【今日CV 计算机视觉论文速览 第133期】Wed, 19 Jun 2019
今日CS.CV 计算机视觉论文速览
Wed, 19 Jun 2019
Totally 39 papers
?上期速览✈更多精彩请移步主页
??????
?小尝试:?留言 邮箱地址及时获悉论文速览

Interesting:
?基于人体姿势生成时尚衣着图像, 提出了一种将主体的时尚图像从某个姿势迁移到新的体态姿势上去。这一模型包含了两个判别器和一个生成器。其中生成器包含了姿势编码器、图像编码器以及对应的解码器,两个编码器得到的特征表达将被用于新图像合成。与传统方法不同的是两个判别器用于指导模型学习,一个用于判别生成图像与训练样本,领域各用于验证生成图像与姿势间的连续性。(from 北卡大学 JD OPPO)
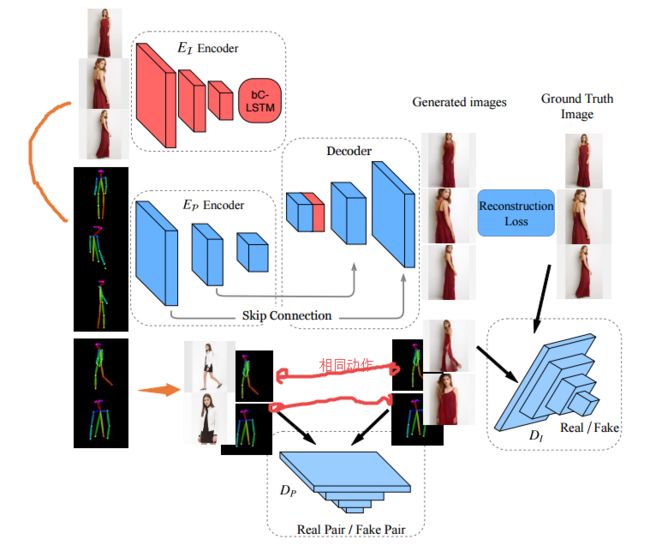
姿势的编码器Dp保证了生成图像姿势的连续性!
与相关方法的比较:
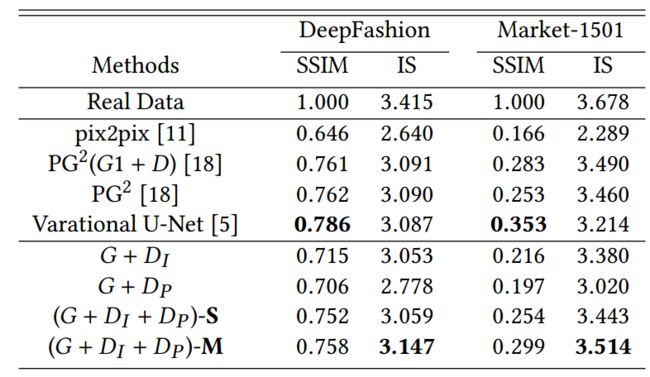
得到的结果:

dataset: DeepFashion [16] and Market-1501 [37].
ref:时尚相关的图像任务smart photo editing, movie making, virtual try-on, and fashion display
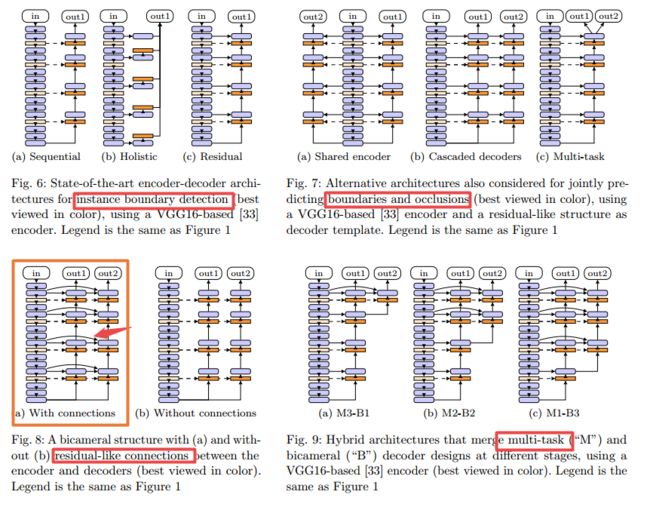
?合成数据用于预测密集堆叠相似物体的边界, 边界方向检测主要通过预测任一类别实例的边界和对应的遮挡部分来实现,研究人员提出了共享编码器的两个解码器架构,从单张RGB中同时预测出边界和未遮挡面。研究人员还合成了Mikado数据集来评测物体间相互遮挡的情况(from France ´Universit´e de Lyon)
得到的结果和对应的模型,共享编码器的两个解码器和之间的额调节层共享信息。

使用的数据集和其中互相遮挡的物体:
构建数据的过程,在边界处高的设为1低的设为0,得到了上下物体的朝向:

用于合成数据的材质和背景:

各种不同模型的变种:
ref:
Oriented Edge Forests for Boundary Detection
https://github.com/samhallman/oef
edge detection ref:
R. Deng, C. Shen, S. Liu, H. Wang, X. Liu, Learning to Predict Crisp Boundaries, in ECCV 18
Y. Wang, X. Zhao, K. Huang, Deep Crisp Boundaries, in CVPR (IEEE Computer Society, 2017), Convolutional Features for Edge Detection
J. Yang, B.L. Price, S. Cohen, H. Lee, M.H. Yang, Object Contour Detection with a Fully Convolutional EncoderDecoder Network, in CVPR (IEEE Computer Society, 2016),
O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional Networks for Biomedical Image Segmentation
S. Xie, Z. Tu, Holistically-Nested Edge Detection, in ICCV15
?DeepView新视角合成方法,基于学习到的梯度下降, 通过稀疏的视点和多平面图像(multiplane image ,MPI,不同深度的图像层)),研究人员在学习到的梯度下降方法上提出了新的视角合成方法,可以有效处理物体边界、遮挡、光反射、薄壁结构、深度复杂等场景。(from 谷歌)
通过重建和梯度下降来得到MPI图像,最后既可以渲染出不同视角的图像:
gradients have a particularly intuitive form in that they encode the visibility information between the input views and the MPI layers! MPI render image!
