Hadoop HDFS高可用性(HA) 部署篇
配置概述
与联邦配置类似,HA配置向后兼容,并允许现有的单一NameNode配置无需更改即可工作。新的配置被设计成使得集群中的所有节点可以具有相同的配置,而不需要基于节点的类型将不同的配置文件部署到不同的机器。
与HDFS联合身份相似,HA群集重用名称服务标识来标识实际上可能由多个HA NameNode组成的单个HDFS实例。另外,一个名为NameNode ID的新抽象被添加到HA中。群集中每个不同的NameNode都有一个不同的NameNode ID来区分它。要支持所有NameNode的单个配置文件,相关的配置参数后缀名称服务ID以及NameNode ID。
配置细节
要配置HA NameNode,您必须将多个配置选项添加到您的hdfs-site.xml配置文件。
设置这些配置的顺序并不重要,但是您为dfs.nameservices和dfs.ha.namenodes。[nameservice ID]选择的值将决定后面的那些键。因此,在设置其余的配置选项之前,您应该确定这些值。
- dfs.nameservices - 这个新名称服务的逻辑名称
为此名称服务选择一个逻辑名称,例如“mycluster”,并使用此逻辑名称作为此配置选项的值。你选择的名字是任意的。它将用于配置,也可以用作群集中绝对HDFS路径的权威组件。
注意:如果您还在使用HDFS联合身份验证,则此配置设置还应该将其他名称服务(HA或其他)的列表作为逗号分隔的列表。
<property>
<name>dfs.nameservicesname>
<value>myclustervalue>
property>- dfs.ha.namenodes.[nameservice ID] - 名称服务中每个NameNode的唯一标识符
使用逗号分隔的NameNode ID进行配置。这将由DataNodes用来确定集群中的所有NameNode。例如,如果以前使用“mycluster”作为名称服务标识,并且想要使用“nn1”和“nn2”作为NameNode的单个标识,则可以这样配置:
<property>
<name>dfs.ha.namenodes.myclustername>
<value>nn1,nn2value>
property>注意:目前,每个名称服务最多只能配置两个NameNode。
- dfs.namenode.rpc-address.[nameservice ID].[name node ID] - 每个NameNode监听的完全限定的RPC地址
对于之前配置的NameNode ID,请设置NameNode进程的完整地址和IPC端口。请注意,这会导致两个单独的配置选项。例如:
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1name>
<value>machine1.example.com:8020value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2name>
<value>machine2.example.com:8020value>
property>注意:如果您愿意,您可以类似地配置“ servicerpc-address ”设置。
- dfs.namenode.http-address.[nameservice ID].[name node ID] - 每个NameNode监听的完全限定的HTTP地址
与上面的rpc-address类似,为两个NameNode的HTTP服务器设置侦听地址。例如:
<property>
<name>dfs.namenode.http-address.mycluster.nn1name>
<value>machine1.example.com:50070value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2name>
<value>machine2.example.com:50070value>
property>注意:如果您启用了Hadoop的安全功能,则还应该为每个NameNode 设置类似的https地址。
- dfs.namenode.shared.edits.dir - 标识NameNode将写入/读取编辑的JN组的URI
这是一个配置,其提供的共享编辑存储JournalNodes,通过活动的NameNode写入和备用的NameNode读取这个存储区,使两个NameNode节点的数据尽可能是一致的。尽管您必须指定多个JournalNode地址,但您应该只配置其中一个URI。URI的形式应该是:qjournal:// * host1:port1 ; host2:port2 ; host3:port3 * / * journalId *。日志ID是此名称服务的唯一标识符,它允许一组JournalNodes为多个联邦名称系统提供存储。虽然不是要求,但重用日志标识符的名称服务ID是一个好主意。
例如,如果此群集的JournalNodes在机器“node1.example.com”,“node2.example.com”和“node3.example.com”上运行,并且名称服务ID是“mycluster”,则可以使用以下作为此设置的值(JournalNode的默认端口是8485):
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/myclustervalue>
