自动爬取每日天气、每日微博热搜、每日外文网数据(附带自动翻译)数据,并以文本形式邮件发送
自动爬取每日天气、每日微博热搜、每日外文网数据(附带自动翻译)数据,并以文本形式邮件发送
项目特点:
- 自动爬取中国天气网指定城市的一周天气;
- 自动爬取每日微博热搜的热搜标题以及链接;
- 自动爬取外文网http://conflictoflaws.net/的每日推荐标题及链接,并同时将标题处理为中英对照,翻译引擎为有道在线翻译;
- 将所爬取的所有数据整合为文本形式分别保存到本地并以邮件发送到目标邮箱。
具体实现代码如下:
1. 主体逻辑代码如下:
def get_text():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3722.400 QQBrowser/10.5.3738.400'
}
url = {
'weibo': 'https://s.weibo.com/top/summary?cate=realtimehot',
'tianqi': 'http://www.weather.com.cn',
'law': 'http://conflictoflaws.net',
}
weibo = get_weibo(url, headers)
tianqi = get_tianqi(url, headers)
laws = get_law(url, headers)
for item in laws:
law = item
text = oprate(weibo, tianqi, law)
return text
def main():
print('|============正在搜集数据===========|')
text = get_text()
print('|======搜索完成,正在更新旧数据=====|')
os.remove('text.txt')
time.sleep(3)
for each in text:
with open('text.txt', 'a+', encoding= 'utf-8') as f:
f.write(each + '\n')
print('|==============准备发送=============|')
with open('text.txt', 'r', encoding='utf-8') as f:
string = f.read()
time.sleep(5)
try_max = 1
while try_max < 6:
try:
from_addr = '[email protected]'
password = 'xxxx'
to_addr = ['[email protected]', '[email protected]', '[email protected]']
smtp_server = 'smtp.126.com'
message = MIMEText(string, 'plain', 'utf-8')
message['From'] = 'xxxx '
message['To'] = 'Little Pig '
message['Subject'] = Header(u'阿光每日小报', 'utf-8').encode()
server = smtplib.SMTP(smtp_server, 25)
server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, to_addr, message.as_string())
server.quit()
except SMTPDataError:
print('|====发送失败,正在尝试重发第%d次====|' % try_max)
try_max += 1
time.sleep(3)
else:
print('|===========邮件发送完成============|')
time.sleep(5)
break
if __name__ == '__main__':
main()
2. 自动爬取中国天气网指定城市(兰州,长沙,南京,海南)的一周天气
def get_tianqi(url, headers):
lanzhou_url = url.get('tianqi') + '/weather/101160101.shtml'
changsha_url = url.get('tianqi') + '/weather/101250101.shtml'
nanjing_url = url.get('tianqi') + '/weather/101190101.shtml'
hainan_url = url.get('tianqi') + '/weather/101310101.shtml'
url_pool = [lanzhou_url, changsha_url, nanjing_url, hainan_url]
weathers = []
for item in url_pool:
weather = []
html = requests.get(item, headers).content.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
day_list = soup.find('ul', 't clearfix').find_all('li')
for day in day_list:
date = day.find('h1').get_text()
wea = day.find('p', 'wea').get_text()
if day.find('p', 'tem').find('span'):
hightem = day.find('p', 'tem').find('span').get_text()
else:
hightem = ''
lowtem = day.find('p', 'tem').find('i').get_text()
weather.append([date, wea, hightem, lowtem])
weathers.append(weather)
return weathers
3. 自动爬取每日微博热搜的热搜标题以及链接
def get_weibo(url, headers):
weibo_text = []
weibo_url = url.get('weibo')
html = requests.get(weibo_url, headers = headers).content.decode('utf-8')
titles_links = re.findall(r'.*?(.*?).*? ', html, re.S)
for title_link in titles_links:
weibo_text.append({
'title': title_link[1],
'link' : 'https://s.weibo.com' + title_link[0]
})
return weibo_text
4. 自动爬取外文网http://conflictoflaws.net/的每日推荐标题及链接
def get_law(url, headers):
html = requests.get(url.get('law'), headers = headers).content.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