可学习的梯度下降过程,基于初始化的MPI不断利用相同结构的CNN,根据计算出的梯度来更新MPI:
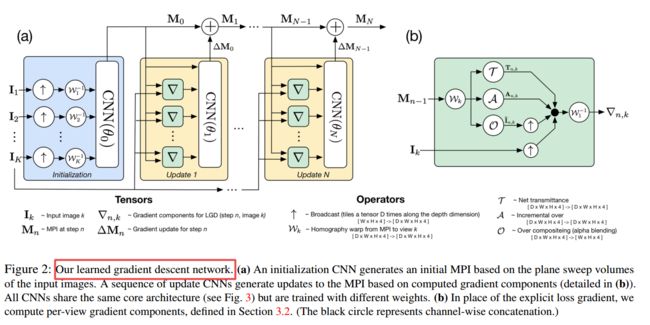
更新CNN的架构如下:
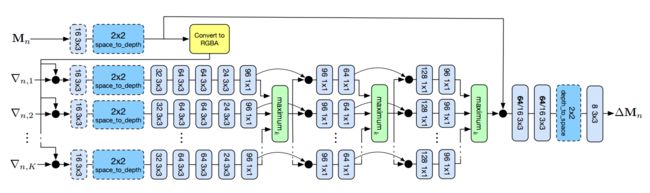
得到的合成视角结果:
dataset:Spaces
web:https://augmentedperception.github.io/deepview/
ref:learned gradient descent:https://github.com/adler-j/learned_gradient_tomography
++paper:https://arxiv.org/pdf/1704.04058.pdf
?三维几何隐含模式分析和三维Mesh, 提出了基于mesh的几何纹理分析,将用户尺度和3Dmesh作为输入,并生成基于相似度的纹理聚类,和有意义的分类。不同尺度对于特征的描述和抽取是不同的,通过用户定义的尺度来分割和抽取并分类几何纹理。(from Clermont Universit´e, Universit´e d’Auvergne)
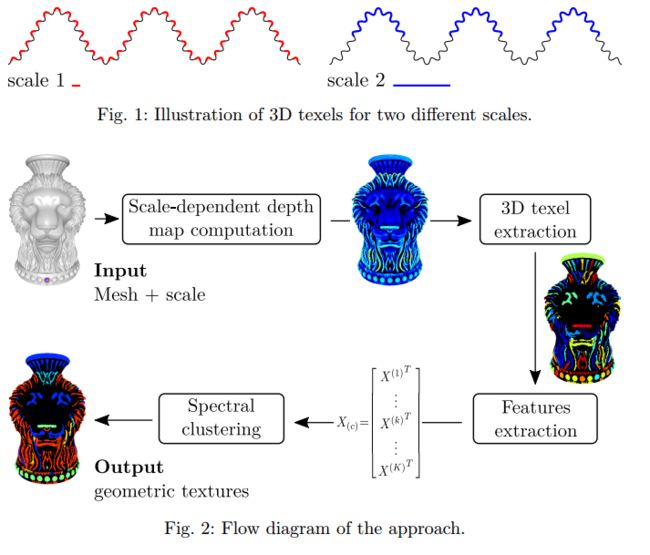
code:https://github.com/AliceOTHMANI/3D-Geometric-Texture-Segmentation
Daily Computer Vision Papers
| **Weather Influence and Classification with Automotive Lidar Sensors Authors Robin Heinzler, Philipp Schindler, J rgen Seekircher, Werner Ritter, Wilhelm Stork 激光雷达传感器通常用于移动机器人和自动驾驶车辆,以补充摄像机,雷达和超声波传感器以获得环境感知。通常,感知算法被训练为仅检测移动和静态对象以及地面估计,但故意忽略天气效应以减少错误检测。在这项工作中,我们对恶劣天气条件下的汽车激光雷达性能进行了深入分析,即大雨和浓雾。已经记录了针对各种雾和雨条件的大量数据集,这是在不断变化的环境条件下对点云进行深度分析的基础。此外,我们介绍了一种仅用激光雷达传感器检测和分类雨或雾的新方法,并在受控环境中实现了数据集97.14的交叉平均联合。天气对激光雷达传感器性能的影响分析和天气检测是提高可靠信息以适应车辆行为的重要步骤,旨在提高恶劣天气条件下自动驾驶的安全水平。 |
| ***ADA-Tucker: Compressing Deep Neural Networks via Adaptive Dimension Adjustment Tucker Decomposition Authors Zhisheng Zhong, Fangyin Wei, Zhouchen Lin, Chao Zhang 尽管最近在许多应用中成功地使用了深度学习模型,但是它们在移动设备上的广泛使用受到存储和计算要求的严重阻碍。在本文中,我们提出了一种新的网络压缩方法,称为自适应尺寸调整Tucker分解ADA Tucker。借助可学习的核心张量和变换矩阵,ADA Tucker执行任意阶数张量的Tucker分解。此外,我们建议在具有适当顺序和平衡维度的网络中的权重张量更容易压缩。因此,分解选择的高度灵活性将ADA Tucker与之前的所有低级别模型区分开来。为了压缩更多,我们通过为所有层定义共享核心张量,进一步将模型扩展到Shared Core ADA Tucker SCADA Tucker。我们的方法不需要记录非零元素索引的开销。在不损失准确性的情况下,我们的方法分别以691倍和233倍的比率减少LeNet 5和LeNet 300的存储,显着优于现有技术水平。我们的方法的有效性也在其他三个基准CIFAR 10,SVHN,ILSVRC12和现代新深度网络ResNet,Wide ResNet上进行了评估。 |
| A Weakly Supervised Learning Based Clustering Framework Authors Mustafa Umit Oner, Hwee Kuan Lee, Wing Kin Sung 本文提出了一种基于弱监督学习的聚类框架。作为该框架的核心,我们引入了一个基于包级别标签的新型多实例学习任务,称为唯一类计数ucc,它是包中所有实例中唯一类的数量。在此任务中,在模型训练期间不需要对包内的各个实例进行注释。我们在数学上证明了一个完美的ucc分类器,原则上可以用来完美地聚集袋内的个体实例。换句话说,即使在训练期间没有给出关于个体实例的注释,也可以完美地聚类个体实例。我们构建了一个基于神经网络的ucc分类器,并通过实验证明我们的ucc分类器框架的聚类性能与完全监督学习模型的聚类性能相当。我们还观察到,我们的ucc分类器可以潜在地用于零射击学习,因为他们学习更好的语义特征而不是完全监督的模型用于看不见的类,这些模型在训练期间从未输入到模型中。 |
| 3D Geometric salient patterns analysis on 3D meshes Authors Alice Othmani, Fakhri Torkhani, Jean Marie Favreau 模式分析是一个广泛的领域,在许多领域具有广泛的适用性。实际上,纹理分析是这些领域之一,因为纹理被定义为一组重复或准重复模式。尽管在分析三维网格物体方面具有重要意义,但几何处理社区对几何纹理分析的研究较少。本文提出了一种新的三维三角网格几何纹理分析的有效方法。所提出的方法是尺度感知方法,其将3D网格和用户尺度作为输入。因此,它提供了基于相似性的有意义类别中的纹素的聚类。所提出的算法的实验结果被呈现用于各种纹理内的真实世界和合成网格。此外,所提出的方法的效率在网格简化和网格表面上的噪声添加下通过实验证明。在本文中,我们提出了三维几何突出纹理的语义标注的实际应用。 |
| Learning with Average Precision: Training Image Retrieval with a Listwise Loss Authors Jerome Revaud, Jon Almazan, Rafael Sampaio de Rezende, Cesar Roberto de Souza 图像检索可以被表述为排名问题,其目标是通过减少与查询的相似性来对数据库图像进行排序。最近的深度图像检索模型通过利用排序量身定制的损失函数优于传统方法,但仍然存在重要的理论和实际问题。首先,它们不是直接优化全局排名,而是最小化基本损失的上限,这不一定导致最佳平均平均精度mAP。其次,这些方法需要大量的工程努力才能很好地工作,例如特殊的预训练和硬负的采矿。在本文中,我们建议通过利用列表损失公式的最新进展直接优化全球mAP。使用直方图分级近似,可以区分AP,从而用于端到端学习。与现有损失相比,所提出的方法在每次迭代时同时考虑数千个图像,并且消除了对特殊技巧的需要。它还在许多标准检索基准上建立了新的技术水平。模型和评估脚本已在 |
