pytorch学习笔记——紧凑型神经网络设计(13)
光有精确度是不够的,部分神经网络有部署到嵌入式和移动设备上的需求,因而具有设计紧凑型神经网络的现实需要。我们在原先网络的基础上采用卷积核拆分、多通道融合等策略减小参数数量,同时增加网络的深度,使得新的网络架构在与原先网络容量相当的前提下参数数量减小到原先的不到1/3。我们的新架构如下:
SimpleNet(
(conv1): Sequential(
(0): Conv2d(1, 4, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(1): Conv2d(4, 6, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(2): BatchNorm2d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU()
(4): Conv2d(6, 8, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(5): Conv2d(8, 12, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(6): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU()
(8): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): Conv2d(12, 16, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0))
(1): Conv2d(16, 24, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1))
(2): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU()
(4): Conv2d(24, 16, kernel_size=(1, 1), stride=(1, 1))
(5): Conv2d(16, 8, kernel_size=(1, 1), stride=(1, 1))
(6): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU()
(8): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=32, out_features=32, bias=True)
(1): Dropout(p=0.5, inplace=False)
(2): Linear(in_features=32, out_features=10, bias=True)
)
)>
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 4, 8, 8] 16
Conv2d-2 [-1, 6, 8, 8] 78
BatchNorm2d-3 [-1, 6, 8, 8] 12
ReLU-4 [-1, 6, 8, 8] 0
Conv2d-5 [-1, 8, 8, 8] 152
Conv2d-6 [-1, 12, 8, 8] 300
BatchNorm2d-7 [-1, 12, 8, 8] 24
ReLU-8 [-1, 12, 8, 8] 0
MaxPool2d-9 [-1, 12, 4, 4] 0
Conv2d-10 [-1, 16, 4, 4] 592
Conv2d-11 [-1, 24, 4, 4] 1,176
BatchNorm2d-12 [-1, 24, 4, 4] 48
ReLU-13 [-1, 24, 4, 4] 0
Conv2d-14 [-1, 16, 4, 4] 400
Conv2d-15 [-1, 8, 4, 4] 136
BatchNorm2d-16 [-1, 8, 4, 4] 16
ReLU-17 [-1, 8, 4, 4] 0
MaxPool2d-18 [-1, 8, 2, 2] 0
Linear-19 [-1, 32] 1,056
Dropout-20 [-1, 32] 0
Linear-21 [-1, 10] 330
================================================================
Total params: 4,336
Trainable params: 4,336
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.05
Params size (MB): 0.02
Estimated Total Size (MB): 0.07
----------------------------------------------------------------
经过训练之后,网络的最高精确度才达到了98%以上,勉强超过了机器学习随机森林算法。训练结果:(注:由于训练数据使用了数据增强,训练难度比测试难度略大,故测试集精确度略大于训练集精度属于可解释现象)
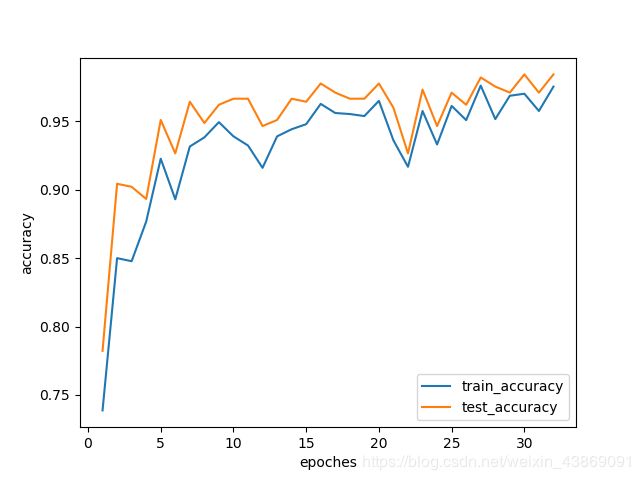
下一次我们将采取知识蒸馏等技巧来提升紧凑型神经网络的精确度。
附代码:
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
from sklearn.datasets import load_digits
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
import torch as t
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
from graphviz import Digraph
import torch
from torch.autograd import Variable
from torchsummary import summary
from PIL import Image
from torchvision.transforms import transforms
import random
class train_mini_mnist(t.utils.data.Dataset):
def __init__(self):
self.X,self.y=load_digits(return_X_y=True)
self.X=self.X
self.X_train,self.X_test,self.y_train,self.y_test=train_test_split(self.X,self.y,random_state=0)
def __getitem__(self, index):
img, target = np.array(self.X_train[index].reshape(8,8),dtype=int), int(self.y_train[index])
plt.imshow(img)
img=transforms.ToPILImage()(img)
img=img.rotate(random.randint(-20,20))#填充白色
img=transforms.ToTensor()(img)
return img/15.,target
def __len__(self):
return len(self.y_train)
class test_mini_mnist(t.utils.data.Dataset):
def __init__(self):
self.X,self.y=load_digits(return_X_y=True)
self.X=self.X/15.