views = []
view_list = soup.find_all('h2', 'headline')
for view in view_list:
view_title = view.find('a').get_text()
view_a = view.find('a')
view_link = view_a['href']
views.append([view_title, view_link])
news = []
new_list = soup.find_all('p', 'pis-title')
for new in new_list:
new_title = new.find('a').get_text()
new_a = new.find('a')
new_link = new_a['href']
news.append([new_title, new_link])
yield{
'view': views,
'new': news
}
5. 衔接上一步,将标题处理为中英对照,翻译引擎为有道在线翻译
def law_translate(law):
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3722.400 QQBrowser/10.5.3738.400'
view_str = []
view_content = law.get('view')
for v_content in view_content:
view_str.append(v_content[0])
new_str = []
new_content = law.get('new')
for n_content in new_content:
new_str.append(n_content[0])
translation = []
for each in view_str:
data = {}
data['i'] = each
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = '15658686268937'
data['sign'] = 'ee53369f775bc53f8be7328d3afb3631'
data['ts'] = '1565868626893'
data['bv'] = 'b9bd10e2943f377d66e859990bbee707'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_REALTlME'
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data, head)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
result = target['translateResult'][0][0]['tgt']
translation.append(result)
for each in new_str:
data = {}
data['i'] = each
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = '15658686268937'
data['sign'] = 'ee53369f775bc53f8be7328d3afb3631'
data['ts'] = '1565868626893'
data['bv'] = 'b9bd10e2943f377d66e859990bbee707'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_REALTlME'
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data, head)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
result = target['translateResult'][0][0]['tgt']
translation.append(result)
law_translate = []
i = 0
for l in law.get('view'):
law_translate.append(l[0])
law_translate.append(translation[i])
law_translate.append(l[1])
i += 1
for l in law.get('new'):
law_translate.append(l[0])
law_translate.append(translation[i])
law_translate.append(l[1])
i += 1
return law_translate
6. 将所爬取的所有数据整合
def oprate(weibo, tianqi, law):
def law_translate(law):
(code...)
law_translate = law_translate(law)
weibo_text = []
for w in weibo:
w_text = '%s>>>%s' % (w.get('title'), w.get('link'))
weibo_text.append(w_text)
tianqi_city = []
for t in tianqi[0]:
t_lanzhou = '兰州%s天气为%s,最高气温%s,最低气温%s' % (t[0], t[1], t[2], t[3])
tianqi_city.append(t_lanzhou)
for t in tianqi[1]:
t_changsha = '长沙%s天气为%s,最高气温%s,最低气温%s' % (t[0], t[1], t[2], t[3])
tianqi_city.append(t_changsha)
for t in tianqi[2]:
t_nanjing = '南京%s天气为%s,最高气温%s,最低气温%s' % (t[0], t[1], t[2], t[3])
tianqi_city.append(t_nanjing)
for t in tianqi[3]:
t_hainan = '海南%s天气为%s,最高气温%s,最低气温%s' % (t[0], t[1], t[2], t[3])
tianqi_city.append(t_hainan)
text = ['【天气】\n']
for each in tianqi_city:
text.append(each)
text.append('\n【微博热搜】\n')
for each in weibo_text:
text.append(each)
text.append('\n【Conflict of Laws】\n')
for each in law_translate:
text.append(each)
return text
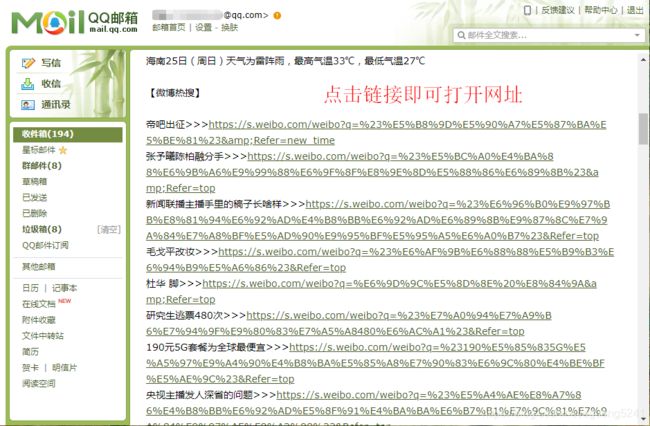
综合上述代码即可实现该项目,效果如下图:
启动程序即可自动搜集数据并发送邮件

