TF使用ANN(artificial neural network)
简介
- 受到生物神经网络的启发
- 发展历史
- 生物神经网络单元
- 逻辑运算单元:and、or、xor等运算
- 感知机(perceptron): hw(x)=step(wT⋅x)
- 多层感知机和反向传播(multi-perceptron and backpropagation)
perceptron
多层感知机和反向传播
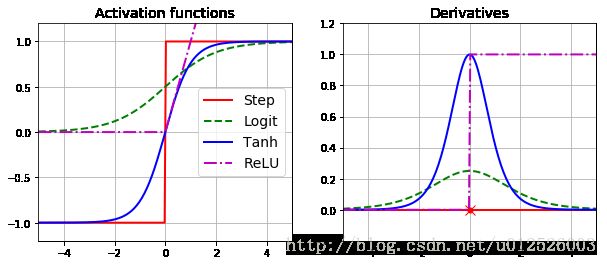
- 感知机的激活函数是step函数,得到的结果非0即1,无法用于反向传播(需要求取微分),因此利用Logistic函数 σ(z)=1/(1+exp(−z)) 替代之前的step函数,这个logistic函数也被称为激活函数
- 常用的激活函数有
- logistic函数
- 双曲正切函数: tanh(z)=2σ(2z)−1
- RELU函数: relu(z)=max(z,0) ,RELU函数在 z=0 处不可导,但是由于它计算耗时十分短,在实际应用中应用很广泛,同时它也没有最大值的限制,可以减少GD使用过程中的一些问题
- softmax函数
- MLP常常用于分类,输出层常常用softmax函数作为激活函数,可以保证所有节点的输出之和为1,相当于每个节点的输出值都是这个节点的概率,softmax函数如下
σ(z)j=ezj∑Kk=1ezk
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import os
gpu_options = tf.GPUOptions(allow_growth=True)
def reset_graph(seed=42):
tf.reset_default_graph()
tf.set_random_seed(seed)
np.random.seed(seed)
return
with tf.Session( config=tf.ConfigProto(gpu_options=gpu_options) ) as sess:
print( sess.run( tf.constant(1) ) )
1
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
iris = load_iris()
X = iris.data[:, (2,3)]
y = (iris.target ==0 ).astype( np.int )
per_clf = Perceptron( random_state=42 )
per_clf.fit(X, y)
y_pred = per_clf.predict( [[2, 0.5]] )
print( y_pred )
[1]
def logit(z):
return 1 / (1 + np.exp(-z))
def relu(z):
return np.maximum(0, z)
def derivative(f, z, eps=0.000001):
return (f(z + eps) - f(z - eps))/(2 * eps)
z = np.linspace(-5, 5, 200)
plt.figure(figsize=(10,4))
plt.subplot(121)
plt.plot(z, np.sign(z), "r-", linewidth=2, label="Step")
plt.plot(z, logit(z), "g--", linewidth=2, label="Logit")
plt.plot(z, np.tanh(z), "b-", linewidth=2, label="Tanh")
plt.plot(z, relu(z), "m-.", linewidth=2, label="ReLU")
plt.grid(True)
plt.legend(loc="center right", fontsize=14)
plt.title("Activation functions", fontsize=14)
plt.axis([-5, 5, -1.2, 1.2])
plt.subplot(122)
plt.plot(z, derivative(np.sign, z), "r-", linewidth=2, label="Step")
plt.plot(0, 0, "ro", markersize=5)
plt.plot(0, 0, "rx", markersize=10)
plt.plot(z, derivative(logit, z), "g--", linewidth=2, label="Logit")
plt.plot(z, derivative(np.tanh, z), "b-", linewidth=2, label="Tanh")
plt.plot(z, derivative(relu, z), "m-.", linewidth=2, label="ReLU")
plt.grid(True)
plt.title("Derivatives", fontsize=14)
plt.axis([-5, 5, -0.2, 1.2])
plt.show()
使用MLP进行训练
- TF中集成了MLP的库,在tf.learn中
- 下面是一个MLP训练的例子
- 其中
infer_real_valued_columns_from_input是根据输入的数据推断出数据的类型以及数据特征的维度等信息,参考链接:http://www.cnblogs.com/wxshi/p/8053973.html
from tensorflow.examples.tutorials.mnist import input_data
from sklearn.metrics import accuracy_score
mnist = input_data.read_data_sets("dataset/mnist")
X_train = mnist.train.images
X_test = mnist.test.images
y_train = mnist.train.labels.astype("int")
y_test = mnist.test.labels.astype("int")
feature_cols = tf.contrib.learn.infer_real_valued_columns_from_input(X_train)
dnn_clf = tf.contrib.learn.DNNClassifier( hidden_units=[300,100], n_classes=10, feature_columns=feature_cols, model_dir="./models/mnist/" )
dnn_clf.fit( x=X_train, y=y_train, batch_size=2000,steps=1000 )
y_pred = list( dnn_clf.predict(X_test) )
print( "accuracy : ", accuracy_score(y_test, y_pred) )
Extracting dataset/mnist/train-images-idx3-ubyte.gz
Extracting dataset/mnist/train-labels-idx1-ubyte.gz
Extracting dataset/mnist/t10k-images-idx3-ubyte.gz
Extracting dataset/mnist/t10k-labels-idx1-ubyte.gz
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_task_type': None, '_task_id': 0, '_cluster_spec': , '_master': '', '_num_ps_replicas': 0, '_num_worker_replicas': 0, '_environment': 'local', '_is_chief': True, '_evaluation_master': '', '_tf_config': gpu_options {
per_process_gpu_memory_fraction: 1.0
}
, '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_secs': 600, '_log_step_count_steps': 100, '_session_config': None, '_save_checkpoints_steps': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_model_dir': './models/mnist/'}
INFO:tensorflow:Create CheckpointSaverHook.