self.X_train,self.X_test,self.y_train,self.y_test=train_test_split(self.X,self.y,random_state=0)
def __getitem__(self, index):
return t.tensor(self.X_test[index].reshape(1,8,8),dtype=torch.float32),self.y_test[index]
def __len__(self):
return len(self.y_test)
BATCH_SIZE=8
LEARNING_RATE=3e-3
EPOCHES=100
train_data=train_mini_mnist()
test_data=test_mini_mnist()
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
test_loader = Data.DataLoader(dataset=test_data, batch_size=BATCH_SIZE, shuffle=True)
class Compact_Net(nn.Module):
def __init__(self):
super(Compact_Net, self).__init__()
self.conv1 = nn.Sequential(#(1, 8, 8)
nn.Conv2d(in_channels=1, out_channels=4, kernel_size=(3,1), stride=1, padding=(1,0)),
nn.Conv2d(in_channels=4, out_channels=6, kernel_size=(1,3), stride=1, padding=(0,1)),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.Conv2d(in_channels=6, out_channels=8, kernel_size=(3,1), stride=1, padding=(1,0)),
nn.Conv2d(in_channels=8, out_channels=12, kernel_size=(1,3), stride=1, padding=(0,1)),
nn.BatchNorm2d(12),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=12, out_channels=16, kernel_size=(3,1), stride=1, padding=(1,0)),
nn.Conv2d(in_channels=16, out_channels=24, kernel_size=(1,3), stride=1, padding=(0,1)),
nn.BatchNorm2d(24),
nn.ReLU(),
nn.Conv2d(in_channels=24, out_channels=16, kernel_size=(1,1), stride=1, padding=0),
nn.Conv2d(in_channels=16, out_channels=8, kernel_size=(1,1), stride=1, padding=0),
nn.BatchNorm2d(8),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)#(8,2,2)
)
self.fc = nn.Sequential(
nn.Linear(8*2*2, 32),
nn.Dropout(0.5),
nn.Linear(32, 10)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)#相当于Flatten
x = self.fc(x)
return x
def eval_on_dataloader(name,loader,len):
acc = 0.0
with torch.no_grad():
for data in loader:
images, labels = data
outputs = net(images)
predict_y = torch.max(outputs, dim=1)[1]#torch.max返回两个数值,一个是最大值,一个是最大值的下标
acc += (predict_y == labels).sum().item()
accurate = acc / len
return accurate
def plot_train_and_test_result(train_accs,test_accs):
epoches=np.arange(1,len(train_accs)+1,dtype=np.int32)
plt.plot(epoches,train_accs,label="train_accuracy")
plt.plot(epoches,test_accs,label="test_accuracy")
plt.xlabel('epoches')
plt.ylabel('accuracy')
plt.legend()
net=Compact_Net()
print(net.parameters)
summary(net, (1, 8, 8))
loss_fn = nn.CrossEntropyLoss()
optim = torch.optim.Adam(net.parameters(), lr = LEARNING_RATE,weight_decay=3e-4)
for name,parameters in net.named_parameters():
print(name,":",parameters.size())
best_acc = 0.0
train_accs,test_accs=[],[]
for epoch in range(EPOCHES):
net.train()#切换到训练模式
for step, data in enumerate(train_loader, start=0):
images, labels = data
optim.zero_grad()#将优化器的梯度清零
logits = net(images)#网络推断的输出
loss = loss_fn(logits, labels.long())#计算损失函数
loss.backward()#反向传播求梯度
optim.step()#优化器进一步优化
rate = (step+1)/len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100), a, b, loss), end="")
print()
net.eval()#切换到测试模式
train_acc=eval_on_dataloader("train",train_loader,train_data.__len__())
test_acc=eval_on_dataloader("test",test_loader,test_data.__len__())
train_accs.append(train_acc)
test_accs.append(test_acc)
print("epoch:",epoch,"train_acc:",train_acc," test_acc:",test_acc)
if test_acc>=best_acc:
best_acc=test_acc
torch.save(net, 'net'+str(best_acc)+'.pkl')
print('Finished Training')
plot_train_and_test_result(train_accs,test_accs)
torch.save(net, 'net_final.pkl')
plt.show()