本地文档如下:
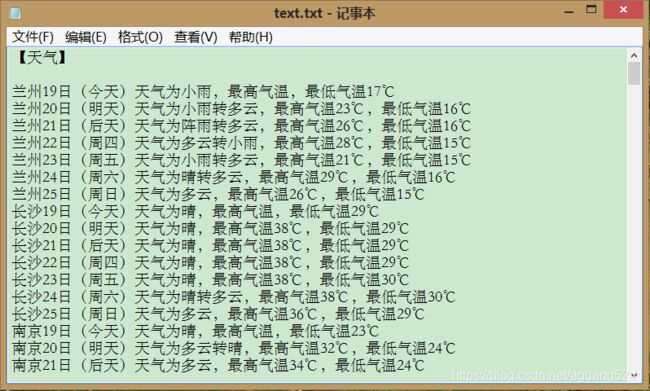

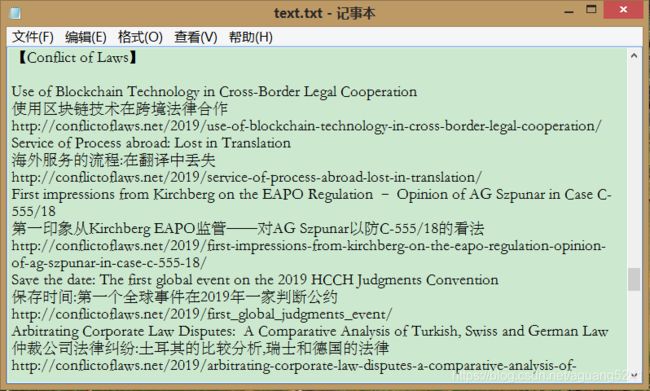
目标邮箱邮件如下:


完整代码如下:
from email.header import Header
from email.mime.text import MIMEText
import smtplib
from smtplib import SMTPDataError
import requests
import re
from bs4 import BeautifulSoup
import urllib.request
import urllib.parse
import json
import time
import os
def get_weibo(url, headers):
weibo_text = []
weibo_url = url.get('weibo')
html = requests.get(weibo_url, headers = headers).content.decode('utf-8')
titles_links = re.findall(r'.*?(.*?).*? ', html, re.S)
for title_link in titles_links:
weibo_text.append({
'title': title_link[1],
'link' : 'https://s.weibo.com' + title_link[0]
})
return weibo_text
# [{title,link}{title,link}...{title,link}]
def get_tianqi(url, headers):
lanzhou_url = url.get('tianqi') + '/weather/101160101.shtml'
changsha_url = url.get('tianqi') + '/weather/101250101.shtml'
nanjing_url = url.get('tianqi') + '/weather/101190101.shtml'
hainan_url = url.get('tianqi') + '/weather/101310101.shtml'
url_pool = [lanzhou_url, changsha_url, nanjing_url, hainan_url]
weathers = []
for item in url_pool:
weather = []
html = requests.get(item, headers).content.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
day_list = soup.find('ul', 't clearfix').find_all('li')
for day in day_list:
date = day.find('h1').get_text()
wea = day.find('p', 'wea').get_text()
if day.find('p', 'tem').find('span'):
hightem = day.find('p', 'tem').find('span').get_text()
else:
hightem = ''
lowtem = day.find('p', 'tem').find('i').get_text()
weather.append([date, wea, hightem, lowtem])
weathers.append(weather)
return weathers
#[[[]*7]*4] item[0]表示各地一周天气 item[0][0]表示该地当日天气
def get_law(url, headers):
html = requests.get(url.get('law'), headers = headers).content.decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
views = []
view_list = soup.find_all('h2', 'headline')
for view in view_list:
view_title = view.find('a').get_text()
view_a = view.find('a')
view_link = view_a['href']
views.append([view_title, view_link])
news = []
new_list = soup.find_all('p', 'pis-title')
for new in new_list:
new_title = new.find('a').get_text()
new_a = new.find('a')
new_link = new_a['href']
news.append([new_title, new_link])
yield{
'view': views,
'new': news
}
# {'view':[[], [], ...[]],'new':[[], [], ...[]]}
def oprate(weibo, tianqi, law):
def law_translate(law):
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3722.400 QQBrowser/10.5.3738.400'
view_str = []
view_content = law.get('view')
for v_content in view_content:
view_str.append(v_content[0])
new_str = []
new_content = law.get('new')
for n_content in new_content:
new_str.append(n_content[0])
translation = []
for each in view_str:
data = {}
data['i'] = each
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = '15658686268937'
data['sign'] = 'ee53369f775bc53f8be7328d3afb3631'
data['ts'] = '1565868626893'
data['bv'] = 'b9bd10e2943f377d66e859990bbee707'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_REALTlME'
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data, head)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
result = target['translateResult'][0][0]['tgt']