| ***稠密人脸检测Locate, Size and Count: Accurately Resolving People in Dense Crowds via Detection Authors Deepak Babu Sam, Skand Vishwanath Peri, Mukuntha N. S., Amogh Kamath, R. Venkatesh Babu 我们引入了密集人群计数的检测框架,并消除了对普遍密度回归范例的需求。典型的计数模型预测图像的人群密度,而不是检测每个人。通常,这些回归方法无法为除计数以外的大多数应用程序准确地定位人员。因此,我们采用一种架构,定位人群中的每个人,用边界框对斑点头进行大小调整然后对其进行计数。与普通物体或面部检测器相比,在设计这种检测系统时存在某些独特的挑战。其中一些是密集人群中巨大多样性的直接后果,同时需要连续预测盒子。我们解决了这些问题并开发了我们的LSC CNN模型,该模型可以可靠地检测稀疏人群中的人群。 LSC CNN采用多列体系结构,具有自上而下的反馈处理功能,可以更好地解决人员并在多种分辨率下生成精确的预测。有趣的是,建议的训练方案仅需要点头注释,但可以估计头部的近似大小信息。我们表明LSC CNN不仅具有优于现有密度回归器的定位,而且在计数方面也表现优异。我们的方法代码可在以下网址找到 |
| Impoved RPN for Single Targets Detection based on the Anchor Mask Net Authors Mingjie Li, Youqian Feng, Zhonghai Yin, Cheng Zhou, Fanghao Dong 共同目标检测通常基于单帧图像,其易受图像中类似目标的影响而不适用于视频图像。本文提出了锚定掩模来增加目标检测的先验知识,并设计了锚定掩模网络,以提高单目标检测的RPN性能。经过VOT2016测试,该型号表现更佳。 |
| A One-step Pruning-recovery Framework for Acceleration of Convolutional Neural Networks Authors Dong Wang, Lei Zhou, Xiao Bai, Jun Zhou 在过去的几年中,卷积神经网络的加速受到越来越多的关注。在各种加速技术中,滤波器修剪通过有效减少卷积滤波器的数量而具有其固有的优点。然而,大多数过滤器修剪方法采用冗长且耗时的逐层修剪恢复策略以避免显着的精度下降。在本文中,我们提出了一个有效的过滤器修剪框架来解决这个问题。我们的方法通过一种新颖的优化目标函数以一步修剪恢复方式加速网络,与现有的修剪方法相比,该方法实现了更高的精度和更低的成本。此外,我们的方法允许使用全局过滤器修剪进行网络压缩。给定全局修剪速率,它可以自适应地确定每个单个卷积层的修剪速率,而这些速率通常在先前的方法中被设置为超参数。使用ImageNet对VGG 16和ResNet 50进行评估,我们的方法优于几种最先进的方法,在相同甚至更少的浮点运算FLOP下,精度下降更少。 |
| Bicameral Structuring and Synthetic Imagery for Jointly Predicting Instance Boundaries and Nearby Occlusions from a Single Image Authors Matthieu Grard imagine , Liming Chen imagine , Emmanuel Dellandr a imagine 定向边界检测是一项具有挑战性的任务,旨在描绘类别不可知对象实例并从单个RGB图像推断其空间布局。用于该任务的现有技术深度卷积网络依赖于分别预测边界和遮挡的两个独立流,尽管两者都需要类似的局部和全局线索,并且遮挡导致边界。因此,我们提出了一种完全卷积的两室结构,由两个共享一个深度编码器的级联解码器组成,通过跳过连接完全链接以组合局部和全局特征,用于联合预测实例边界及其未被遮挡的一侧。此外,现有技术数据集包含具有少量实例和遮挡的真实图像,这主要是由于遮挡背景的对象,从而在实例之间缺少有意义的遮挡。为了评估密集的对象堆的丢失场景,我们引入了合成数据Mikado,其可扩展地包含比PASCAL实例遮挡数据集PIOD,COCO Amodal数据集COCOA和密集分段超市Amodal更多的实例和每个图像的实例间遮挡。数据集D2SA。我们表明,所提出的网络设计优于PIOD和Mikado的定向边界检测的两个流基线和替代方案,以及COCOA上的氨基分割方法。我们在D2SA上的实验也表明,Mikado在某种意义上是合理的,因为它可以学习可转换为真实数据的性能增强表示,同时大大减少了对微调的手工注释的需求。 |
| Locality Preserving Joint Transfer for Domain Adaptation Authors Li Jingjing, Jing Mengmeng, Lu Ke, Zhu Lei, Shen Heng Tao 域适应旨在利用来自良好标记的源域的知识到标记不良的目标域。大多数现有作品在特征级别或样本级别上传输知识。最近的研究表明,两种范式都非常重要,优化其中一种可以强化另一种范式。受此启发,我们提出了一种新方法,通过地标选择共同利用特征适应与分布匹配和样本适应。在知识转移过程中,我们还考虑了样本之间的局部一致性,以便保留样本的流形结构。最后,我们部署标签传播来预测新实例的类别。值得注意的是,我们的方法适用于通过学习领域特定预测进行同构和异构域适应。五个开放基准测试(包括标准数据集和大规模数据集)的大量实验验证了我们的方法不仅可以显着优于传统方法,还可以优于端到端深度模型。实验还表明,我们可以利用手工制作的功能,通过异构适应来提高深度特征的准确性。 |