INFO:tensorflow:Restoring parameters from ./models/mnist/model.ckpt-1000
INFO:tensorflow:Saving checkpoints for 1001 into ./models/mnist/model.ckpt.
INFO:tensorflow:loss = 0.11683539, step = 1001
INFO:tensorflow:global_step/sec: 110.226
INFO:tensorflow:loss = 0.10939115, step = 1101 (0.908 sec)
INFO:tensorflow:global_step/sec: 111.916
INFO:tensorflow:loss = 0.082077585, step = 1201 (0.894 sec)
INFO:tensorflow:global_step/sec: 108.765
INFO:tensorflow:loss = 0.089471206, step = 1301 (0.920 sec)
INFO:tensorflow:global_step/sec: 121.815
INFO:tensorflow:loss = 0.073814414, step = 1401 (0.820 sec)
INFO:tensorflow:global_step/sec: 106.326
INFO:tensorflow:loss = 0.067025915, step = 1501 (0.940 sec)
INFO:tensorflow:global_step/sec: 125.559
INFO:tensorflow:loss = 0.07670402, step = 1601 (0.796 sec)
INFO:tensorflow:global_step/sec: 118.059
INFO:tensorflow:loss = 0.060902975, step = 1701 (0.848 sec)
INFO:tensorflow:global_step/sec: 107.56
INFO:tensorflow:loss = 0.057678875, step = 1801 (0.929 sec)
INFO:tensorflow:global_step/sec: 109.521
INFO:tensorflow:loss = 0.074146144, step = 1901 (0.913 sec)
INFO:tensorflow:Saving checkpoints for 2000 into ./models/mnist/model.ckpt.
INFO:tensorflow:Loss for final step: 0.057994846.
INFO:tensorflow:Restoring parameters from ./models/mnist/model.ckpt-2000
accuracy : 0.9747
TF构建DNN
- 初始化训练参数时,参数初始值可以设置为符合标准差为 2/ninputs−−−−−√ 的截断正态分布的随机数,这可以加快模型收敛的速度。在TF里,截断的最大值和最小值分别是2和-2。
from tensorflow.contrib.layers import fully_connected
reset_graph()
n_inputs = 28*28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
X = tf.placeholder( tf.float32, shape=(None, n_inputs), name="X" )
y = tf.placeholder( tf.int64, shape=(None), name="y" )
def neuron_layer(X, n_neurons, name, activation=None):
with tf.name_scope( name ):
n_inputs = int(X.shape[1])
sttdev = 2 / np.sqrt( n_inputs )
init = tf.truncated_normal( (n_inputs, n_neurons), sttdev=stddev )
W = tf.Variable( init, name="weights" )
b = tf.Variable( tf.zeros([n_neurons]), name="bias" )
z = tf.matmul( X, W ) + b
if activation == "relu":
return tf.nn.relu( z )
else:
return z
with tf.name_scope("dnn"):
hidden1 = fully_connected(X, n_hidden1, scope="hidden1")
hidden2 = fully_connected(hidden1, n_hidden2, scope="hidden2")
logits = fully_connected( hidden2, n_outputs, scope="outputs", activation_fn=None )
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits( labels=y, logits=logits )
loss = tf.reduce_mean( xentropy, name="loss" )
lr = 0.01
with tf.name_scope( "train" ):
optimizer = tf.train.GradientDescentOptimizer( lr )
training_op = optimizer.minimize( loss )
with tf.name_scope( "eval" ):
correct = tf.nn.in_top_k( logits, y, 1 )
accuracy = tf.reduce_mean( tf.cast( correct, tf.float32 ) )
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 30
batch_size = 200
with tf.Session() as sess:
init.run()
for epoch in range( n_epochs ):
