python数据分析-波士顿房价预测
MOOC”用python玩转数据“里面的一个课程实例,我对代码做了一些修改。
源码:
import matplotlib.pyplot as plt
import pandas as pd
import statsmodels.api as sm
from sklearn import datasets
#导入数据源 sklearn
boston = datasets.load_boston()
X = boston.data
y = boston.target
print(X.shape)
# print(boston.DESCR)
#输出所有属性
i = 0
while i<=12:
fig,ax = plt.subplots(figsize=(3,3))
ax.scatter(X[:,i], y, color='blue')
i = i+1
# 将每列数据与价格之间的关系用散点图输出
# plt.subplot(13,1,i+1) 子图实现方式
Z = pd.DataFrame(X, columns = boston.feature_names)
w = pd.DataFrame(y, columns = ['MEDV'])
Z.drop('AGE', axis = 1, inplace = True)
Z.drop('INDUS', axis = 1, inplace = True)
#drop删除列需要手动添加axis=1
#如果手动设定为True(默认为False),那么原数组直接就被替换。
Z_add1 = sm.add_constant(Z)
model = sm.OLS(w, Z_add1).fit()
# sm.OLS()为普通最小二乘回归模型, fit()用于拟合
print(model.summary())
print(model.params)结果中主要的指标是修正后的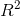 ,表示模型对现实数据拟合的程度, 它是皮尔逊相关系数的平方, 从数值上说, R²介于 0~1 之间,越接近 1 表示拟合效果越好。本文的模拟结果是0.74左右。
,表示模型对现实数据拟合的程度, 它是皮尔逊相关系数的平方, 从数值上说, R²介于 0~1 之间,越接近 1 表示拟合效果越好。本文的模拟结果是0.74左右。