| Using colorization as a tool for automatic makeup suggestion Authors Shreyank Narayana Gowda 着色是将灰度图像转换为全彩色图像的方法。有多种方法可以做到这一点。旧学校方法使用机器学习算法和优化技术来建议可能使用的颜色。随着深度学习领域的进步,着色结果随着深度学习架构的改进而不断改进。深度学习领域的最新发展是生成对抗性网络GAN的出现,它用于生成信息而不仅仅是预测或分类。作为本报告的一部分,最近的论文的2个架构被复制,同时建议用于一般着色的新颖架构。在此之后,我们建议通过在脸上自动生成化妆建议来使用着色。为此,已创建由1000个图像组成的数据集。当没有化妆的人的图像被发送到模型时,模型首先将图像转换为灰度,然后将其传递给建议的GAN模型。输出是生成的化妆建议。为了开发这个模型,我们需要调整一般的着色模型,只处理人脸。 |
| ***Neural Illumination: Lighting Prediction for Indoor Environments Authors Shuran Song, Thomas Funkhouser 本文讨论了估计从所有方向到达在RGB图像中的所选像素处观察到的3D点的光的任务。此任务具有挑战性,因为它需要预测从相机的部分场景观察到选定位置的完整照明地图的映射,这取决于选择的3D位置,未观察到的光源的分布,由场景引起的遮挡先前的方法试图使用单个黑盒神经网络直接学习这种复杂的映射,这通常无法估计具有复杂3D几何的场景的高频照明细节。相反,我们提出神经照明一种新方法,将照明预测分解为几个更简单的可微分子任务1几何估计,2场景完成和3 LDR到HDR估计。这种方法的优点是子任务相对容易学习,并且可以通过直接监督进行培训,而整个管道完全可以区分,并且可以通过端到端监督进行微调。实验表明,我们的方法在数量和质量上都比以前的工作表现得更好。 |
| A sparse annotation strategy based on attention-guided active learning for 3D medical image segmentation Authors Zhenxi Zhang, Jie Li, Zhusi Zhong, Zhicheng Jiao, Xinbo Gao 三维图像分割是医学图像处理中最重要和最普遍的问题之一。它为准确的疾病诊断,异常检测和分类提供详细的定量分析。目前,深度学习算法被广泛应用于医学图像分割,大多数算法训练具有完全注释数据集的模型。然而,获得医学图像数据集是非常困难和昂贵的,并且3D医学图像的完整注释是单调且耗时的工作。在3D图像中部分标记信息切片将是手动注释的极大缓解。已经在2D图像领域中提出了基于主动学习的样本选择策略,但是很少有策略关注于3D图像。在本文中,我们提出了一种基于注意力引导主动学习的三维医学图像分割稀疏注释策略。注意机制用于提高分割准确度并估计每个切片的分割准确度。使用来自开发人类连接组项目dHCP的数据集的三种不同策略的对比实验表明,我们的策略在脑提取任务中仅需要15至20个注释切片,并且在组织分割任务中需要30至35个注释切片以实现作为完整注释的比较结果。 |
| Neural Multi-Scale Self-Supervised Registration for Echocardiogram Dense Tracking Authors Wentao Zhu, Yufang Huang, Mani A Vannan, Shizhen Liu, Daguang Xu, Wei Fan, Zhen Qian, Xiaohui Xie 超声心动图已经常规用于心肌病和心脏血流异常的诊断。然而,手动测量来自超声心动图的心肌运动和心脏血流是耗时且容易出错的。能够自动跟踪和量化心肌运动和心脏血流的计算机算法受到高度追捧,但由于噪声和超声心动图的高度可变性而未能取得很大成功。在这项工作中,我们提出了一种神经多尺度自监督登记NMSR方法,用于自动心肌和心脏血流密集跟踪。 NMSR结合了两个新颖的组件1,利用深度神经网络来参数化两个图像帧之间的速度场,并且2以连续的多尺度方式优化神经网络的参数以解决速度场内的大的变化。实验证明,对于心肌和心脏血流密集跟踪,NMSR产生比现有技术方法(例如高级标准化工具ANT和VoxelMorph)明显更好的配准精度。我们的方法有望提供一种全自动的方法,用于快速准确地分析超声心动图。 |
| Boosting CNN beyond Label in Inverse Problems Authors Eunju Cha, Jaeduck Jang, Junho Lee, Eunha Lee, Jong Chul Ye 卷积神经网络CNN已被广泛用于逆问题。然而,由于仅使用所选数据训练神经网络并且它们的架构主要被认为是黑盒子,因此难以预先估计它们对于看不见的测试数据的预测误差。这对于无监督学习或超出标签的改进的神经网络提出了根本性挑战。在本文中,我们表明最近的无监督学习方法,如Noise2Noise,Stein s无偏差风险估计器SURE为基础的降噪器,以及Noise2Void在制定预测误差的无偏估计时彼此密切相关,但它们中的每一个都是与其自身的局限性有关。基于这些观察,我们为预测误差提供了一种新颖的增强估计器。特别地,通过采用编码器解码器CNN的组合卷积帧表示并将其与批量归一化协同地组合,我们提供了用于预测误差的无偏估计的紧密形式公式,其可以被最小化以用于超出标签的神经网络训练。实验结果表明,所得到的算法,我们称之为Noise2Boosting,在监督和非监督学习设置下的各种逆问题中提供了一致的改进。 |
| DeepView: View Synthesis with Learned Gradient Descent Authors John Flynn, Michael Broxton, Paul Debevec, Matthew DuVall, Graham Fyffe, Ryan Overbeck, Noah Snavely, Richard Tucker 我们提出了一种使用多平面图像MPI查看合成的新方法。基于学习梯度下降的最新进展,我们的算法从一组稀疏相机视点生成MPI。所得到的方法结合了遮挡推理,提高了具有挑战性的场景特征的性能,例如物体边界,光照反射,薄结构和具有高深度复杂度的场景。我们展示了我们的方法在Kalantari光场数据集的两个数据集上实现了高质量,最先进的结果,以及我们公开提供的新的相机阵列数据集Spaces。 |