property>- dfs.client.failover.proxy.provider.[nameservice ID] - HDFS客户端用于联系Active NameNode的Java类
配置将由DFS客户端使用的Java类的名称来确定哪个NameNode是当前的Active,以及哪个NameNode当前正在服务于客户端请求。目前Hadoop附带的唯一的实现是ConfiguredFailoverProxyProvider,所以使用这个,除非你使用的是自定义的。例如:
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
- dfs.ha.fencing.methods - 在故障转移期间将用于划分活动NameNode的脚本或Java类的列表
对于系统的正确性来说,在任何给定的时间只有一个NameNode处于活动状态是理想的。重要的是,在使用仲裁日志管理器时,只有一个NameNode将被允许写入JournalNodes,因此不会破坏来自裂脑场景的文件系统元数据。但是,当发生故障转移时,以前的活动NameNode仍可能向客户端提供读取请求,这些读取请求可能会过时,直到NameNode在尝试写入JournalNodes时关闭。因此,即使在使用仲裁日志管理器时,仍然需要配置一些防护方法。但是,如果在防护机制失败的情况下提高系统的可用性,则最好配置一种防护方法,该防护方法可保证作为列表中的最后一个防护方法返回成功。请注意,如果您选择不使用实际的防护方法,则仍然必须为此设置配置一些内容,例如“ shell(/ bin / true) ”。
故障切换期间使用的防护方法将配置为一个以回车分隔的列表,该列表将按顺序尝试,直到指示防护成功为止。Hadoop提供了两种方法:shell和sshfence。有关实现自己的自定义fencing方法的信息,请参阅org.apache.hadoop.ha.NodeFencerclass。
sshfence - SSH到活动NameNode并杀死进程
该sshfence选项SSHes到目标节点,并使用定影杀死进程监听服务的TCP端口上。为了使此隔离选项正常工作,它必须能够在不提供密码的情况下通过SSH连接到目标节点。因此,还必须配置dfs.ha.fencing.ssh.private-key-files选项,该选项是SSH私钥文件的以逗号分隔的列表。例如:
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/exampleuser/.ssh/id_rsavalue>
property>或者,可以配置一个非标准的用户名或端口来执行SSH。也可以为SSH配置超时(以毫秒为单位),之后将认为此防护方法失败。它可以这样配置:
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfence([[username][:port]])value>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>shell - 运行一个任意的shell命令来隔离Active NameNode
它可以这样配置:
dfs.ha.fencing.methods
shell(/path/to/my/script.sh arg1 arg2 ...)
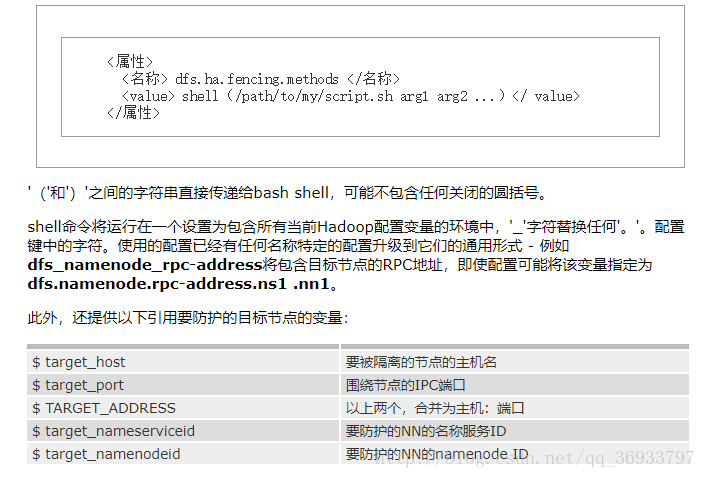
这些环境变量也可以用作shell命令本身的替代。例如:
<property>
<name>dfs.ha.fencing.methodsname>
shell(/path/to/my/script.sh --nameservice=$target_nameserviceid $target_host:$target_port)
property>如果shell命令返回退出码0,则确定防护成功。如果它返回任何其他退出代码,则防护不成功,并尝试列表中的下一个防护方法。
注意:此防护方法不会实现任何超时。如果超时是必要的,它们应该在shell脚本中实现(例如通过派生一个子shell来在几秒内终止它的父代)。
- fs.defaultFS - Hadoop FS客户端在未给出时使用的默认路径前缀
或者,您现在可以将Hadoop客户端的默认路径配置为使用新的启用HA的逻辑URI。如果之前使用“mycluster”作为名称服务标识,则这将是所有HDFS路径的权限部分的值。这可能是这样配置的,在你的core-site.xml文件中:
<property>
<name>fs.defaultFSname>
<value>hdfs://myclustervalue>
property>- dfs.journalnode.edits.dir - JournalNode守护进程将存储其本地状态的路径
这是JournalNode计算机上的绝对路径,JN所使用的编辑和其他本地状态将被存储。您只能使用单个路径进行此配置。通过运行多个单独的JournalNode或通过在本地连接的RAID阵列上配置此目录来提供此数据的冗余。例如:
<property>
<name>dfs.journalnode.edits.dirname>
<value>/path/to/journal/node/local/datavalue>
property>