translation.append(result)
for each in new_str:
data = {}
data['i'] = each
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = '15658686268937'
data['sign'] = 'ee53369f775bc53f8be7328d3afb3631'
data['ts'] = '1565868626893'
data['bv'] = 'b9bd10e2943f377d66e859990bbee707'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_REALTlME'
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data, head)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
target = json.loads(html)
result = target['translateResult'][0][0]['tgt']
translation.append(result)
law_translate = []
i = 0
for l in law.get('view'):
law_translate.append(l[0])
law_translate.append(translation[i])
law_translate.append(l[1])
i += 1
for l in law.get('new'):
law_translate.append(l[0])
law_translate.append(translation[i])
law_translate.append(l[1])
i += 1
return law_translate
law_translate = law_translate(law)
weibo_text = []
for w in weibo:
w_text = '%s>>>%s' % (w.get('title'), w.get('link'))
weibo_text.append(w_text)
tianqi_city = []
for t in tianqi[0]:
t_lanzhou = '兰州%s天气为%s,最高气温%s,最低气温%s' % (t[0], t[1], t[2], t[3])
tianqi_city.append(t_lanzhou)
for t in tianqi[1]:
t_changsha = '长沙%s天气为%s,最高气温%s,最低气温%s' % (t[0], t[1], t[2], t[3])
tianqi_city.append(t_changsha)
for t in tianqi[2]:
t_nanjing = '南京%s天气为%s,最高气温%s,最低气温%s' % (t[0], t[1], t[2], t[3])
tianqi_city.append(t_nanjing)
for t in tianqi[3]:
t_hainan = '海南%s天气为%s,最高气温%s,最低气温%s' % (t[0], t[1], t[2], t[3])
tianqi_city.append(t_hainan)
text = ['【天气】\n']
for each in tianqi_city:
text.append(each)
text.append('\n【微博热搜】\n')
for each in weibo_text:
text.append(each)
text.append('\n【Conflict of Laws】\n')
for each in law_translate:
text.append(each)
return text
def get_text():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3722.400 QQBrowser/10.5.3738.400'
}
url = {
'weibo': 'https://s.weibo.com/top/summary?cate=realtimehot',
'tianqi': 'http://www.weather.com.cn',
'law': 'http://conflictoflaws.net',
}
weibo = get_weibo(url, headers)
tianqi = get_tianqi(url, headers)
laws = get_law(url, headers)
for item in laws:
law = item
text = oprate(weibo, tianqi, law)
return text
def main():
print('|============正在搜集数据===========|')
text = get_text()
print('|======搜索完成,正在更新旧数据=====|')
os.remove('text.txt')
time.sleep(3)
for each in text:
with open('text.txt', 'a+', encoding= 'utf-8') as f:
f.write(each + '\n')
print('|==============准备发送=============|')
with open('text.txt', 'r', encoding='utf-8') as f:
string = f.read()
time.sleep(5)
try_max = 1
while try_max < 6:
try:
from_addr = '[email protected]'
password = 'xxxx'
to_addr = ['[email protected]', '[email protected]', '[email protected]']
smtp_server = 'smtp.126.com'
message = MIMEText(string, 'plain', 'utf-8')
message['From'] = 'xxxx '
message['To'] = 'Little Pig '
message['Subject'] = Header(u'阿光每日小报', 'utf-8').encode()
server = smtplib.SMTP(smtp_server, 25)
server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, to_addr, message.as_string())
server.quit()
except SMTPDataError:
print('|====发送失败,正在尝试重发第%d次====|' % try_max)
try_max += 1
time.sleep(3)
else:
print('|===========邮件发送完成============|')
time.sleep(5)
break
if __name__ == '__main__':
main()
谢谢支持,希望与大家共同进步!!!