| **Using Discriminative Methods to Learn Fashion Compatibility Across Datasets Authors Kedan Li, Chen Liu, Ranjitha Kumar, David Forsyth 确定一对服装是否彼此相容是一个具有挑战性的匹配问题。过去的作品探索了各种嵌入方法来学习这种关系。本文通过将任务公式化为一个简单的二元分类问题,介绍了使用判别方法来学习兼容性。我们使用由非专家创建的既定服装数据集来评估我们的方法,并证明了对现有技术方法的既定指标的改进2.5。我们介绍了三个专业策划服装的新数据集,并展示了我们在专家策划数据集上的一致性能。为了便于比较各个装备数据集,我们提出了一个新的度量标准,与以前使用的度量标准不同,它不会受到服装平均大小的偏差。我们还证明了两种类型的项之间的兼容性可以间接查询,并且这种查询策略可以产生改进。 |
| Content-aware Density Map for Crowd Counting and Density Estimation Authors Mahdi Maktabdar Oghaz, Anish R Khadka, Vasileios Argyriou, Paolo Remagnino 关于人群规模,密度和流量的精确知识可以为安全和安全应用,活动规划,建筑设计和分析消费者行为提供有价值的信息。创建一个功能强大的机器学习模型,用于此类应用程序需要一个大而高度准确和可靠的数据集。不幸的是,现有的人群计数和密度估计基准数据集不仅在其大小方面受到限制,而且缺乏注释,通常实施起来太耗时。本文试图通过内容感知技术解决这个问题,使用Chan Vese分割算法,二维高斯滤波器和强力最近邻搜索的组合。结果表明,通过简单地用所提出的方法替换常用的密度图生成器,使用现有技术模型可以实现更高的准确度。 |
| ***Pose Guided Fashion Image Synthesis Using Deep Generative Model Authors Wei Sun, Jawadul H. Bappy, Shanglin Yang, Yi Xu, Tianfu Wu, Hui Zhou 生成具有预期人体姿势的逼真图像是许多应用的有前途但具有挑战性的研究课题,例如智能照片编辑,电影制作,虚拟试穿和时尚显示。在本文中,我们提出了一种新的深度生成模型,用于将人的图像从给定姿势转移到新姿势,同时保持时尚项目的一致性。为了制定框架,我们使用一个发生器和两个鉴别器进行图像合成。该生成器包括图像编码器,姿势编码器和解码器。两个编码器提供视觉和几何上下文的良好表示,解码器将利用该上下文来生成照片级真实感图像。与现有的姿势引导图像生成模型不同,我们利用两个鉴别器来指导合成过程,其中一个鉴别器区分生成的图像和真实图像训练样本,另一个鉴别器验证目标姿势和生成的图像之间的外观一致性。我们进行网络的端到端训练,通过给定地面实况图像的反向传播来学习参数。所提出的生成模型能够合成给定目标姿势的人的照片级真实感图像。我们通过对两个数据集进行严格的实验来证明我们的结果,包括定量和定性。 |
| **Hardware Aware Neural Network Architectures using FbNet Authors Sai Vineeth Kalluru Srinivas, Harideep Nair, Vinay Vidyasagar 我们实施了一个受FBNet启发的可微分神经架构搜索NAS方法,用于发现针对特定目标设备进行了大量优化的神经网络。 FBNet NAS方法通过优化损失函数来发现来自给定搜索空间的神经网络,该函数考虑了准确性和目标设备延迟。我们通过添加能量项来扩展这种损失函数。这将有可能增强硬件意识,并帮助我们找到在准确性,延迟和能耗方面最佳的神经网络架构,在我们的案例中给定目标设备Raspberry Pi。我们将在搜索过程结束时获得的训练有素的儿童架构命名为硬件感知神经网络架构HANNA。我们通过将HANNA与针对移动嵌入式应用设计的另外两个最先进的神经网络(即MobileNetv2和用于CIFAR 10数据集的CondenseNet)进行基准测试来证明我们的方法的有效性。我们的研究结果表明,与MobileNetv2和CondenseNet相比,HANNA提供了大约2.5倍和1.7倍的加速,并且能耗降低了3.8倍和2倍。 HANNA能够在最先进的基线上提供如此显着的加速和能效优势,其成本是可承受的精度下降4 5。https://github.com/hpnair/18663_Project_FBNet |
| PolSAR Image Classification based on Polarimetric Scattering Coding and Sparse Support Matrix Machine Authors Xu Liu, Licheng Jiao, Dan Zhang, Fang Liu POLSAR图像优于光学图像,因为它可以独立于云层和太阳能照明而获得。 PolSAR图像分类是解释POLSAR图像的热门话题。本文提出了一种基于极化散射编码和稀疏支持矩阵机的POLSAR图像分类方法。首先,我们通过极化散射编码转换原始POLSAR数据以获得实数值矩阵,其被称为极化散射矩阵并且是稀疏矩阵。其次,稀疏支持矩阵机用于对稀疏极化散射矩阵进行分类,得到分类图。这两个步骤的结合充分考虑了POLSAR的特点。实验结果表明,该方法可以取得较好的效果,是一种有效的分类方法。 |
| High Speed and High Dynamic Range Video with an Event Camera Authors Henri Rebecq, Ren Ranftl, Vladlen Koltun, Davide Scaramuzza 事件相机是新颖的传感器,它以异步事件流的形式报告亮度变化而不是强度帧。相对于传统相机,它们具有显着优势,具有高时间分辨率,高动态范围和无运动模糊。虽然事件流原则上编码完整的视觉信号,但是从事件流中重建强度图像在实践中是一个不适当的问题。现有的重建方法基于手工制作的先验和关于成像过程的强烈假设以及自然图像的统计。在这项工作中,我们建议学习直接从数据重建事件流的强度图像,而不是依赖于任何手工制作的先验。我们提出了一种新颖的循环网络,用于从事件流中重建视频,并在大量模拟事件数据上进行训练。在训练期间,我们建议使用感知损失来鼓励重建遵循自然图像统计。我们进一步扩展了从颜色事件流合成彩色图像的方法。我们的网络在图像质量方面20大幅度超越了最先进的重建方法,同时实时舒适地运行。我们表明网络能够合成高速现象每秒5,000帧的高帧率视频,例如子弹击中物体并能够在具有挑战性的照明条件下提供高动态范围重建。我们还证明了我们的重建作为事件数据的中间表示的有效性。我们展示了现成的计算机视觉算法可以应用于我们的重建任务,如对象分类和视觉惯性测距,并且该策略始终优于专为事件数据设计的算法。 |
