前的得到的特征concat到一起。cls模型中共设置了3次EnhancedPointConv,更加直观的操作方式可以参考上文中的figure3和其上方的图。
class EnhancedPointConv(nn.Module):
'''
Input shape: (B, C_in, npoint, nsample)
Output shape: (B, C_out, npoint)
'''
def __init__(self, C_in, C_out, group_number=1, before_pool=False, after_pool=False, init=nn.init.kaiming_normal, bias=True):
super(EnhancedPointConv, self).__init__()
self.before_pool, self.after_pool = before_pool, after_pool
C_small = math.floor(C_out/4)
self.conv_phi = nn.Conv2d(in_channels = C_in, out_channels = C_out, groups = group_number, kernel_size = (1, 1),
stride = (1, 1), bias = bias) # ~\phi function: grouped version
self.conv_psi = nn.Conv1d(in_channels = C_out, out_channels = C_small, kernel_size = 1,
stride = 1, bias = bias) # \psi function
# 如果是在pool层之后h或者之前需要添加一次batch_norm
if not after_pool:
self.bn_cin = nn.BatchNorm2d(C_in)
self.bn_phi = nn.BatchNorm2d(C_out)
if before_pool:
self.bn_concat = nn.BatchNorm1d(C_in-3+C_small)
self.activation = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(p=0.2)
init(self.conv_phi.weight)
init(self.conv_psi.weight)
if bias:
nn.init.constant(self.conv_phi.bias, 0)
nn.init.constant(self.conv_psi.bias, 0)
def forward(self, input): # x: (B, C_in, npoint, nsample)
# input[0]为本次最远点采样得到的点的xyz,input[1]为上次一操作得到的特征
x, last_feat = input[0], input[1]
nsample = x.size(3)
# 如果该层在pool操作之后前需要添加一次batch_norm操作
if not self.after_pool:
x = self.activation(self.bn_cin(x))
# 通过两次卷积操作得到新的特征,并与此前的特征concat到一起作为下一次的输入特征
x = self.activation(self.bn_phi(self.conv_phi(x)))
x = F.max_pool2d(x, kernel_size=(1, nsample)).squeeze(3)
x = torch.cat((last_feat, self.dropout(self.conv_psi(x))), dim=1)
# 如果是在pool操作之前也需要进行一次batch_norm操作
if self.before_pool:
x = self.activation(self.bn_concat(x))
return x
FC
class FC(nn.Sequential):
def __init__(
self,
in_size: int,
out_size: int,
*,
activation=nn.ReLU(inplace=True),
bn: bool = False,
init=None,
preact: bool = False,
name: str = ""
):
super().__init__()
fc = nn.Linear(in_size, out_size, bias=not bn)
if init is not None:
init(fc.weight)
if not bn:
nn.init.constant(fc.bias, 0)
if preact:
if bn:
self.add_module(name + 'bn', BatchNorm1d(in_size))
if activation is not None:
self.add_module(name + 'activation', activation)
self.add_module(name + 'fc', fc)
if not preact:
if bn:
self.add_module(name + 'bn', BatchNorm1d(out_size))
if activation is not None:
self.add_module(name + 'activation', activation)
点云处理存在的问题
- 在百万点云数据上的高效处理
- 多传感器数据的结合(2D、3D数据)
- 高精度识别
- 鲁棒性
研究方向
- 几何深度学习(geometric DL)、segmentation、detection、completion(补全)、registration(配准)
- capsule、GAN、one-shot/zero-shot、meta-learning、NAS
参考:
bilibili: 中科院模式识别国家重点实验室在读博士生刘永成:深度学习在3D点云处理中的探索
github: yongchengliu