for iteration in range( X_train.shape[0] // batch_size ):
X_batch, y_batch = mnist.train.next_batch( batch_size )
sess.run( training_op, feed_dict={X:X_batch, y:y_batch} )
acc_train = accuracy.eval( feed_dict={X:X_batch, y:y_batch} )
acc_test = accuracy.eval( feed_dict={X:X_test, y:y_test} )
print( epoch, "train accuracy : ", acc_train, "; Test accuracy : ", acc_test )
save_path = saver.save( sess, "./models/mnist/my_model_final.ckpt" )
0 train accuracy : 0.82 ; Test accuracy : 0.8298
1 train accuracy : 0.89 ; Test accuracy : 0.8783
2 train accuracy : 0.88 ; Test accuracy : 0.8977
3 train accuracy : 0.885 ; Test accuracy : 0.9043
4 train accuracy : 0.925 ; Test accuracy : 0.9104
5 train accuracy : 0.9 ; Test accuracy : 0.9143
6 train accuracy : 0.915 ; Test accuracy : 0.9204
7 train accuracy : 0.925 ; Test accuracy : 0.9224
8 train accuracy : 0.93 ; Test accuracy : 0.9246
9 train accuracy : 0.925 ; Test accuracy : 0.9283
10 train accuracy : 0.92 ; Test accuracy : 0.9297
11 train accuracy : 0.91 ; Test accuracy : 0.9316
12 train accuracy : 0.95 ; Test accuracy : 0.933
13 train accuracy : 0.93 ; Test accuracy : 0.9356
14 train accuracy : 0.94 ; Test accuracy : 0.9373
15 train accuracy : 0.915 ; Test accuracy : 0.9382
16 train accuracy : 0.94 ; Test accuracy : 0.9398
17 train accuracy : 0.965 ; Test accuracy : 0.9415
18 train accuracy : 0.935 ; Test accuracy : 0.9425
19 train accuracy : 0.95 ; Test accuracy : 0.9433
20 train accuracy : 0.925 ; Test accuracy : 0.9447
21 train accuracy : 0.925 ; Test accuracy : 0.9455
22 train accuracy : 0.93 ; Test accuracy : 0.9461
23 train accuracy : 0.91 ; Test accuracy : 0.9484
24 train accuracy : 0.935 ; Test accuracy : 0.9485
25 train accuracy : 0.95 ; Test accuracy : 0.95
26 train accuracy : 0.94 ; Test accuracy : 0.9511
27 train accuracy : 0.93 ; Test accuracy : 0.9531
28 train accuracy : 0.95 ; Test accuracy : 0.9527
29 train accuracy : 0.965 ; Test accuracy : 0.9541
- 如果要使用之前训练的模型进行分类任务,可以直接读取保存的模型文件
with tf.Session() as sess:
saver.restore( sess, "./models/mnist/my_model_final.ckpt" )
X_new_scaled = X_test[:20, :]
Z = logits.eval( feed_dict={X:X_new_scaled} )
y_pred = np.argmax( Z, axis=1 )
print( "real value : ", y_test[0:20] )
print( "predict value :", y_pred[0:20] )
INFO:tensorflow:Restoring parameters from ./models/mnist/my_model_final.ckpt
real value : [7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5 9 7 3 4]
predict value : [7 2 1 0 4 1 4 9 6 9 0 6 9 0 1 5 9 7 3 4]
NN超参数微调
- NN虽然很灵活,但是有许多超参数需要调节,比如隐含层的数量、激活函数等
- 一般情况下,可以首先使用一个隐含层进行训练与测试,得到一个初步结果
- 深层网络比浅层网络在参数调节方面要更加灵活,它们可以使用更少的节点个数,对更加复杂的函数进行建模。
- 训练的过程中,可以逐步增加隐含层的数目,得到更加复杂的网络
- 输入和输出层的神经元节点个数是由输入和输出确定的,对于mnist,输入层有784个节点(特征数目),输出层有10个节点(类别个数)
- 一般情况下,可以逐步增加隐含层中神经元节点的数量,直到模型发生过拟合;另外一种比较常用的方法是:选择很大的神经元节点个数,然后利用early stopping方法进行训练,得到最优的模型
- 一般情况下,使用RELU作为激活函数就可以达到比较好的结果,因为它的计算速度很快,同时也不会因为输入值过大而饱和;在输出层,只要输出的类别之间相互排斥,则softmax函数一般即可