| Expressing Visual Relationships via Language Authors Hao Tan, Franck Dernoncourt, Zhe Lin, Trung Bui, Mohit Bansal 用文本描述图像是视觉语言研究中的基本问题。该领域目前的研究主要集中在单图像字幕上。然而,在各种实际应用中,例如,图像编辑,差异解释和检索,生成两个图像的关系字幕也是非常有用的。由于缺乏数据集和有效模型,这一重要问题尚未得到探索。为了推进这方面的研究,我们首先介绍一种新的语言引导图像编辑数据集,其中包含大量具有相应编辑指令的真实图像对。然后,我们提出了一种新的关系说话人模型,该模型基于编码器解码器架构,具有静态关系注意和顺序多头注意。我们还通过动态关系注意扩展模型,计算解码时的视觉对齐。我们的模型在我们新收集的和两个公共数据集上进行评估,这些数据集由用关系句注释的图像对组成。基于自动和人工评估的实验结果表明,我们的模型优于所有数据集的所有基线和现有方法。 |
| Multiclass segmentation as multitask learning for drusen segmentation in retinal optical coherence tomography Authors Rhona Asgari, Jos Ignacio Orlando, Sebastian Waldstein, Ferdinand Schlanitz, Magdalena Baratsits, Ursula Schmidt Erfurth, Hrvoje Bogunovi 视网膜光学相干断层扫描中的自动玻璃疣分割OCT扫描与了解年龄相关性黄斑变性AMD风险和进展相关。该任务通常通过分割定义玻璃疣的顶部底部解剖界面,视网膜色素上皮OBRPE的外边界和布鲁赫膜BM来进行。在本文中,我们提出了一种新的多解码器架构,它将玻璃疣分割作为一个多任务问题来解决。我们不是为OBRPE BM分段训练多类模型,而是针对每个目标类使用一个解码器,而针对层之间的区域使用额外的解码器。我们还引入了每个类特定分支和附加解码器之间的连接,以增加该代理任务的正则化效果。我们分别使用166个早期中间AMD Spectralis,200个AMD和控制Bioptigen OCT卷来验证我们对私有公共数据集的方法。我们的方法在层和玻璃疣分割评估中始终优于几个基线。 |
| Differentiable probabilistic models of scientific imaging with the Fourier slice theorem Authors Karen Ullrich, Rianne van den Berg, Marcus Brubaker, David Fleet, Max Welling 科学成像技术,如光学和电子显微镜和计算机断层扫描CT扫描,用于通过2D观察研究物体的三维结构。这些观察通过正交积分投影与原始3D对象相关。对于常见的3D重建算法,计算效率要求通过应用傅立叶切片定理对3D结构进行建模以在傅立叶空间中进行。目前,尚不清楚如何通过投影算子进行区分,因此当前的学习算法不能依赖基于梯度的方法来优化3D结构模型。在本文中,我们展示了如何通过傅立叶空间中的投影算子实现反向传播。我们通过蛋白质三维重建实验证明了该方法的有效性。我们进一步扩展了我们学习3D对象概率模型的方法。这使我们能够预测低采样率的区域或估计噪声。通过利用3D结构的学习不确定性作为模型拟合的无监督估计,可以获得更高的样本效率。最后,我们演示了如何使用对象姿态等未知属性的摊销推理方案来扩展重建算法。通过实证研究,我们表明,当地面实况对象包含更多对称性时,3D结构和对象姿势的联合推理变得更加困难。由于存在例如近似旋转对称性,姿势估计可能容易陷入局部最优,从而抑制3D结构的细粒度高质量估计。 |
| An Attention-Guided Deep Regression Model for Landmark Detection in Cephalograms Authors Zhusi Zhong, Jie Li, Zhenxi Zhang, Zhicheng Jiao, Xinbo Gao 头影测量追踪法通常用于正畸诊断和治疗计划。在本文中,我们提出了一个基于深度学习的框架,以自动检测头部测量X射线图像中的解剖标志。我们训练深度编码器解码器用于地标检测,并将全局地标配置与局部高分辨率特征响应相结合。所提出的框架工作基于2阶段网络,回归用于地标检测的多通道热图。在这个框架中,我们将注意机制与全局阶段热图嵌入,引导局部推断,以高分辨率回归局部热图贴片。此外,扩展探索策略在推断时证明了鲁棒性,在不增加模型复杂性的情况下扩展了搜索范围。我们已经在最广泛使用的头部测量X射线图像中的地标检测公共数据集中评估了我们的框架。通过较少的计算和手动调整,我们的框架实现了最先进的结果。 |
| Deep Learning Enhanced Extended Depth-of-Field for Thick Blood-Film Malaria High-Throughput Microscopy Authors Petru Manescu, Lydia Neary Zajiczek, Michael J. Shaw, Muna Elmi, Remy Claveau, Vijay Pawar, John Shawe Taylor, Iasonas Kokkinos, Mandayam A. Srinivasan, Ikeoluwa Lagunju, Olugbemiro Sodeinde, Biobele J. Brown, Delmiro Fernandez Reyes 快速准确的疟疾诊断仍然是全球性的健康挑战,自动化数字病理学方法可以提供适合在中低收入国家部署的可扩展解决方案。在这里,我们解决了厚血膜显微镜中扩展景深EDoF的问题,用于快速自动化疟疾诊断。通常优选具有大数值孔径的高放大率油物镜100x以解决有助于将真实寄生虫与干扰物分开的精细结构细节。然而,这样的物镜具有非常有限的景深,需要在每个视场FOV的不同焦平面处获取一系列图像。基于多尺度分解的当前EDoF技术是耗时的,因此不适合于样品的高通量分析。为了克服这一挑战,我们开发了一种基于卷积神经网络EDoF CNN的新型深度学习方法,该方法能够快速执行扩展景深,同时还增强了所得融合图像的空间分辨率。我们使用来自患有恶性疟原虫疟疾的患者的Giemsa染色的厚血涂片的模拟低分辨率z叠层来评估我们的方法。与传统的多尺度方法相比,EDoF CNN可以加速我们的数字病理采集平台并显着提高EDoF的质量,适用于较低分辨率的堆栈,对应于采用较少焦平面,大型相机像素分级或较低放大倍率物镜的采集FOV。我们使用EDoF上深度学习模型的寄生虫检测精度作为该方法性能的具体的,任务特定的度量。 |
| Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss Authors Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, Tengyu Ma 当训练数据集遭受严重的类不平衡时,深度学习算法可能会很差,但测试标准要求对频率较低的类进行良好的推广。我们设计了两种新方法来改善这种情况下的性能。首先,我们提出了一个理论上有原则的标签分布感知边际LDAM损失,其动机是通过最小化基于边缘的泛化界限。这种损失取代了训练期间的标准交叉熵目标,并且可以应用于先前的类别不平衡训练策略,例如重新加权或重新采样。其次,我们提出了一个简单但有效的培训计划,该计划将重新加权推迟到初始阶段之后,允许模型学习初始表示,同时避免与重新加权或重新采样相关的一些复杂性。我们在几个基准视觉任务上测试我们的方法,包括真实世界不平衡数据集iNaturalist 2018.我们的实验表明,这些方法中的任何一个都可以比现有技术有所改进,并且它们的组合可以实现更好的性能提升。 |
| Active Scene Understanding via Online Semantic Reconstruction Authors Lintao Zheng, Chenyang Zhu, Jiazhao Zhang, Hang Zhao, Hui Huang, Matthias Niessner, Kai Xu 我们提出了一种基于在线RGBD重建和语义分割的机器人操作主动理解未知室内场景的新方法。在我们的方法中,探索性机器人扫描由场景中的语义对象的识别和分割驱动并且以其为目标。我们的算法建立在体积深度融合框架之上,例如KinectFusion,并且在在线重建体积上执行基于实时体素的语义标记。机器人由在2D位置和方位角旋转的3D空间上参数化的在线估计离散观察得分场VSF引导。 VSF为每个网格存储相应视图的分数,其测量多少减少几何重建和语义标注的不确定性熵。基于VSF,我们选择下一个最佳视图NBV作为每个时间步的目标。然后,我们通过沿路径和轨迹最大化整体观察得分信息增益,共同优化两个相邻NBV之间的遍历路径和摄像机轨迹。通过广泛的评估,我们证明了我们的方法在探索性扫描过程中实现了高效准确的在线场景解析。 |
| *A Conditional Random Field Model for Context Aware Cloud Detection in Sky Images Authors Vijai T. Jayadevan, Jeffrey J. Rodriguez, Alexander D. Cronin 提出了一种基于地面天空图像云检测的条件随机场CRF模型。我们表明,通过在CRF框架中组合判别分类器和更高阶的集团潜力,可以实现非常高的云检测精度。首先使用均值偏移聚类算法将图像分成均匀区域,然后在这些区域上定义CRF模型。使用训练数据估计所涉及的各种参数,并且使用迭代条件模式ICM算法来执行推断。我们演示如何考虑空间背景可以提高准确性。我们提供定性和定量结果,以证明该框架的优越性能与其他应用于云检测的最先进方法相比较。 |
| Cardiac Segmentation from LGE MRI Using Deep Neural Network Incorporating Shape and Spatial Priors Authors Qian Yue, Xinzhe Luo, Qing Ye, Lingchao Xu, Xiahai Zhuang 晚期钆增强MRI的心脏分割是诊所中识别和评估心肌梗塞的重要任务。然而,由于图像中的异质强度分布和模糊边界,自动分割仍然具有挑战性。在本文中,我们提出了一种基于深度神经网络DNN的新方法,用于全自动分割。所提出的网络,称为SRSCN,包括形状重建神经网络SRNN和空间约束网络SCN。 SRNN旨在保持所得分割的逼真形状。它可以通过一组标签图像进行预训练,然后作为正则化术语嵌入到统一的损失函数中。因此,不需要手动设计的功能。此外,SCN结合了2D切片的空间信息。它通过多任务学习策略与分割网络一起制定和训练。我们使用45名患者评估了所提出的方法,并与两种现有技术的正则化方案(即解剖学约束神经网络和对抗性神经网络)进行了比较。结果表明,所提出的SRSCN优于传统方案,心肌分割的Dice评分为0.758 std 0.227,而观察者间变异的评分为0.757±0.083。 |
| Learning Personalized Attribute Preference via Multi-task AUC Optimization Authors Zhiyong Yang, Qianqian Xu, Xiaochun Cao, Qingming Huang 传统上,大多数现有属性学习方法是基于从有限数量的注释器聚合的注释的一致性来训练的。然而,共识可能在设置中失败,特别是当涉及具有不同兴趣和对属性词的理解的广泛的注释器时。在本文中,我们开发了一种新的多任务方法来理解和预测个性化属性注释。关于作为特定任务的每个注释器的属性偏好学习,我们首先提出多级任务参数分解以捕获从大众的高度流行的观点到对每个人特殊的高度个性化的选择的演变。同时,对于个性化学习方法,排名预测比准确分类更重要。这促使我们采用基于ROC曲线AUC的面积损失函数来改进我们的模型。除了基于AUC的损失之外,我们还提出了一种评估损耗和梯度的有效方法。从理论上讲,我们为一个非凸子问题提出了一种新的闭合形式解,这导致了可证明的收敛行为。此外,我们还提供了一个保证合理性能的概括。最后,实证分析一致地说明了我们提出的方法的有效性。 |
| 4D CNN for semantic segmentation of cardiac volumetric sequences Authors Andriy Myronenko, Dong Yang, Varun Buch, Daguang Xu, Alvin Ihsani, Sean Doyle, Mark Michalski, Neil Tenenholtz, Holger Roth 我们提出了一种4D卷积神经网络CNN,用于分析回顾性心电门控心脏CT,随时间推移的一系列单通道体积数据。虽然时间序列中只有一小部分卷被注释,但我们在可用标签上定义了稀疏损失函数,以允许网络在训练期间利用未标记的图像并生成完全分段的序列。我们研究了所提出的4D网络的准确性,以预测时间上一致的分割,并与传统的3D分割方法进行比较。我们证明了4D CNN的可行性,并确定了其在心脏4D CCTA上的表现。 |
| *The Cells Out of Sample (COOS) dataset and benchmarks for measuring out-of-sample generalization of image classifiers Authors Alex X. Lu, Amy X. Lu, Wiebke Schormann, David W. Andrews, Alan M. Moses 了解分类器是否概括为样本数据集之外是机器学习中的核心问题。显微镜图像提供了一种标准化的方法来测量图像分类器的泛化能力,因为我们可以在越来越不同但受控制的变化因素下对相同类别的对象进行成像。我们创建了132,209个小鼠细胞图像的公共数据集,COOS 7 Cells Out Of Sample 7 Class。 COOS 7提供了一种分类设置,其中四个测试数据集具有增加的协变量偏移程度,一些图像是训练数据的随机子集,而另一些是来自几个月后再现的实验并且由不同仪器成像。我们使用不同的表示来对一系列分类模型进行基准测试,包括转移的神经网络特征,具有监督的深度CNN的端到端分类,以及来自自监督的CNN的特征。虽然大多数分类器在类似于训练数据集的测试数据集上表现良好,但所有分类器都无法将其性能推广到具有更大协变量偏移的数据集。这些基线强调了图像数据中协变量变化的挑战,并建立了用于改善图像分类器的泛化能力的度量。 |
| An IoT Based Framework For Activity Recognition Using Deep Learning Technique Authors Ashwin Geet D Sa, B. G. Prasad 活动识别是识别和识别代理的行为或目标的能力。代理可以是执行具有最终目标的操作的任何对象或实体。代理可以是执行动作的一个代理或执行动作或具有一些交互的代理组。人类活动识别因其在娱乐,医疗保健,模拟和监视系统等许多实际应用中的需求而受到欢迎。基于视觉的活动识别正在获得优势,因为它不需要任何人为干预或与人类进行身体接触。此外,还有一组联网,其目的是跟踪和识别代理的活动。跟踪或识别人类活动所需的传统应用程序使用了可穿戴设备。但是,这种应用需要人的身体接触。为了克服这些挑战,可以使用基于视觉的活动识别系统,其使用相机来记录视频和执行识别任务的处理器。这项工作分两个阶段实施。在第一阶段,提出了一种实现活动识别的方法,使用背景减法图像,然后是3D卷积神经网络。已经报道了在3D卷积神经网络之前使用背景减法的影响。在第二阶段,工作进一步扩展并在Raspberry Pi上实施,可用于记录视频流,然后识别视频中涉及的活动。因此,提供了使用基于物联网的小型设备进行活动识别的概念证明,其可以增强系统并以各种形式扩展其应用,例如,增加便携性,网络和设备的其他能力。 |
| Visual Navigation by Generating Next Expected Observations Authors Qiaoyun Wu, Dinesh Manocha, Jun Wang, Kai Xu 我们提出了一种在未知环境中进行视觉导航的新方法,其中通过构思下一次最佳动作后期望观察到的下一个观察来指导代理。这是通过学习变分贝叶斯模型来实现的,该模型以代理和目标视图的当前观察为条件生成下一个预期观测NEO。我们的方法根据当前观察和NEO预测下一个最佳行动。我们的生成模型是通过优化包含两个关键设计的变分目标来学习的。首先,潜在分布以当前观察和目标视图为条件,支持基于模型的目标驱动导航。其次,潜在空间用高斯混合物建模,以当前观察和下一个最佳动作为条件。我们对后验混合的使用有效地缓解了过度正规化潜在空间的问题,从而促进了新颖场景中的模型推广。此外,NEO生成模拟了代理环境交互的前向动态,提高了近似推理的质量,从而有利于数据效率。我们对现实世界和综合基准进行了广泛的评估,并表明我们的模型在成功率,数据效率和交叉场景概括方面明显优于基于RL的现有技术。 |
| Equivariant neural networks and equivarification Authors Erkao Bao, Linqi Song 我们提供了一个将神经网络修改为等效神经网络的过程,我们将其称为em等效。作为一个例子,我们通过对卷积神经网络进行等效来构建用于图像分类的等变神经网络。 |
| Enforcing temporal consistency in Deep Learning segmentation of brain MR images Authors Malav Bateriwala, Pierrick Bourgeat 纵向分析具有显示发育轨迹和监测医学成像中疾病进展的巨大潜力。该过程依赖于一致且稳健的联合4D分割。传统技术取决于图像随时间的相似性以及使用受试者特定先验以减少随机变化并改善整体纵向分析的稳健性和灵敏度。然而,这是缓慢且计算密集的,因为每次都需要重建特定于主题的模板。这项工作的重点是利用深度学习加速这种分析。所提出的方法基于深度CNN并且包含语义分割并且为同一主题提供纵向关系。所提出的方法基于深度CNN并且包含语义分割并且为同一主题提供纵向关系。使用3D补丁作为修改的Unet的输入的现有技术提供大约0.91 pm 0.5 Dice的结果并且在CNN中使用多视图图谱提供大致相同的结果。在这项工作中,探索了不同的模型,每个模型提供更好的准确性和快速的结果,同时提高分割质量。这些方法在来自EADC ADNI Harmonized Hippocampus Protocol的135次扫描中进行评估。提出的基于CNN的分割方法演示了如何使用先前切片的2D分割可以提供与3D分割类似的结果,同时保持3D维度的良好连续性和提高的速度。仅使用2D修改的矢状切片为我们提供了针对特定主题的更好的骰子和纵向分析。对于ADNI数据集,使用简单的UNet CNN技术得到0.84 pm 0.5,同时在相同输入上使用修改的CNN技术产生0.89 pm 0.5。使用各种方法计算并分析几种测试案例的萎缩率和RMS误差。 |
| Signatures in Shape Analysis: an Efficient Approach to Motion Identification Authors Elena Celledoni, P l Erik Lystad, Nikolas Tapia 签名以重新参数化不变的方式提供路径的某些特征的简洁描述。我们提出了一种基于签名对形状进行分类的方法,并将其与基于SRV变换和动态规划的当前方法进行比较。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com